
安装pytorch版本的faster rcnn实现物体识别
基于GitHub的一个开源项目:https://github.com/jwyang/faster-rcnn.pytorch
环境:Ubuntu 18.04.3、python2.7,显卡NVIDIA GeForce RTX 2070,pytorch0.4.0,CUDA10.1 update2
(尝试过Ubuntu 16.04安装cuda但是一直不成功,使用Ubuntu 18.04.3就非常容易的安装好了,所以建议还是使用最新的操作系统)
由于该项目是2年前的,为了能够顺利测试通过,所以环境都使用了比较旧的python和pytorch版本,不过最近看项目的介绍好像已经支持了pytorch-1.0:
下面我把0.4的版本和1.0版本的地址都贴出来:
pytorch0.4.0版源码:https://github.com/jwyang/faster-rcnn.pytorch.git
pytorch1.0.0版源码:https://github.com/jwyang/faster-rcnn.pytorch/tree/pytorch-1.0
第一步准备好环境:
1.1、 系统环境:Ubuntu 18.04.3:下载地址:https://ubuntu.com/download/server 直接到官网下载,安装过程非常的简单。
1.2、Python 2.7,安装Anaconda,https://blog.csdn.net/lwplwf/article/details/79162470
use qinhua: https://blog.csdn.net/weixin_34296641/article/details/94171967
1.3、CUDA Toolkit 10.1 update2 下载地址:https://developer.nvidia.com/cuda-toolkit-archive
首先我们需要仔细查看一下安装文档:Versioned Online Documentation
第一需要注意的就是对比所有的安装要求,确保ubantu系统内核还有gcc的版本和cuda要求的版本一致,否则会安装不上:
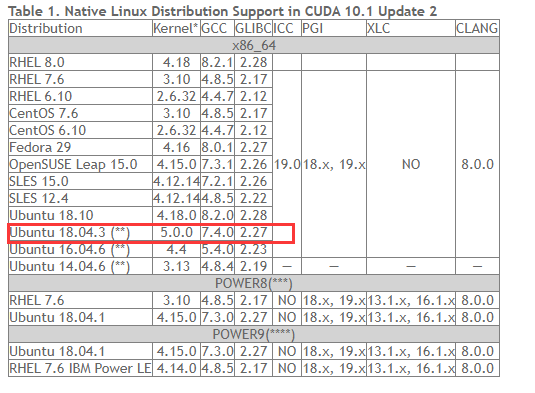
先查看gcc的版本,:
gcc --version

我下载安装的ubantu18.04.3的gcc版本是7.4.0的,正好符合cuda安装要求,如果提示没有安装gcc,可以通过apt-get进行安装:
sudo apt-get install gcc
再确认您的系统内核版本:
uname -r

我的是5.0.0所以也是符合cuda安装要求的,这个非常重要,要省下很多事情,之前我用unbantu16.04就是卡在这里。哪怕把内核修改成了cuda要求的都还是安装不成功。所以选对操作系统非常重要。
接下来就是要安装显卡驱动,虽然cuda的.run方式安装会自带显卡驱动,但是失败率高。建议直接使用ubantu系统自带安装显卡驱动功能进行安装:
ubuntu-drivers devices
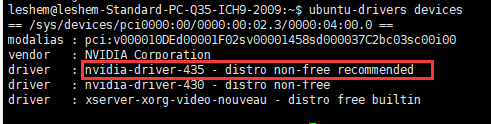
查看可以安装的版本,红框里面的是系统推荐我安装的版本。
但是我运行的命令是自动安装:
#自动安装合适显卡驱动
sudo ubuntu-drivers autoinstall
安装完成之后,请重启操作系统。
输入命令,查看显卡情况:
nvidia-smi
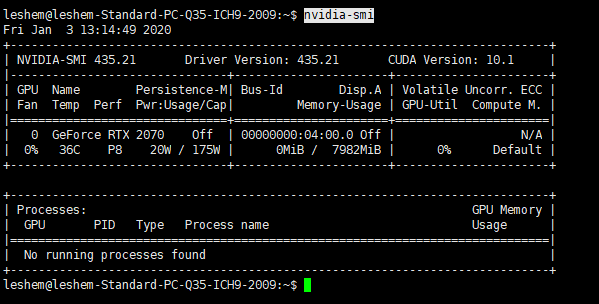
接下来就是下载和安装cuda:
//下载cuda
wget http://developer.download.nvidia.com/compute/cuda/10.1/Prod/local_installers/cuda_10.1.243_418.87.00_linux.run
//执行安装
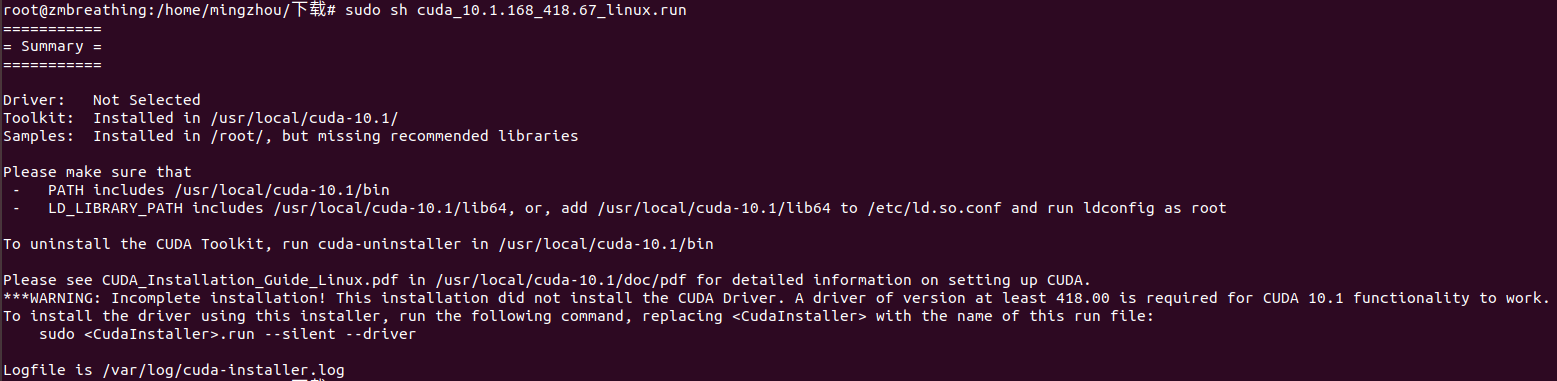
sudo sh cuda_10.1.243_418.87.00_linux.run
我之前已经安装了Nvidia的显卡驱动,这里不安装driver
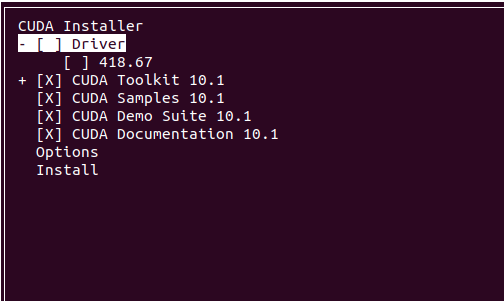
接下来cuda就会自动安装成功。
添加环境变量
vi ~/.bashrc
在文件末尾添加
export PATH="/usr/local/cuda-10.1/bin:$PATH"
export LD_LIBRARY_PATH="/usr/lcoal/cuda-10.1/lib64:$LD_LIBRARY_PATH"
最后使其生效
source ~/.bashrc
最好测试cuda是否安装成功:
终端输入
cd /usr/local/cuda-10.1/samples/1_Utilities/deviceQuery
sudo make
./deviceQuery
结果如图
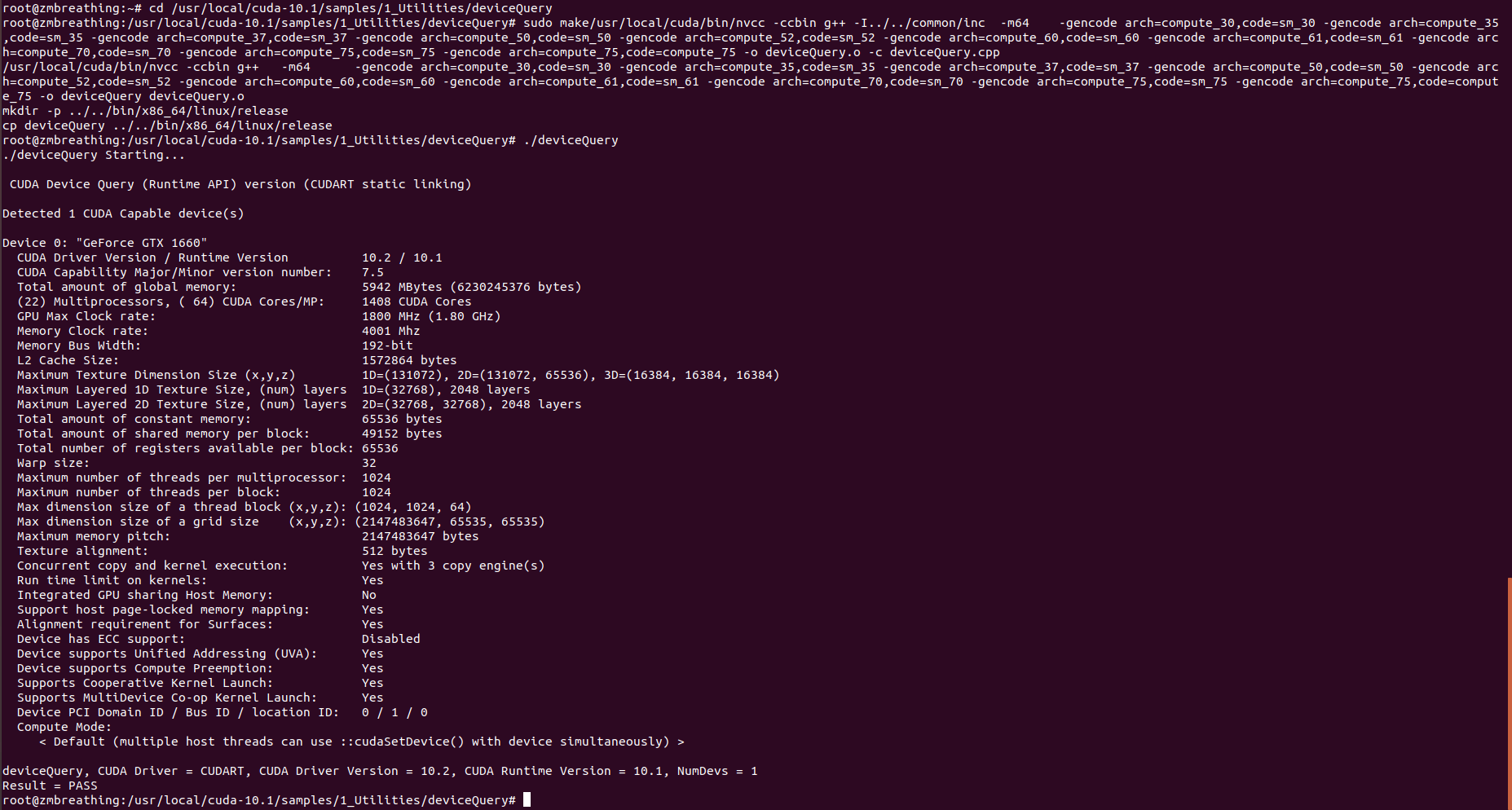
出现Result = PASS则表示安装成功通过
Pytorch 安装:conda install pytorch=0.4.0 -c soumith
二、用voc2007标准数据集训练模型
1、训练模型
2.1.1 到github下载源码:https://github.com/jwyang/faster-rcnn.pytorch,放到指定的目录下
2.1.2 在代码所在目录打开终端,手动创建data文件夹或者用命令行创建:mkdir data
2.1.3 安装模型所需依赖(第三方包),命令行输入即可自动安装所需依赖:pip install -r requirements.txt
if use conda to install,You must change the requirements.txt content like this:
cython cffi opencv3 scipy msgpack-python easydict matplotlib pyyaml tensorboardX
2.1.4 进入lib目录下,编译NMS, ROI_Pooling, ROI_Align和ROI_Crop模块,命令行输入:
cd lib
python setup.py build develop
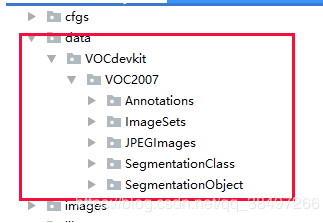
2.1.5 下载voc2007数据集,下载链接:
http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCdevkit_08-Jun-2007.tar
将:VOCtrainval_06-Nov-2007 目录下的VOCdevkit文件夹,复制到./data目录下 ,目录结构如下:
下载预训练好的vgg16模型,并在data数据集上面新建一个pretrained_model文件夹,将与训练模型放到里面
训练模型:基于vgg16模型训练网络,在项目根目录下输入下列命令就会开始训练模型,python trainval_net.py表示执行trainval_net.py代码进行训练,后面的都是指定的参数,若不指定,将会选择默认选项
CUDA_VISIBLE_DEVICES=$GPU_ID python trainval_net.py \ --dataset pascal_voc --net vgg16 \ --bs 1 --nw 4 \ --lr 0.00001 \ --cuda
其中
“CUDA_VISIBLE_DEVICES”指代了gpu的id,–dataset”指代你跑得数据集名称,我们就以pascal-voc为例;“–net”指代你的backbone网络是啥,我们以vgg16为例;"–bs"指的batch size;“–nw”指的是worker number;"--lr"指代学习率,“–cuda”指的是使用gpu。
在训练过程中可能出现的错误:
1、Path does not exist: ×××/data/VOCdevkit2007/VOC2007/ImageSets/Main/trainval.txt
分析:路径中不存在VOCdevkit2007一个文件夹
解决方法:.\lib\datasets\pascal_voc.py文件下116行的
return os.path.join(cfg.DATA_DIR, 'VOCdevkit' + self._year)
修改为
return os.path.join(cfg.DATA_DIR, 'VOCdevkit')
2、AttributeError: 'int' object has no attribute 'astype'
解决方法:/lib/roi_data_layer/roibatchLoader.py
line 52, target_ratio = 1 change to:
target_ratio = np.array(1)
3、RuntimeError: cuda runtime error (2) : out of memory at /pytorch/aten/src/THC/generic/THCStorage.cu:58
解决方法:跑代码需要的内存超出当前指定的GPU的可用内存,需要重新指定,(我在训练模型时不指定GPU的ID,即不用输入CUDA_VISIBLE_DEVICES=$GPU_ID,错误消除)
最终在控制台输入以下命令开始训练模型,
python trainval_net.py --dataset pascal_voc --net vgg16 --bs 1 --nw 4 --cuda
训练过程中模型默认保存地址为./model/vgg16/pascal_voc路径下(trainval_net.py中变量sava_name的值为模型保存的路径)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号