

肤浅的聊聊 TiDB 扫表算子, 扫索引算子, 合取范式(CNF), 析取范式(DNF), skyline pruning
这一章主要涉及TiDB如下的源码:
1. 扫表算子怎样转换为扫索引算子;
2. 怎样把Selection算子的过滤条件化简, 转为区间扫描;
假设我们有一个表:
t1( id int primary key not null auto_increment, a int, b int, c varchar(256), index(a) );
其中, id 是主键, a 是索引;
我们执行如下的 sql:
select a from t1 where a=5 or ( a>5 and (a>6 and a <8) and a<12);
这条 sql 的最终执行计划是这样的:
+---------------+--------+-----------+-----------------------------------------------------------------------+ | id | count | task | operator info | +---------------+--------+-----------+-----------------------------------------------------------------------+ | IndexReader_6 | 260.00 | root | index:IndexScan_5 | | └─IndexScan_5 | 260.00 | cop[tikv] | table:t1, index:a, range:[5,5], (6,8), keep order:false, stats:pseudo | +---------------+--------+-----------+-----------------------------------------------------------------------+
这是一个索引扫描的执行计划, 索引扫描区间是 [5,5], (6,8);
我们转到源代码, 看这样的计划是怎样生成的;
这是解析 sql 之后最初生成的执行计划:
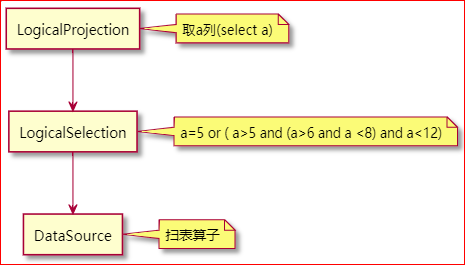
在调用 logicalOptimize 函数做逻辑优化之后, 执行计划变为下面这样:
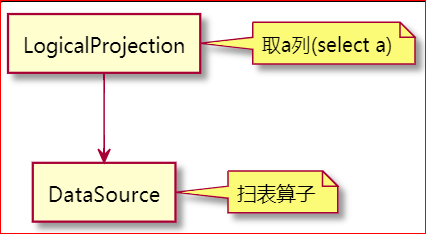
Selection算子哪儿去了?
Selection算子被下推到了 DataSource 算子中, 在 DataSource 的 pushedDownConds 中保存着下推的过滤算子, 是这样的:
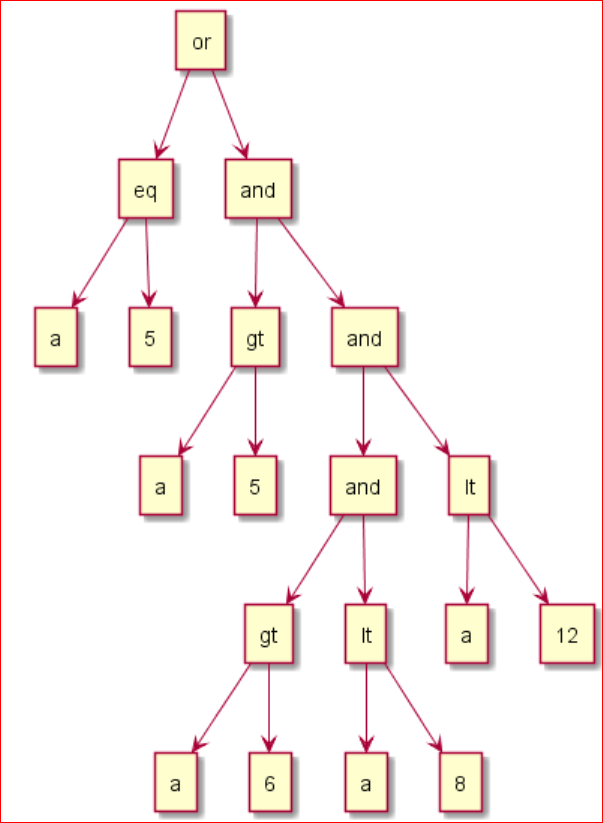
这样的一个递归的树状的过滤算子很难在索引扫描中使用, 因为索引底层是顺序排列的, 所以要将这颗树转为扫描区间;
在物理优化中, 会调用 DetachCondAndBuildRangeForIndex 来生成扫描区间, 这个函数会递归的调用如下 2 个函数:
detachDNFCondAndBuildRangeForIndex, 展开 析取范式(DNF), 生成扫描区间或合并扫描区间;
detachCNFCondAndBuildRangeForIndex, 展开 合取范式(CNF), 生成扫描区间或合并扫描区间;
上面的表达式树最终生成了这样的区间: [5,5], (6,8) --- "[" 是开区间, "(" 是闭区间, 递归被消除了;
接下来, 这个索引扫描会加入到 DataSource 的备选的访问表的方法中;
在 DataSource 的 possibleAccessPaths 里保存了访问表的可能的方案, 这里是 2 个方案:
1. 全表扫描, 用表达式树进行过滤: a=5 or ( a>5 and (a>6 and a <8) and a<12);
2. 扫索引 a 列, 执行区间扫描 [5,5], (6,8);
物理优化阶段, 会从算子树的根节点递归调用每个算子的 findBestTask 函数, DataSoure 算子会从 possibleAccessPaths 获取最优的执行计划;
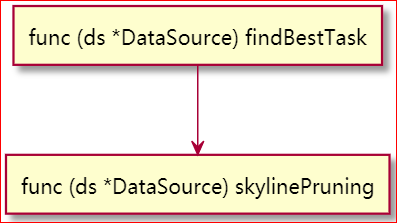
这里用到了 skyline pruning 算法, 从多个维度来判断哪个执行计划更优, 最后用索引扫描算子替换掉 DataSource 算子;
最终生成了这样的执行计划:

结束;


