20200806作业
1、MySQL中字段类型char、varchar的区别
相同处:
1、都是非 Unicode 的字符数据
2、n 必须是一个介于 1 和 8000 之间的数值
不同处:
char(n):
1)长度为 n 个字节的固定长度,当输入的长度小于n时,缺少的会自动由空格补齐且空格自动隐藏
2)存储大小为 n 个字节
3)存储效率比varchar高
varchar(n):
1)长度为 n 个字节的可变长度,当输入的长度小于n时,长度会自动变更为n
2)实际存储长度为n+1,1用来存储实际占用长度
3)比char省存储空间
2、请建立一张表judge_varchar_char
表名为judge_varchar_char
分别字段为varchar_info varchar(5), char_info char(5),int_info int(2)
其中要求 int_info 字段 增加 usigned zerofill 属性
1 create table judge_varchar_char( 2 varchar_info varchar(5), 3 char_info char(5), 4 int_info int(2) unsigned zerofill)
usigned:将数字类型无符号化。INT的类型范围-2 147 483 648~2 147 483 647;INT UNSIGNED范围0~4 294 967 295
可能会导致运算后的负值无法显示,可用SET SQL_Mode='NO_UNSIGNED_SUBTRACTION'解决
zerofill:如果宽度小于设定的值则自动填充0
3、请插入数据
问:在judge_varchar_char表中,插入('200000','300000',1)的数据,会出现什么情况,为什么
答:显示错误 -- Data too long for column 'varchar_info' at row 1
预设varchar最大长度为5,实际输入长度超过5
4、请插入带空格数据
在judge_varchar_char表中,插入('ab ','ab ',2)的数据(注意ab后面有2个空格),分别求该varchar_info、char_info的字符长度和字节长度。
1 -- 计算字符个数 2 SELECT LENGTH(varchar_info),LENGTH(char_info) 3 FROM judge_varchar_char

5、如何用题4的数据,证明char与varchar的区别?
当数据中出现空格时varchar会保留,而char会自动删去
6、创表时的int(5),5代表什么?与varchar(5)的5有什么区别?
varchar(5):5代表数据宽度
int(5):5仅在与zerofill连用时生效
7、请一次语句中插入2条数据
('cd ','cd ',1)、('cd ','cd ',123456)
1 insert into judge_varchar_char 2 values('cd ','cd ',1),('cd ','cd ',123456)
8、这两个数据有什么不同,为什么?
varchar_info保留了cd后方的空格
pandas基础
1、请利用多种方式将截图内容转成DataFrame。
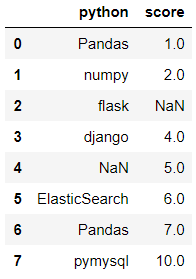
1)字典形式转化为dataframe
1 import pandas as pd 2 import numpy as np 3 d={ 4 'python':['Pandas','numpy','flask','django',np.nan,'ElasticSearch','Pandas','pymysql'], 5 'score':[1.0,2.0,np.nan,4.0,5.0,6.0,7.0,10.0] 6 } 7 df=pd.DataFrame(d)
2)直接创建dataframe
1 import pandas as pd 2 import numpy as np 3 df1=pd.DataFrame([['Pandas',1.0],['numpy',2.0],['flask',np,nan],['django',4.0],[np.nan,5.0],['ElasticSearch',6.0],['Pandas',7.0],['pymysql',10.0]],columns=['python','score'])
NAN:空值应使用np.nan否则无法使用fillna
2、提取含有字符串“Pandas”的行
1 df[df['python']=='Pandas']
3、输出df的所有列名
1 df.columns
4、修改第二列列名为‘popularity’
1 df.rename(columns={'score':'popularity'},inplace=True)
5、统计python列中每种模块包出现的次数
1 df.python.value_counts()
6、将空值用上下值的平均值填充
1 df['popularity'] = df['popularity'].fillna(df['popularity'].interpolate())

 浙公网安备 33010602011771号
浙公网安备 33010602011771号