python让繁琐工作自动化 第12章 web页面抓取
1.requests 模块抓取页面
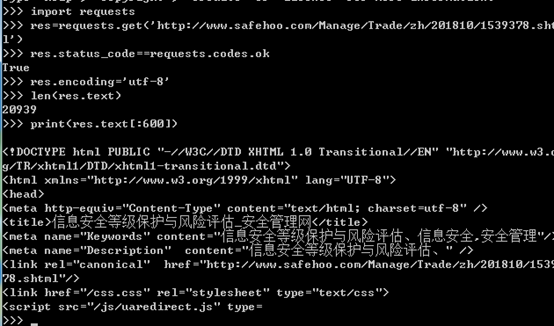
requests.get() //下载一个网页
status_code 通过检查response对象的status_code属性,了解页面是否请求成功,若等于requests.code.ok,表明状态码为200,下载成功
若请求成功,页面将作为字符串,保存在response对象的text变量中
转码
2.检查页面错误:raise_for_status()

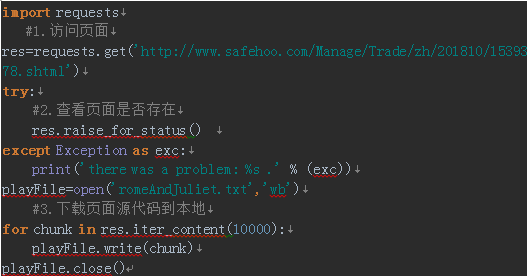
import requests
res=requests.get('https://www.cnblogs.com/nieliangcai/p/1.html')
try:
res.raise_for_status()
except Exception as exc:
print('there was a problem: %s .' % (exc))

3.将请求的页面内容保存到本地
必须用’wb’写二进制模式打开文件,即使页面是纯文本,也需要写入二进制数据,目的是为了保存该文本中的’unicode编码’
Iter_content() 方法在循环的每次迭代中,返回一段内容,每一段为bytes数据,需指定一段包含多少字节,通常是10万
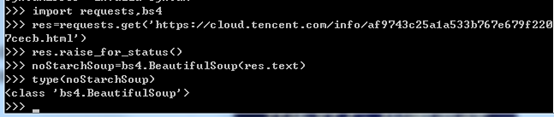
4.html创建一个beautifulsoup对象
从本地向beautifulsoup传递一个file对象,加载本地的html文件
import bs4
example=open('example.html')
exampleSoup=bs4.BeautifulSoup(example)
print(type(exampleSoup))
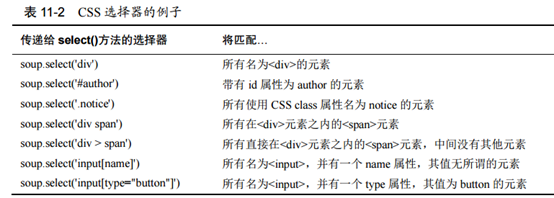
4.用select元素寻找元素
import bs4
example=open('example.html')
exampleSoup=bs4.BeautifulSoup(example.read())
elems=exampleSoup.select('#author') #返回一个列表
print(type(elems))
print(len(elems)) #只有一个tag对象
print(type(elems[0]))
print(elems[0].getText()) #getText 返回元素的文本 ,访问开始和结束之间标签的文本
print(str(elems[0])) #将元素传递给str() 返回一个字符串,包括开始和结束标签,以及该元素的文本
print(elems[0].attrs) #attrs返回字典,包括id属性,及id属性的值
------------------------------------------------------------
import bs4
example=open('example.html')
exampleSoup=bs4.BeautifulSoup(example)
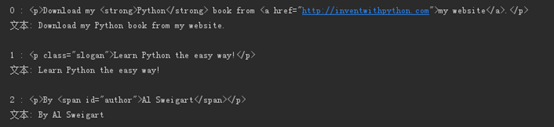
pElems=exampleSoup.select('p')
print(len(pElems))
for i in range(len(pElems)):
print(str(i)+' : '+str(pElems[i]))
print('文本: '+pElems[i].getText())
print()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号