

怎样用AI打飞机 (上)
怎样用AI打飞机

自监督学习

如上所示, 一个Agent(机器人)和一个Enviroment(环境)交互, 通过Obeservation(观察), 执行Action(行动), 获得Reward(奖励);
对比一下人脸识别的过程: 人脸样本打标签, 损失函数训练神经网络, 神经网络将人脸变为高维度上的点, 点的距离得出人脸的相似度;
无监督学习不需要样本和标签;
无监督学习需要Enviroment(环境); 神经网络通过和环境交互来学习;
Environment(环境)
OpenAI的gym是一个开源的库, 里面有很多Environment:
比如:
80年代Atari游戏公司的游戏, 用来训练打游戏:

多关节的机器人, 用来训练直立行走:

TF-Agent
TF-Agent是Google开源的Agent(机器人), 可以和Environment交互, 学习;
实现来自DeepMind的论文: DQN(Deep Q-Learning Network) --- 深度Q-Learning 神经网络;
TF-Agent对DQN做了封装, 训练机器人的时候几乎不需要考虑DQN的实现细节;
本篇本来是想用TF-Agent来训练机器人打飞机, 但是发现3年前的Keras的一个例子, 那个例子里面有DQN的实现细节;
代码
https://keras.io/examples/rl/
Keras的例子是一个打钻块的例子, 我用他来实现打飞机, 稍微改了一下:
加载打飞机的Environment, Atari的Assault-v4;
num_actions(机器人执行的Action)改为7;
Keras的输出, 去掉了繁琐的打印, 减少内存消耗;
加载Environment

这里DeepMind的模块对Atari的Environment做了一层封装, 主要是把彩色图变成灰度图, 缩小, 等等;
对比一下:
原图:

包装之后的图, 缩小成了84x84的灰度图:
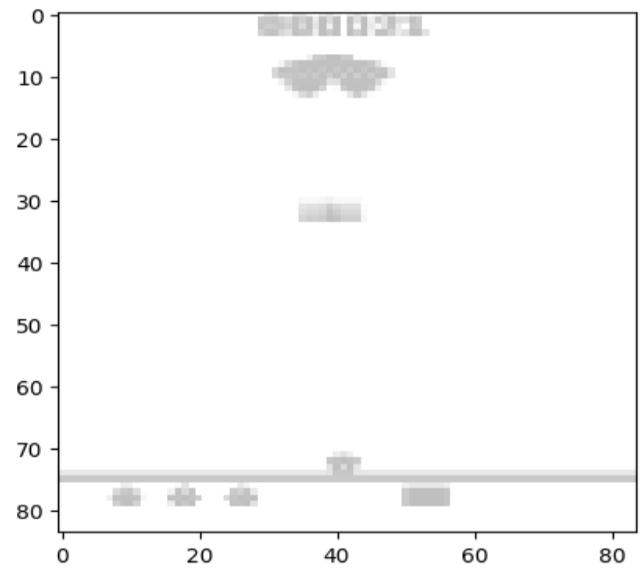
这样的好处是可以加快计算速度;
机器人执行的Action放在了action_space, 把它打印出来, 是一个"离散"型的值, 有7个变量:

其中, 0表示无操作, 1表示向上开火, 2表示左移, 等等;
我们执行一个右移的操作, 打印出来:
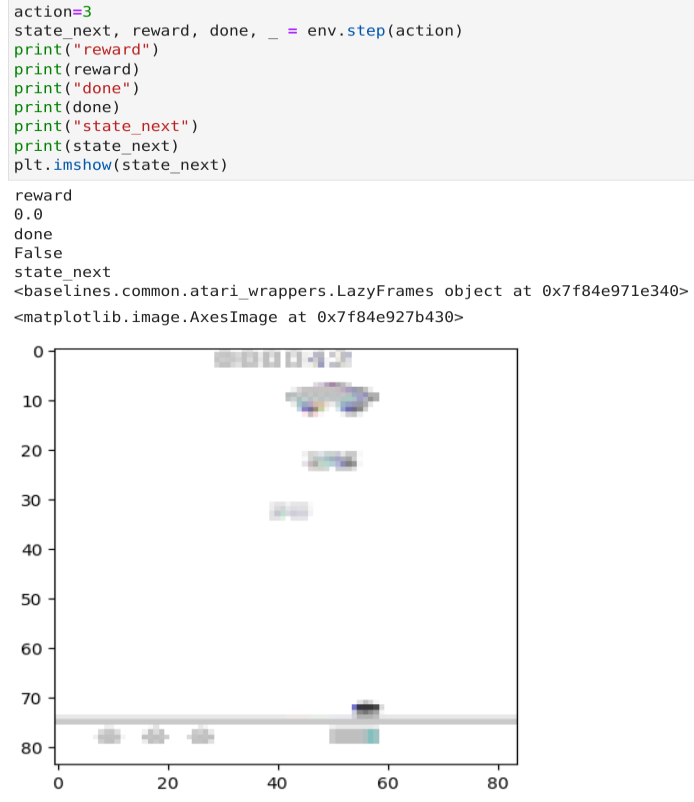
其中, Reward是获取到的奖励, done表示游戏是否结束, next_state是游戏的下一帧;
创建神经网络
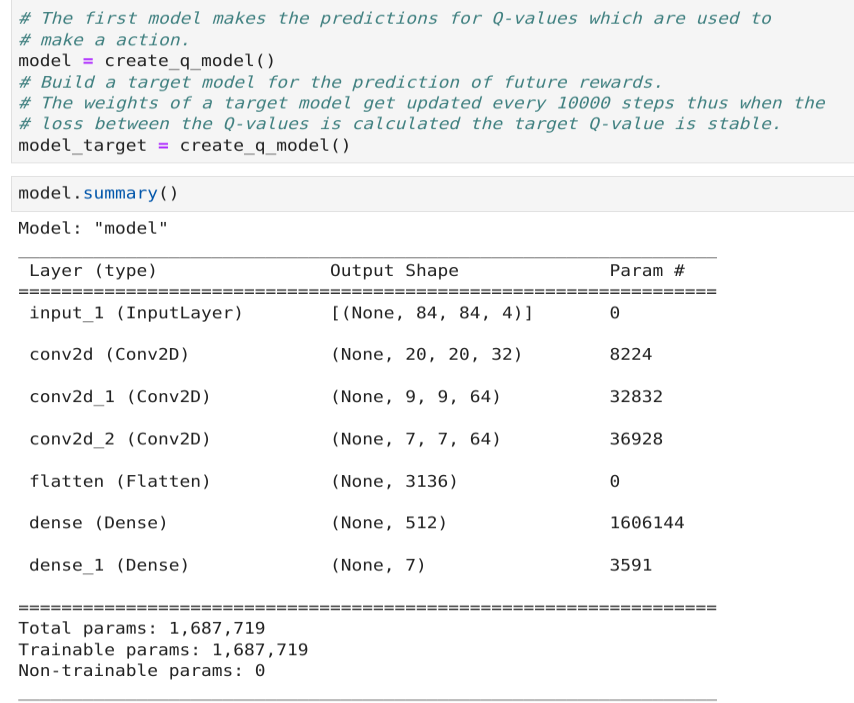
输入是84x84的灰度图,4表示4个frame; 输出是7(Action);
训练
https://keras.io/examples/rl/deep_q_network_breakout/
训练的部分比较复杂, 放在下期讲;
读者可以直接阅读Keras的例子, 里面的注释十分省心;
同时阅读一下马可夫决策和Q-Learning, 加上DeepMind的论文
DeepMind的论文可以在Google的TF-Agents介绍里面找到:
https://www.tensorflow.org/agents/tutorials/0_intro_rl#the_dqn_agent
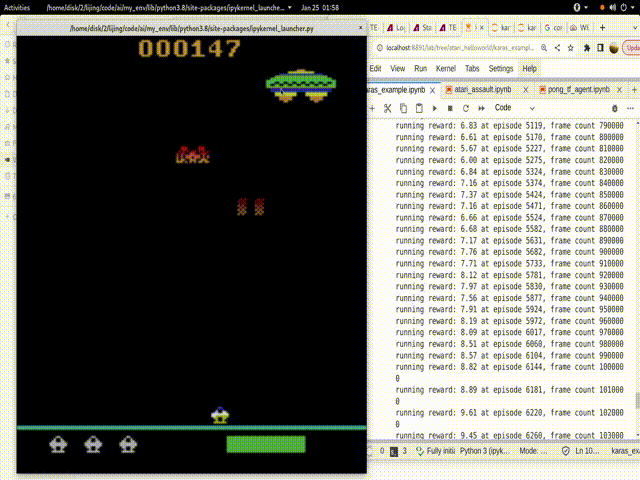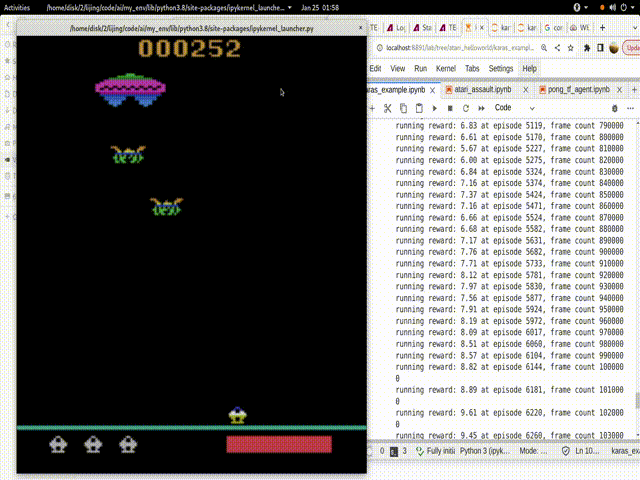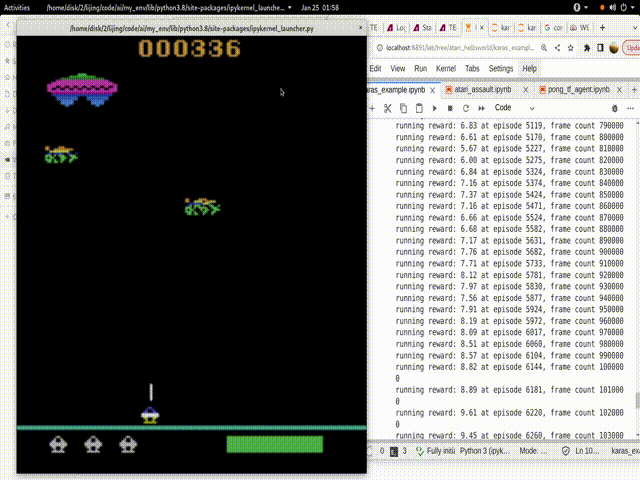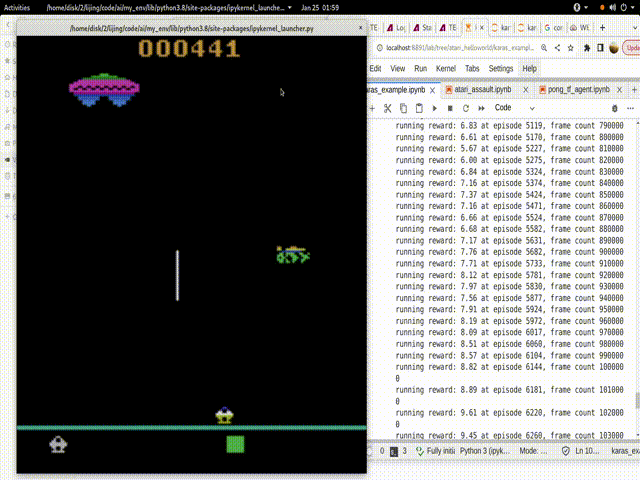
结果:
这是我一晚上的训练结果:

从300多的Reward达到了1000多的Reward

下期见;


