
从 Basic Paxos 到 Multi Paxos 到 Raft
在朴素Paxos算法中, 各个节点经过 Prepare 和 Accept 阶段, 会达成一个值, 这个值一旦达成, 就不能被修改, 如下例子:

图示1
上面的操作几乎没有任何实用价值, 于是演变成下面这种操作, 多个"实例(Instance)", 每个Instance负责一轮Paxos投票, 这样可以有序确定多个值, 形成日志;
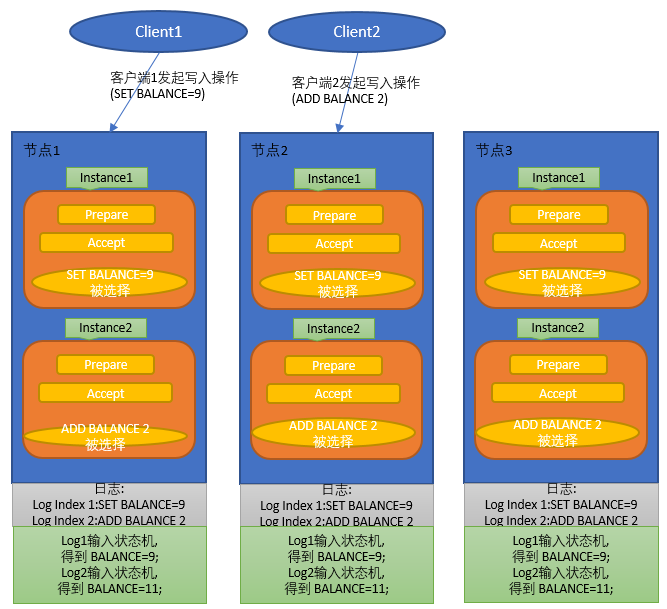
图2
将日志输入到状态机, 就形成了一套KV系统, 如果有全局统一的时钟 可以在日志里面带上时间戳, KV里面也带上时间戳, 这样可以实现数据快照读(snapshot);
上面的paxos系统可用性依然很差, 因为如下原因:
1. 即使提议没有竞争, 每次提议依然需要2次写盘(Prepare阶段写一次, Accept阶段写一次); 如果提议发生竞争, 写盘次数会更高;
2. 一个日志被确定之后, 落在多数派上的读取可以读取到最新的值, 落在少数派上的读取不能读取到最新的值(取决于少数派什么时候能够同步到最新的日志);
于是, 算法进化成如下的形式,
1. 选出一个Leader, 每次写和读都落在Leader上, 这样, 读操作能获取到最新的值;
2. Prepare只发起一次, 然后就是多次Accept, 这样可以将写盘次数降低;
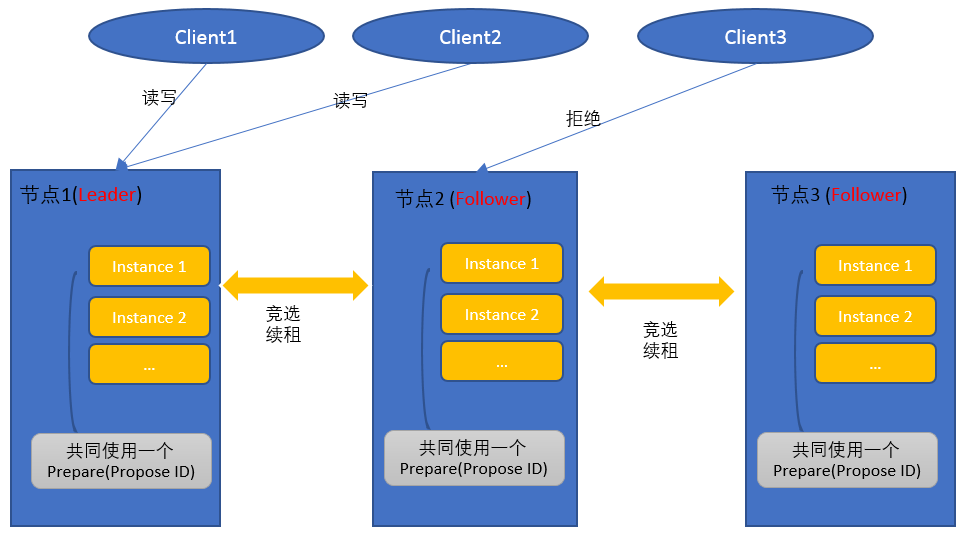
虽然有Leader, 但是即使Follower上有写入, 依然不会破坏一致性, 因为Follower上的写入会提升Prepare(Promise ID)的值, 这种情况下Multi Paxos会退化为 Basic Paxos;
借用phxpaxos的技术文章里的一句话来描写Leader的作用---"Leader的引入是为了性能, 不是为了一致性";
选举和续租暂时不讲了, 我也没怎么看懂;
可以看到, Paxos经过演化之后, 最终实现了如下的特性:
1. 读写落到Leader上, 读操作可以可以读取到最新的数据;
2. Leader的引入将2次或大于2次的磁盘写降为1次; (正常情况下);
3. 发生重新选举的情况下, 数据最新的节点能够竞选;
Raft用更简单的方式实现了这些特性, 这里有一个非常简单的Raft协议动画演示, 我们可以轻松的理解Raft:
http://thesecretlivesofdata.com/raft/
Raft中有几个重要的概念:
日志index(顺序号)
日志term)(时间)
两阶段: 日志复制(Replicate)阶段 和 日志提交(Commit)阶段;
Raft协议的细节我们不讲了, 我们看看Raft是怎么面对下面的问题的;
1. Leader崩溃了, 怎么选举; 要确保新的Leader是有最新日志, 不影响读操作;
Raft选举需要2个参数, 日志 Index和日志时间戳; 落后的节点不可能获得多数派通过;
2. 网络问题出现, 节点发生分裂, 该怎样保证整个集群的数据的Consensus;
分裂之后, 少数派的日志无法Commit,
Raft实现相对Paxos简单, 不像Paxos那样容易出错, 所以有很多语言版的Raft实现, 国内著名开源数据库TiDB贡献了rust语言的实现: https://github.com/pingcap/raft-rs
我们以Raft论文里的示例, 留下一个问题来思考吧:
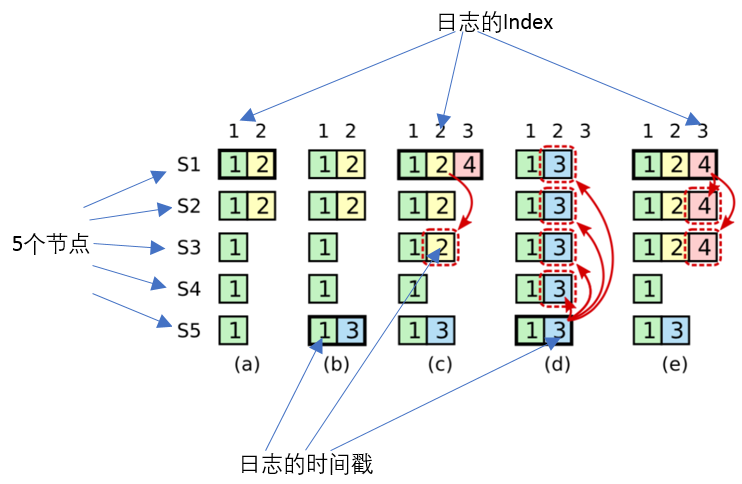
(a) 场景下, S1 挂掉, S5 竞选(S5竞选会得到S3, S4, S5的同意, 会遭到S2的拒绝, 因为S2的日志Index和日期都大于S5);
(b) 场景下S5写入3, 还没复制到其他节点就挂掉了;
(c) 场景下, S1又活过来, 竞选成为Leader, 将前次的 2 记录的日志"复制"给多数派;
因为不能Commit上个任期的日志, 所以2折条日志仍然是UnCommited;
然后新写入了 4 的日志, 没来得及复制和Commit, S1又挂掉了;
下面两种情况能出现吗?
(d) 场景下, S5活过来, 竞选成为Leader, 将日志3 复制到其他节点上;
或者
(e) 场景下, S1活过来, 竞选成为Leader, 将日志 2, 4 覆盖掉 S5 的日志;
答案:
Raft为了防止Commit的日志被冲掉, 有一个重要的约束:
Leader不能 "直接提交上个任期复制过的日志",
"只能提交这个任期的日志, 使上个任期的日志被间接提交";
所以:
(d)场景可以出现, 因为2这个日志并没有被Commit, 可以被S5的3覆盖, 但是S5不能直接提交3这个日志;
(e)场景可以出现, S1通过 复制 和 提交 4 这条日志, 使得 2 这条日志被间接提交; 之后即使S1再挂掉, S5也不能获得多数派投票;


