使用TensorRT-LLM部署ChatGLM3
说明:
TensorRT-LLM是NVIDIA开发的高性能推理
显卡:A100(8张)
1、TensorRT-LLM 代码需要使用 git-lfs 拉取所以下载git git-lfs
apt-get update && apt-get -y install git git-lfs
2、clone项目
git clone https://github.com/NVIDIA/TensorRT-LLM.git
cd TensorRT-LLM
3、使用 v0.7.0 Release 版本
git checkout tags/v0.7.0 -b release/0.7.0
git submodule update --init --recursive
git lfs install
git lfs pull
4、构建docker镜像并安装TensorRT-LLM
cd TensorRT-LLM/docker
(注意切换路径 这里是相对路径 如果和我的路径不一样记得切换)
make release_build
(大约需要1个小时)
或者按照官方的操作来
cd TensorRT-LLM/
make -C docker release_build
5、运行docker镜像
make release_run
或者按官方的操作来
cd TensorRT-LLM/
make -C docker release_run
运行后会看到起来的容器

但是这个容器有可能会登录进去后 退出后出现容器丢失的情况 因此修改Makefile文件
cd TensorRT-LLM/docker
vim Makefile
找到DOCKER_RUN_OPTS这一行
原先的配置为:
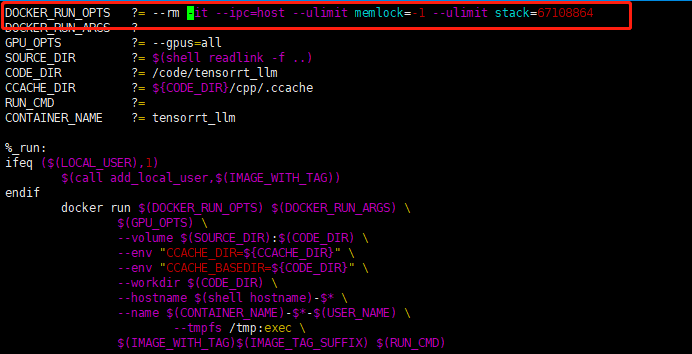
把--rm删掉,再后面的--it加一个d
如图:
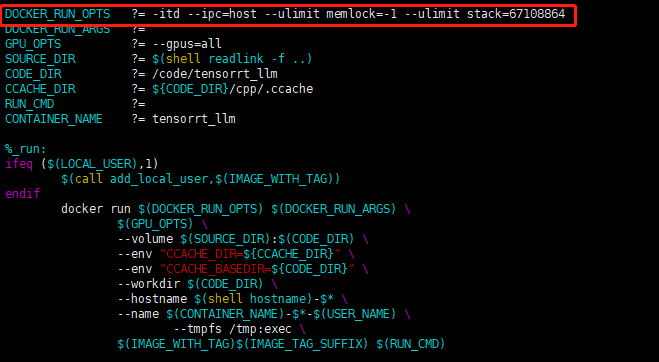
保存退出
返回上一层目录
cd ..
再次开始构建创建
make -C docker release_build
make -C docker release_run
6、进入容器安装依赖
docker exec -it ec /bin/bash
cd ./examples/chatglm
pip install -r requirements.txt
apt-get update
apt-get install git-lfs
7、下载模型
git clone https://huggingface.co/THUDM/chatglm3-6b chatglm3_6b
git clone https://huggingface.co/THUDM/chatglm3-6b-base chatglm3_6b_base
git clone https://huggingface.co/THUDM/chatglm3-6b-32k chatglm3_6b_32k
先下载第一个模型测试 因为我在docker里下载超时 所以先下载到本地在上传至docker里
网址为:https://huggingface.co/THUDM/chatglm3-6b/tree/main
将里面的全部下载
注意我没有截全
全部下载后进入容器
cd /code/tensorrt_llm/examples/chatglm
新建文件夹
mkdir chatglm3_6b
然后退出容器
把下载的文件都上至到这个路径下/code/tensorrt_llm/examples/chatglm/chatglm3_6b
上传完后 在进入容器
进入目录
cd /code/tensorrt_llm/examples/chatglm
9、执行代码测试
9.1单机单卡例子:
构建一个默认的精度为fp16的引擎
python3 build.py -m chatglm3_6b --output_dir trt_engines/chatglm3_6b/fp16/1-gpu
python3 ../run.py --input_text "秦皇岛周末限号吗" \
--max_output_len 1024 \
--tokenizer_dir chatglm3_6b \
--engine_dir trt_engines/chatglm3_6b/fp16/1-gpu
可以把 "秦皇岛周末限号吗" 换成自己的内容
结果如图:

9.2单机多卡例子:
9.2.1构建一个使用4卡的模型
python3 build.py -m chatglm3_6b --world_size 4 --tp_size 4 --pp_size 1 --output_dir trt_engines/chatglm3_6b/fp16/4-gpu
如果是6卡 需要将--world_size 4和 --tp_size 4换成6
构建完成后在/code/tensorrt_llm/examples/chatglm/trt_engines/chatglm3_6b/fp16路径下会看到一个4-gpu的文件夹

9.2.2运行测试
cd /code/tensorrt_llm/examples/chatglm
mpirun -n 4 --allow-run-as-root \
python ../run.py --input_text "What's new between ChatGLM3-6B and ChatGLM2-6B?" \
--max_output_len 50 \
--tokenizer_dir chatglm3_6b \
--engine_dir trt_engines/chatglm3_6b/fp16/4-gpu
如图:

后续功能待完善...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号