序列化是将对象转化为字节流的方法,序列化目的有:
1> 进程间通信;
2> 数据持久性存储。
RPC(Remote Procedure Call Protocol)——远程过程调用协议,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。RPC协议假定某些传输协议的存在,如TCP或UDP,为通信程序之间携带信息数据。在OSI网络通信模型中,RPC跨越了传输层和应用层。RPC使得开发包括网络分布式多程序在内的应用程序更加容易。
Hadoop采用RPC来实现进程间的通信。Generally,RPC的序列化机制有以下特点:
1> 紧凑:紧凑的格式可以利用带宽,加快传输速度;
2> 快速:能减少序列化和反序列化的开销,这会有效减少进程间通信的时间;
3> 可扩展:可以逐步改变,是Client与Server端直接相关的。例如,可以随时加入一个新的参数方法调用;
4> 互操作性:支持不同语言编写的Client和Server端交换Data。
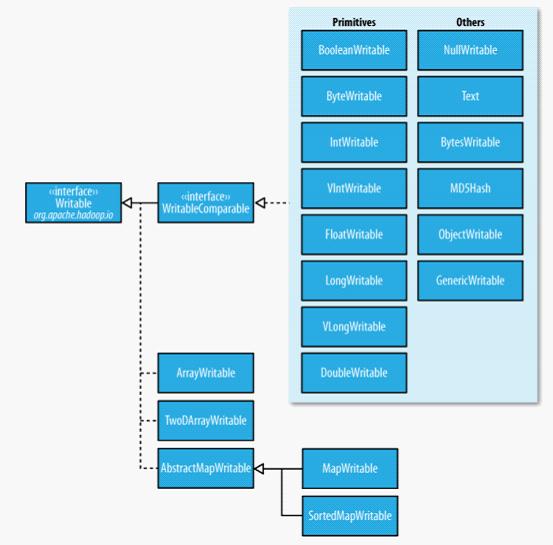
在Hadoop中,序列化处于核心地位。因为无论是存储文件还是在计算中传输数据,都需要执行序列化的过程。序列化与反序列化的速度,序列化后的data大小等都会影响数据传输的速度,以致影响计算的效率。Hadoop并没有采用Java的序列化机制,而是重新写了一个序列化机制Writable(具有紧凑、快速但不易扩展,亦不利于不同语言的互操作),并允许对自己定义的类加入序列化与反序列化方法. 当要在进程间传递对象或持久化对象的时候,就需要序列化对象成字节流,反之当要将接收到或从磁盘读取的字节流转换为对象,就要进行反序列化。Writable是Hadoop的序列化格式,Hadoop定义了这样一个Writable接口。
public interface Writable {
// Serialize the fields of this object to out.
// @param(out) DataOuput (to serialize this object into). @throws IOException
void write(DataOutput out) throws IOException;
// Deserialize the fields of this object from in. For efficiency, implementations should attempt to re-use storage in the existing object where possible.
// @param(in) DataInput (to deseriablize this object from). @throws IOException
void readFields(DataInput in) throws IOException;
}
Writable是Hadoop的核心,Hadoop通过它定义了Hadoop中基本的数据类型及其操作。Generally,无论是上传下载data还是运行MapReduce程序,都需使用Writable类。
//WritableComparable can be compared to each other, typically via Comparator. Any type which is to be used as a key in the Hadoop Map-Reduce framework should implement this interface.
public interface WritableComparable<T> extends Writable, Comparable<T> { }
看看一个WritableComparable的具体实例:
/** A WritableComparable for ints. */
public class IntWritable implements WritableComparable {
private int value;
public IntWritable() {}
public IntWritable(int value) { set(value); }
/** Set the value of this IntWritable. */
public void set(int value) { this.value = value; }
/** Return the value of this IntWritable. */
public int get() { return value; }
public void readFields(DataInput in) throws IOException { value = in.readInt(); }
public void write(DataOutput out) throws IOException { out.writeInt(value); }
/** Returns true if o is a IntWritable with the same value. */
public boolean equals(Object o) {
if (!(o instanceof IntWritable))
{ return false; }
IntWritable other = (IntWritable)o;
return this.value == other.value;
}
public int hashCode() { return value; }
/** Compares two IntWritables. */
public int compareTo(Object o) {
int thisValue = this.value;
int thatValue = ((IntWritable)o).value;
return (thisValue<thatValue ? -1 : (thisValue==thatValue ? 0 : 1));
}
public String toString() { return Integer.toString(value); }
/** A Comparator optimized for IntWritable. */
public static class Comparator extends WritableComparator {
public Comparator() { super(IntWritable.class); }
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
int thisValue = readInt(b1, s1);
int thatValue = readInt(b2, s2);
return (thisValue<thatValue ? -1 : (thisValue==thatValue ? 0 : 1));
}
}
// register this comparator
static { WritableComparator.define(IntWritable.class, new Comparator()); }
}
代码中的static块调用WritableComparator的static方法define()用来注册上面这个Comparator,就是将其加入WritableComparator的comparators成员中,comparators是HashMap类型且是static的。这样,就告诉WritableComparator,当我使用WritableComparator.get(IntWritable.class)方法的时候,你返回我注册的这个Comparator给我【对IntWritable来说就是IntWritable.Comparator】,然后我就可以使用comparator.compare(byte[] b1, int s1, int l1,byte[] b2, int s2, int l2)来比较b1和b2,而不需要将它们反序列化成对象。comparator.compare(byte[] b1, int s1, int l1,byte[] b2, int s2, int l2)中的readInt()是从WritableComparator继承来的,它将IntWritable的value从byte数组中通过移位转换出来。
相关调用如下:
//params byte[] b1, byte[] b2 RawComparator<IntWritable>comparator = WritableComparator.get(IntWritable.class); comparator.compare(b1,0,b1.length,b2,0,b2.length);
注意,当comparators中没有注册要比较的类的Comparator,则会返回一个默认的Comparator,然后使用这个默认Comparator的compare(byte[] b1, int s1, int l1,byte[] b2, int s2, int l2)方法比较b1、b2的时候还是要序列化成对象的,详见后面细讲WritableComparator。
另外关于WritableComparator类定义如下(上面用到过):
1 public class WritableComparator implements RawComparator { 2 3 private static HashMap<Class, WritableComparator> comparators = 4 new HashMap<Class, WritableComparator>(); // registry 5 6 /** Get a comparator for a {@link WritableComparable} implementation. */ 7 public static synchronized WritableComparator get(Class<? extends WritableComparable> c) { 8 WritableComparator comparator = comparators.get(c); 9 if (comparator == null) 10 comparator = new WritableComparator(c, true); 11 return comparator; 12 } 13 14 /** Register an optimized comparator for a {@link WritableComparable} 15 * implementation. */ 16 public static synchronized void define(Class c, 17 WritableComparator comparator) { 18 comparators.put(c, comparator); 19 } 20 ....... 21 }