
从mysql主从复制到微信开源的phxsql
严格的来说,微信开源的phxsql不是数据库,而是一个数据库的插件;
传统的互联网数据库结构一般是这样的:
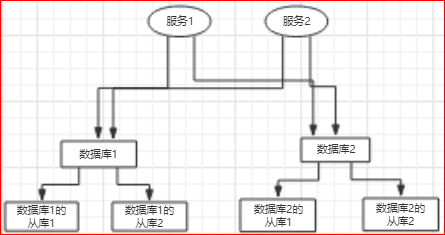
服务访问数据库是通过分片来的:
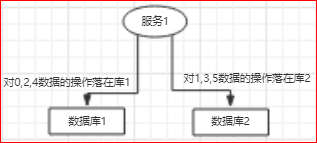
除了这种基于hash的分片,还有一种基于range的分片方式

通常,基于range的分片场景下会引入一个新的服务来保存range分片的元信息,列如etcd:
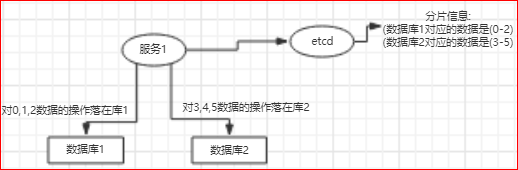
数据库连接是这样进行的:
第1步, 先监控etcd服务上的range信息变化;
第2步, 读取etcd服务上的range信息;
第3步, 接收到sql请求,解析sql语句,根据分片信息决定连接哪个数据库进行操作;
著名的开源数据库TiDB就是range来做数据库的水平拆分;
基于hash的数据库分片现在已经很少用了,因为扩容时非常麻烦;你可以自行脑补一下,1000台数据库的记录扩展到1500台,在不中断业务的情况下的操作;
上面的内容有点跑题,我们接下来看看主从复制:
为了防止某个库挂掉之后,记录丢失,有了主从复制

当然,主从复制还可以满足读写分离,减低主库的负担
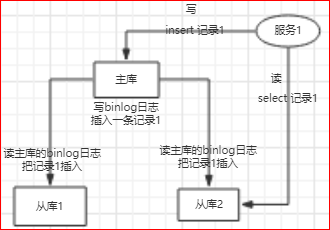
数据库连接的逻辑:
第1步, 解析sql;
第2步, 判断sql是读(insert, update, delete)还是写(select);
第3步, 落到相应的库上;
由于从库获取主库的记录有延时,所以读可能会失败,比如你刚发布了个帖子,却不能马上查到;
或者还有更坏的情况,你刚发了个帖子,主库挂了,这条记录还没同步到从库;这样帖子就丢了;
如果只是丢了帖子,情况还不算糟,重新发个帖子就是了;如果是在金融场景下,问题可能就麻烦了,比如下面的场景:

mysql主从复制可能会导致数据不一致,这是问题1;
再看下面的场景,如果数据库连接是基于故障自动切换的,则有可能会产生主库和从库同时被写的问题;
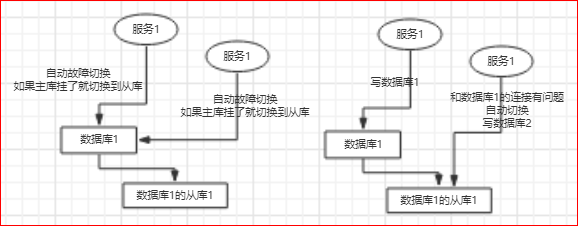
这种场景下,主从库的数据也会不一致,这是第二个问题;
为了解决第一个问题,phxsql引入了第一个插件BinLogSvr:
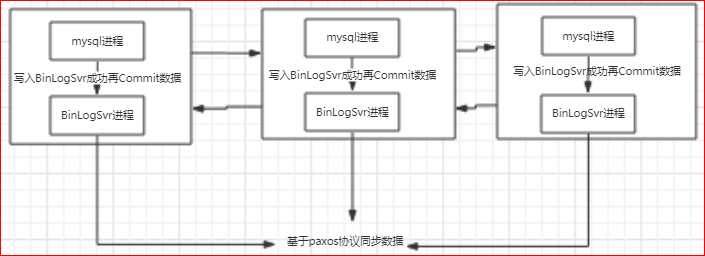
phxsql增加了一个进程BinLogSvr,用来管理mysql日志;
主库的逻辑变成了这样:
第1步, 收到sql请求;
第2步, 准备sql执行;
第3步, 写入BinLogSvr;
BinLogSvr用paxos协议,将这条日志复制到mysql集群中的其他机器上;
BinLogSvr返回成功;
第4步, Commit数据,返回成功;
从库的逻辑变成这样:
取消从主库获取binlog;
改成从本机的BinLogSvr获取binlog;
由于BinLogSvr基于paxos协议,binlog到BinLogSvr成功即表明mysql集群中半数以上的机器已经获取到最新的日志,除非半数以上的机器挂掉,才有可能产生数据不一致;
为了解决上述的第二个问题,phxsql引入了另一个插件PhxSqlProxy:

实际上, PhxSqlProxy也是一个进程,对前端,模仿了mysql服务端,对后端,模仿了mysql客户端,将数据库连接请求平等的对应到后端的mysql服务上;
mysql的主库由BinLogSvr来选举,基于paxos算法;
如果有sql请求到来,PhxSqlProxy会向BinLogSvr来查询当前是否为主库,如果是主库,则将请求传给本机的mysql服务;如果是从库,则将请求转给主库;
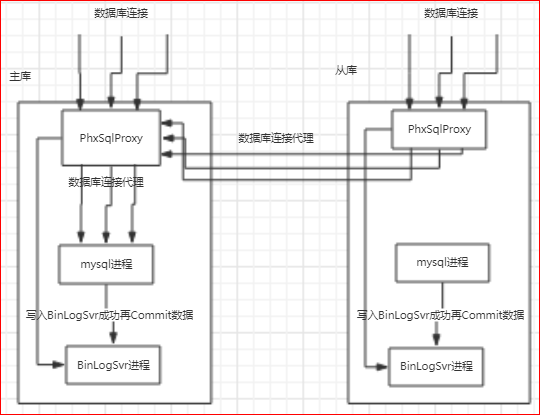
结束;
主库挂了或者是租约过期,新的主库选举是由BinlogSvr来完成的;


