作业 4:词频统计——基本功能
一、基本信息
本次作业的地址:https://edu.cnblogs.com/campus/ntu/Embedded_Application/homework/2088
项目Git地址:https://gitee.com/ntucs/PairProg.git
结对成员:王立凯 1613072048
张天弈 1613072049
二、项目分析
Task1 基本任务
实现一个控制台程序,在给定一个英文字符串文件,统计其中各个英文单词出现的频率。
1.程序运行模块(方法、函数)介绍:
(1)统计文件中的有效行数,存放在lines中
1 file = open(dst, 'r') # dst为文本的目录路径 2 lines = len(file.readlines())
(2)统计文件中的单词总数
1 def process_buffer(bvffer): # 处理缓冲区,返回存放每个单词频率的字典WordCount,单词总数 2 if bvffer: 3 WordCount = {} 4 # 将文本内容都小写 5 bvffer = bvffer.lower() 6 # 用空格消除文本中标点符号 7 words = bvffer.replace(punctuation, ' ').split(' ') 8 # 正则匹配 9 regex_word = "^[a-z]{4}(\w)*" 10 for word in words: 11 if re.match(regex_word, word): 12 # 数据字典已经存在该单词,数量+1 13 if word in WordCount.keys(): 14 WordCount[word] = WordCount[word] + 1 15 # 不存在,把单词存入字典,数量置为1 16 else: 17 WordCount[word] = 1 18 return WordCount, len(words)
(3)统计文件中各单词出现的次数,输出频率最高的十个。
1 def output_result(WordCount): # 按照单词的频数排序,返回前十的单词组 2 if WordCount: 3 sorted_WordCount = sorted(WordCount.items(), key=lambda v: v[1], reverse=True) 4 for item in sorted_WordCount[:10]: # 输出 Top 10 的单词 5 print('<' + str(item[0]) + '>:' + str(item[1])) 6 return sorted_WordCount[:10]
(4)将结果输出到文件result.txt。
1 def save_result(lines, words, items): # 保存结果到文件(result.txt) 2 try: 3 result = open("result.txt", "w") # 以写模式打开,并清空文件内容 4 except Exception as e: 5 result = open("result.txt", "x") # 文件不存在,创建文件并打开 6 # 写入文件result.txt 7 result.write("lines:" + lines + "\n") 8 result.write("words:" + words + "\n") 9 for item in items: 10 item = '<' + str(item[0]) + '>:' + str(item[1]) + '\n' 11 result.write(item) 12 print('写入result.txt已完成') 13 result.close()
2.程序算法的时间、空间复杂度分析
时间复杂度:本程序中所有的循环都是单层循环且每一层循环执行的次数都是常量有限次,因此函数循环部分的时间复杂度为O(n)。
而python程序中sort函数的时间复杂度为O( n*log2(n) ),因此程序的时间复杂度为O( n*log2(n) )
空间复杂度:sort函数的空间复杂度是O( n*log2(n) ),for循环的空间复杂度是O(n),因此程序的空间复杂度是O(n*log2(n))
3.程序运行案例截图
(1)编写完成WordCount.py,在DOS窗口执行python WordCount.py Gone_with_the_wind.txt
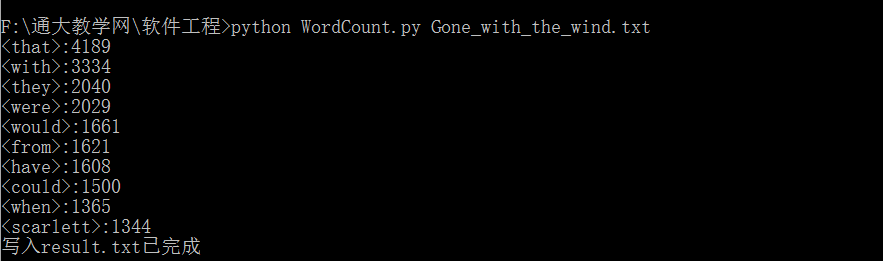
(2)结果保存在result.txt文件中

Task2 任务进阶
1.程序介绍
(1)支持 stop words,输出时跳过停词表中的单词
1 # 停词表模块 2 txtWords = open("stopwords.txt", 'r').readlines() # 读取停词表文件 3 stopWords = [] # 存放停词表的list 4 # 读取文本是readlines所以写入list要将换行符取代 5 for i in range(len(txtWords)): 6 txtWords[i] = txtWords[i].replace('\n', '') 7 stopWords.append(txtWords[i]) 8 for word in words: 9 if word not in stopWords: # 当单词不在停词表中时,使用正则表达式匹配 10 if re.match(regex_word, word): 11 # 数据字典已经存在该单词,数量+1 12 if word in word_freq.keys(): 13 word_freq[word] = word_freq[word] + 1 14 # 不存在,把单词存入字典,数量置为1 15 else: 16 word_freq[word] = 1
2.算法的时间、空间复杂度分析
时间复杂度:本模块中所有的循环都是单层循环且每一层循环执行的次数都是常量有限次,因此函数循环部分的时间复杂度为O(n)。
空间复杂度:for循环的空间复杂度是O(n),因此该段程序的空间复杂度是O(n)。
3.程序运行案例截图
停词表中单词:

使用停词表后程序运行结果:

三、性能分析
Task1
1.使用cProfile进行性能分析
1 python -m cProfile WordCount.py Gone_with_the_wind.txt | grep WordCount.py

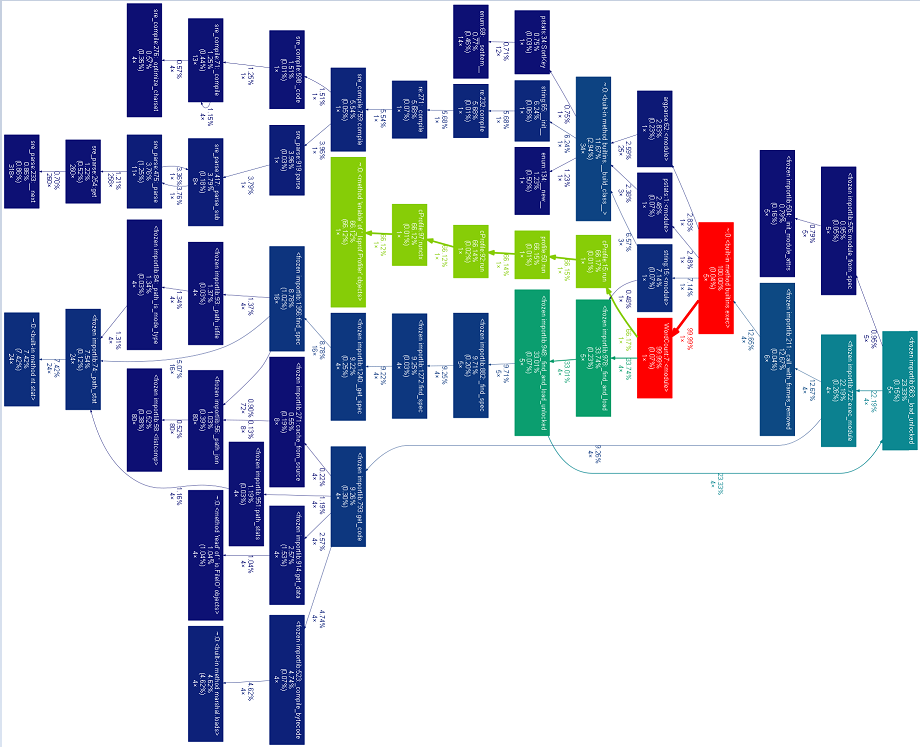
2.可视化操作
1 F:\通大教学网\软件工程>python -m cProfile -o result.out -s cumulative WordCount.py Gone_with_the_wind.txt 2 F:\通大教学网\软件工程>python gprof2dot.py -f pstats result.out | dot -Tpng -o result.png
转换得到图如下:
Task2
1.使用cProfile进行性能分析

2.可视化操作
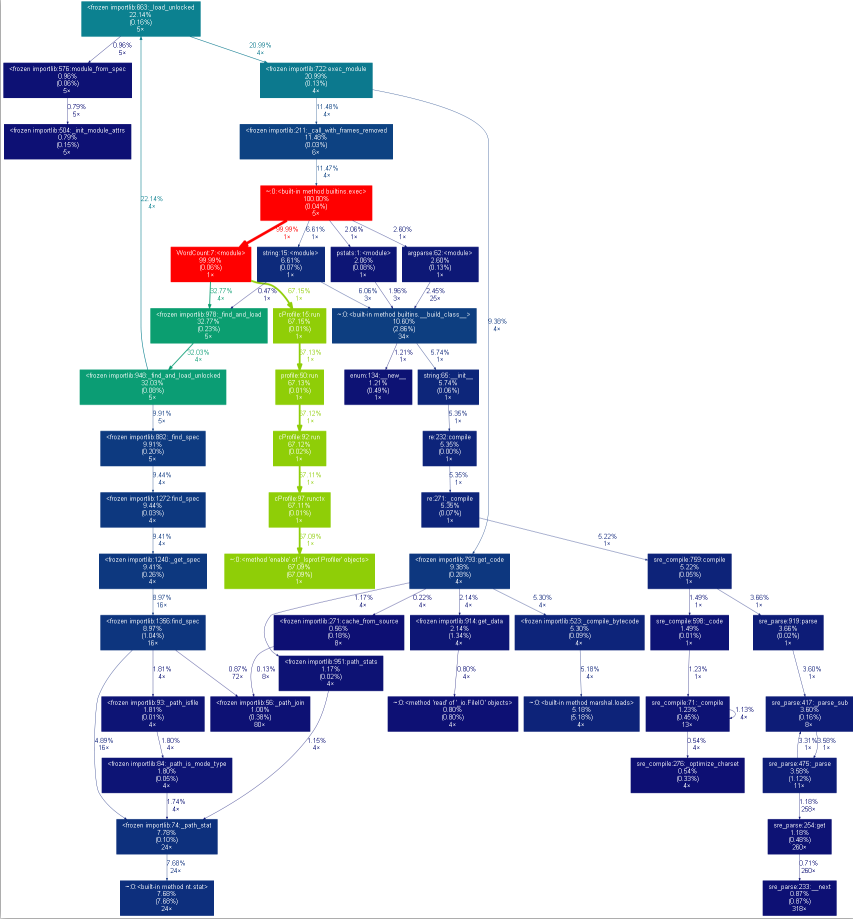
四、其他
结对编程时间开销:用了两天的时间摸索、分析和改进代码,一天的时间写博客,具体花费时间大约为13个小时。
结对编程照片:

五、事后分析总结
1.针对正则表达式的讨论过程
一开始我们并不知道规范化并限定单词是可以用公式来解决,我们用了len(word)>3等方法的结合来达到目的,花了很多
时间而且并没有达到很好的效果。后来我们参考了已完成的程序代码才明白如何优化我们的算法。
2.评价对方
王立凯评价张天翼 :张天翼虽然基础比较薄弱,对python的学习和掌握速度也不是很快,但他做事情比较积极,在结对编程
的过程中无论遇到什么样的问题也从来不会急躁并能坚持下去。
张天弈评价王立凯:我的搭档在写程序时积极主动、善于研究,他教会了我许多在我不会写的代码。他还有自己的想法,在
写代码方面积极思考,乐于助人,期待与他的下一次合作。
3.评价整个过程
(1)建议以后需要合作的作业可以有明确的分工,做好各自的任务后再对接。
(2)如果以后还有需要合作的作业的话建议自由组队,因为跟平时经常讨论问题的人合作会更加有默契。
4.其他
在做这份作业之前需要有系统的理论知识和扎实的基础,否则每遇到一个问题就学习一个新知识,这样会很浪费时间,
希望老师可以在作业的开头写下需要用到的知识范围,我们在初步学习之后再开始写作业。


