获取中央气象台网的气象数据 全流程技术解析(python 爬虫)
一、Python环境搭建
下载安装python
https://www.python.org/downloads/
下载安装PyCharm,Community版即可
https://www.jetbrains.com/pycharm/download/#section=windows
理论上应该先安装python再安装IDE(PyCharm),必要时按网上要求进行环境变量设置。
二、爬虫背景知识
1.网页结构简介
网页一般由三部分组成:HTML(超文本标记语言)、CSS(层叠样式表)和JScript(活动脚本语言)。
其中,HTML相当于网页的结构框架,查看网页源代码时,可见大量成对出现的HTML标签“<>”,如下所示:
<html>..</html> 表示标记中间的元素是网页 <body>..</body> 表示用户可见的内容 <div>..</div> 表示框架 <p>..</p> 表示段落 <li>..</li>表示列表 <img>..</img>表示图片 <h1>..</h1>表示标题 <a href="">..</a>表示超链接
CSS定义元素外观及修饰效果,JScript负责实现交互功能及特效。
2. 爬虫合法性

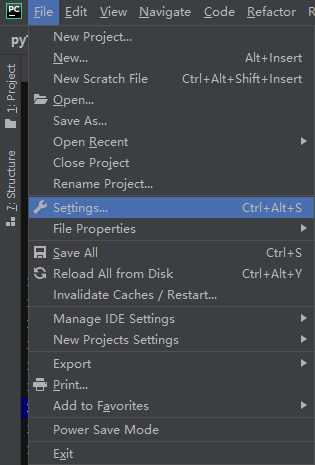
选择“Project Interpreter”(项目编译器)命令,确认当前选择的编译器,然后单击右上角的加号
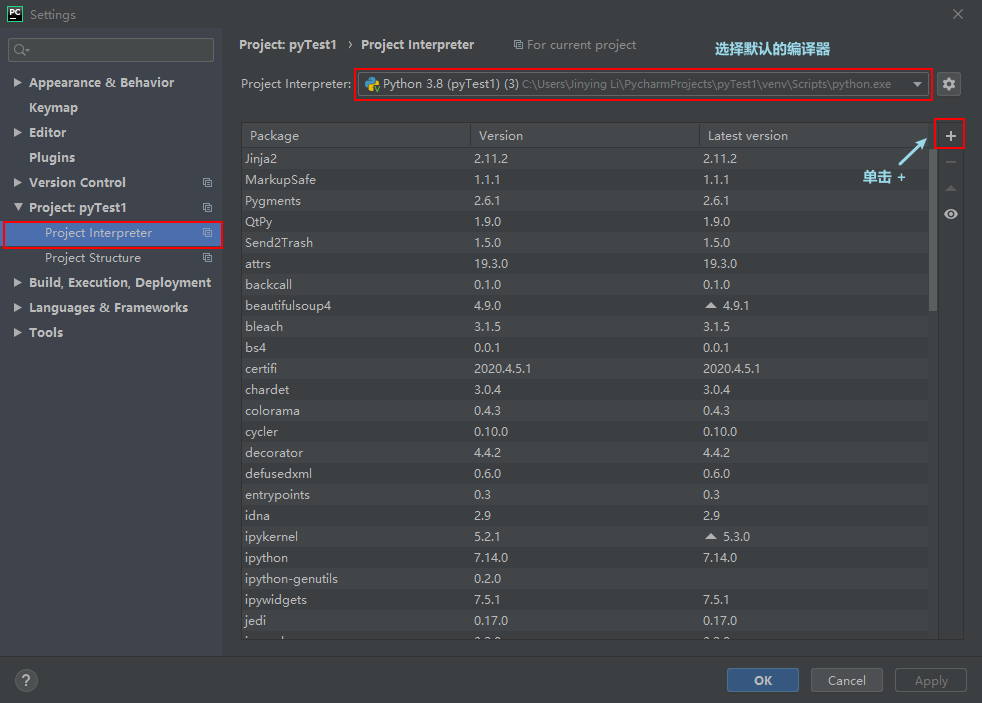
以requests为例,其他与之相同。在搜索框输入:requests(一定要输入完整),然后单击左下角的“Install Package”
安装完成后,会在 Install Package 上显示“Package‘requests’ installed successfully”
2. 代码分析
以顺德区为例,进入中国气象台网:http://www.nmc.cn/publish/forecast/AGD/shunde.html,在5月21日11:00降水量(2.8mm)处单击右键 > 检查
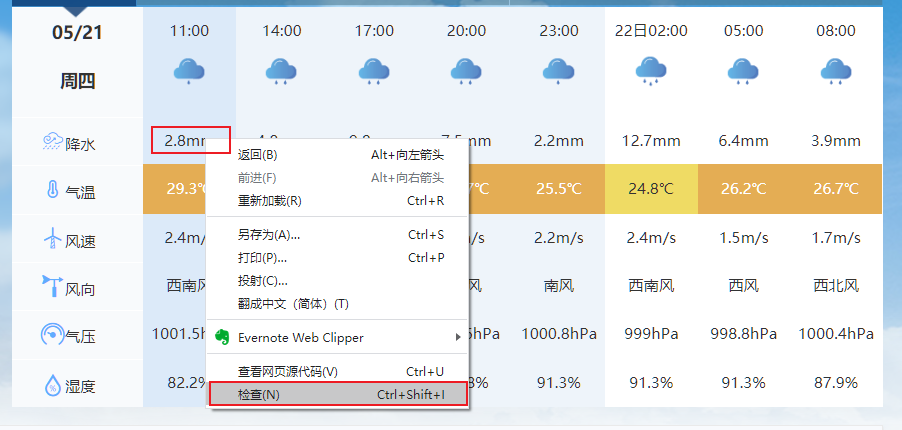
此时会显示出开发者见面,高亮处标示元素即为检查元素(2.8mm),对其右键 > Copy > Copy selector
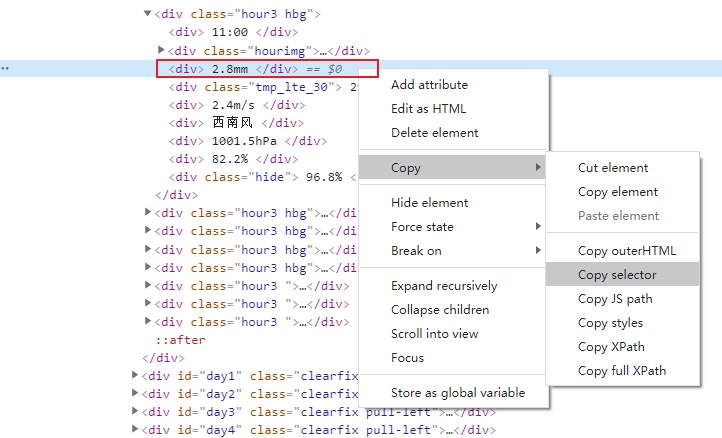
复制内容如下:
#day0 > div:nth-child(1) > div:nth-child(3)
使用 soup.select 引用这个路径,代码如下:
1 import requests # 加载 requests 库,用于网页获取 2 from bs4 import BeautifulSoup # 加载 BeautifulSoup 库,用于解析获取的网页 3 4 url = 'http://www.nmc.cn/publish/forecast/AGD/shunde.html' # 中央气象台网顺德区预报网页 5 strHtml = requests.get(url) 6 strHtml.encoding = strHtml.apparent_encoding # 指定源网页编码方式作为文字解码方式 7 soup = BeautifulSoup(strHtml.text, 'lxml') 8 data = soup.select('#day0 > div:nth-child(1) > div:nth-child(3)') # 将 Copy selector 代码粘贴在(‘’)内 9 print(data)
运行脚本,可见上述元素已经获取。

至此,已经获得了一段目标元素的 HTML 代码,但还没有把数据提取出来。可以观察所获取的HTML代码结构,对获取的内容进行清洗。若获取的HTML片段如行1所示,可以使用get_text()方法获取字段”2.8mm“,若HTML片段如行2所示,可通过contents[0]方法获取字段“05/21”。
1 [<div> 2.8mm </div>] data[0].get_text() 2 [<div class="date"> 05/21 <br/>周四 </div>] data[0].contents[0]
相对完整的代码案例如下:
1 import requests # 加载 requests 库,用于网页获取 2 from bs4 import BeautifulSoup # 加载 BeautifulSoup 库,用于解析获取的网页 3 import csv # csv 库(python 内置),用于读写csv文件 4 5 url = 'http://www.nmc.cn/publish/forecast/AGD/shunde.html' # 中央气象台网顺德区预报网页 6 strHtml = requests.get(url) 7 strHtml.encoding = strHtml.apparent_encoding # 指定源网页编码方式作为文字解码方式 8 soup = BeautifulSoup(strHtml.text, 'lxml') 9 Dict = {} 10 listDate = [] 11 for i in range(1, 8): 12 d_date = soup.select('#day7 > div:nth-child(' + str(i) + ') > div > div:nth-child(1)') # 日期 13 d_desc = soup.select('#day7 > div:nth-child(' + str(i) + ') > div > div:nth-child(3)') # 日间天气 14 d_windd = soup.select('#day7 > div:nth-child(' + str(i) + ') > div > div:nth-child(4)') # 日间风向 15 d_winds = soup.select('#day7 > div:nth-child(' + str(i) + ') > div > div:nth-child(5)') # 日间风力 16 d_tmpH = soup.select('#day7 > div:nth-child(' + str(i) + ') > div > div:nth-child(6)') # 全天高温 17 d_tmpL = soup.select('#day7 > div:nth-child(' + str(i) + ') > div > div:nth-child(7)') # 全天低温 18 listDate.append(d_date[0].contents[0]) 19 arr = [listDate[i - 1], d_desc[0].get_text(), d_windd[0].get_text(), d_winds[0].get_text(), 20 d_tmpH[0].get_text(), d_tmpL[0].get_text()] 21 for j in range(len(arr)): 22 arr[j] = "".join(arr[j].split()) 23 Dict[listDate[i - 1]] = arr 24 print(d_desc[0].get_text() + " " + d_windd[0].get_text() + " " + d_winds[0].get_text() + " " + d_tmpH[ 25 0].get_text() + " " + d_tmpL[0].get_text()) 26 27 out = open('SD_Daily_Climate_Test.csv', 'a', newline='') # 设定写入模式,参数'a'代表在其后追加内容 28 csv_write = csv.writer(out, dialect='excel') # 写入具体内容 29 for item in Dict.values(): 30 csv_write.writerow(item) 31 print("write over SD Daily Climate Test")
输出结果如下:
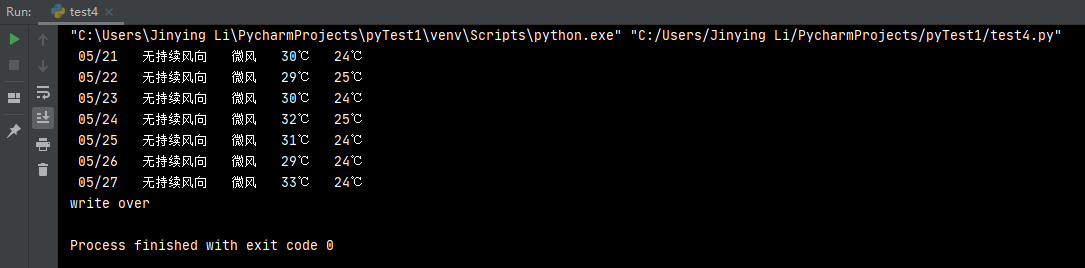
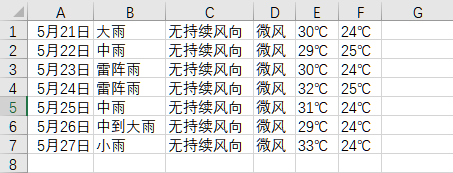
csv 保存内容如下:
参考资料

 浙公网安备 33010602011771号
浙公网安备 33010602011771号