java集合框架之HashCode
参考http://how2j.cn/k/collection/collection-hashcode/371.html
List查找的低效率
假设在List中存放着无重复名称,没有顺序的2000000个Hero
要把名字叫做“hero 1000000”的对象找出来
List的做法是对每一个进行挨个遍历,直到找到名字叫做“hero 1000000”的英雄。
最差的情况下,需要遍历和比较2000000次,才能找到对应的英雄。
测试逻辑:
1. 初始化2000000个对象到ArrayList中
2. 打乱容器中的数据顺序
3. 进行10次查询,统计每一次消耗的时间
不同计算机的配置情况下,所花的时间是有区别的。 在本机上,花掉的时间大概是600毫秒左右

package collection; import java.util.ArrayList; import java.util.Collections; import java.util.List; import charactor.Hero; public class TestCollection { public static void main(String[] args) { List<Hero> heros = new ArrayList<Hero>(); for (int j = 0; j < 2000000; j++) { Hero h = new Hero("Hero " + j); heros.add(h); } // 进行10次查找,观察大体的平均值 for (int i = 0; i < 10; i++) { // 打乱heros中元素的顺序 Collections.shuffle(heros); long start = System.currentTimeMillis(); String target = "Hero 1000000"; for (Hero hero : heros) { if (hero.name.equals(target)) { System.out.println("找到了 hero!" ); break; } } long end = System.currentTimeMillis(); long elapsed = end - start; System.out.println("一共花了:" + elapsed + " 毫秒"); } } }
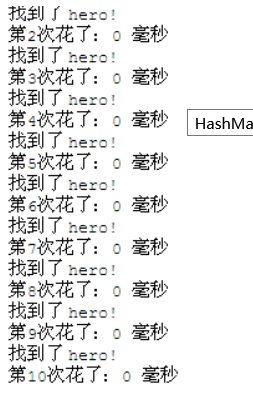
HashMap的性能表现
使用HashMap 做同样的查找
1. 初始化2000000个对象到HashMap中。
2. 进行10次查询
3. 统计每一次的查询消耗的时间
可以观察到,几乎不花时间,花费的时间在1毫秒以内
package collection; import java.util.HashMap; import charactor.Hero; public class TestCollection { public static void main(String[] args) { HashMap<String,Hero> heroMap = new HashMap<String,Hero>(); for (int j = 0; j < 2000000; j++) { Hero h = new Hero("Hero " + j); heroMap.put(h.name, h); } System.out.println("数据准备完成"); for (int i = 0; i < 10; i++) { long start = System.currentTimeMillis(); //查找名字是Hero 1000000的对象 Hero target = heroMap.get("Hero 1000000"); System.out.println("找到了 hero!" + target.name); long end = System.currentTimeMillis(); long elapsed = end - start; System.out.println("一共花了:" + elapsed + " 毫秒"); } } }
HashMap原理与字典
在展开HashMap原理的讲解之前,首先回忆一下大家初中和高中使用的汉英字典。
比如要找一个单词对应的中文意思,假设单词是Lengendary,首先在目录找到Lengendary在第 555页。
然后,翻到第555页,这页不只一个单词,但是量已经很少了,逐一比较,很快就定位目标单词Lengendary。
555相当于就是Lengendary对应的hashcode
分析HashMap性能卓越的原因
分析HashMap性能卓越的原因
-----hashcode概念-----
所有的对象,都有一个对应的hashcode(散列值)
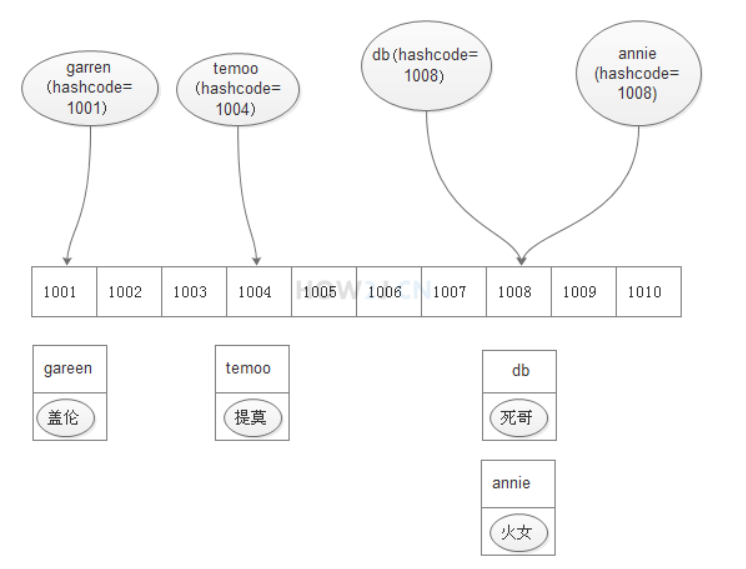
比如字符串“gareen”对应的是1001 (实际上不是,这里是方便理解,假设的值)
比如字符串“temoo”对应的是1004
比如字符串“db”对应的是1008
比如字符串“annie”对应的也是1008
-----保存数据-----
准备一个数组,其长度是2000,并且设定特殊的hashcode算法,使得所有字符串对应的hashcode,都会落在0-1999之间
要存放名字是"gareen"的英雄,就把该英雄和名称组成一个键值对,存放在数组的1001这个位置上
要存放名字是"temoo"的英雄,就把该英雄存放在数组的1004这个位置上
要存放名字是"db"的英雄,就把该英雄存放在数组的1008这个位置上
要存放名字是"annie"的英雄,然而 "annie"的hashcode 1008对应的位置已经有db英雄了,那么就在这里创建一个链表,接在db英雄后面存放annie
-----查找数据-----
比如要查找gareen,首先计算"gareen"的hashcode是1001,根据1001这个下标,到数组中进行定位,(根据数组下标进行定位,是非常快速的) 发现1001这个位置就只有一个英雄,那么该英雄就是gareen.
比如要查找annie,首先计算"annie"的hashcode是1008,根据1008这个下标,到数组中进行定位,发现1008这个位置有两个英雄,那么就对两个英雄的名字进行逐一比较(equals),因为此时需要比较的量就已经少很多了,很快也就可以找出目标英雄
这就是使用hashmap进行查询,非常快原理。
这是一种用空间换时间的思维方式
HashSet判断是否重复
HashSet的数据是不能重复的,相同数据不能保存在一起,到底如何判断是否是重复的呢?
根据HashSet和HashMap的关系,我们了解到因为HashSet没有自身的实现,而是里面封装了一个HashMap,所以本质上就是判断HashMap的key是否重复。
再通过上一步的学习,key是否重复,是由两个步骤判断的:
hashcode是否一样
如果hashcode不一样,就是在不同的坑里,一定是不重复的
如果hashcode一样,就是在同一个坑里,还需要进行equals比较
如果equals一样,则是重复数据
如果equals不一样,则是不同数据。
自定义字符串的hashcode
如下是Java API提供的String的hashcode生成办法;
n表示字符串的长度
本练习并不是要求去理解这个算法,而是自定义一个简单的hashcode算法,计算任意字符串的hashcode
因为String类不能被重写,所以我们通过一个静态方法来返回一个String的hashcode
如果字符串长度是0,则返回0。
否则: 获取每一位字符,转换成数字后,相加,最后乘以23
如果值超过了1999,则取2000的余数,保证落在0-1999之间。
如果是负数,则取绝对值。
随机生成长度是2-10的不等的100个字符串,打印用本hashcode获取的值分别是多少
HashCode代码
package Test.testtest; /** * @Auther: 李景然 * @Date: 2018/5/24 22:48 * @Description: */ public class HashCode { public static void main(String[] args) { int i=0; while (i<100){ double strLength=Math.ceil(Math.random()*8+2); StringBuilder sb=new StringBuilder(); char c; int start=(int)'0'; int end=(int)'z'+1; for (int j=0;j<strLength;j++){ c=(char) (Math.random()*(end-start)+start); if(Character.isLetterOrDigit(c)){ sb.append(c); }else{ j--; } } System.out.println(sb.toString()+"---"+hashcode(sb.toString())); i++; } } public static int hashcode(String str){ int result=0; if(str==null||str.length()==0){ return 0; } char[] chars=str.toCharArray(); for (char c :chars){ result+=(int)c; } result*=23; if(result>1999){ result%=2000; } return result; } }
部分结果:

自定义MyHashMap
根据前面学习的hashcode的原理和自定义hashcode, 设计一个MyHashMap,实现接口IHashMap
MyHashMap内部由一个长度是2000的对象数组实现。
设计put(String key,Object value)方法
首先通过上一个自定义字符串的hashcode练习获取到该字符串的hashcode,然后把这个hashcode作为下标,定位到数组的指定位置。
如果该位置没有数据,则把字符串和对象组合成键值对Entry,再创建一个LinkedList,把键值对,放进LinkedList中,最后把LinkedList 保存在这个位置。
如果该位置有数据,一定是一个LinkedList,则把字符串和对象组合成键值对Entry,插入到LinkedList后面。
设计 Object get(String key) 方法
首先通过上一个自定义字符串的hashcode练习获取到该字符串的hashcode,然后把这个hashcode作为下标,定位到数组的指定位置。
如果这个位置没有数据,则返回空
如果这个位置有数据,则挨个比较其中键值对的键-字符串,是否equals,找到匹配的,把键值对的值,返回出去。找不到匹配的,就返回空
IhashMap代码
package Test.testtest; /** * @Auther: 李景然 * @Date: 2018/5/24 22:46 * @Description: */ public interface IHashMap { public void put(String key,Object object); public Object get(String key); }
Entry代码
package Test.testtest; /** * @Auther: 李景然 * @Date: 2018/5/24 22:46 * @Description: */ public class Entry { public Entry(Object key, Object value) { super(); this.key = key; this.value = value; } public Object key; public Object value; @Override public String toString() { return "[key=" + key + ", value=" + value + "]"; } }
MyHashMap代码
package Test.testtest; import java.util.ArrayList; import java.util.LinkedList; import java.util.List; /** * @Auther: 李景然 * @Date: 2018/5/24 22:47 * @Description: */ public class MyHashMap implements IHashMap { private Object[] objects=new Object[2000]; public MyHashMap(){ } @Override public void put(String key, Object object) { int hashCode=HashCode.hashcode(key); if(objects[hashCode]==null){ //key值相同的时候,把value存放到链表中 LinkedList<Entry> list=new LinkedList<>(); list.add(new Entry(key,object)); objects[hashCode]=list; }else{ LinkedList<Entry> list=(LinkedList<Entry>)objects[hashCode]; list.add(new Entry(key,object)); objects[hashCode]=list; } } @Override public Object get(String key) { int hashCode=HashCode.hashcode(key); Object object=objects[hashCode]; if(object!=null){ LinkedList<Entry> list=(LinkedList<Entry>)object; for (Entry e:list){ if(e.key.equals(key)){ return e.value; } } } return null; } }
内容查找性能比较
重复前面的 练习-查找内容性能比较 ,不过不使用HashMap,而是使用上个练习中自定义的MyHashMap.
准备一个ArrayList其中存放100000(十万个)Hero对象,其名称是随机的,格式是hero-[4位随机数]
hero-3229
hero-6232
hero-9365
...
因为总数很大,所以几乎每种都有重复,把名字叫做 hero-5555的所有对象找出来
要求使用两种办法来寻找
1. 不使用MyHashMap,直接使用for循环找出来,并统计花费的时间
2. 借助MyHashMap,找出结果,并统计花费的时间
MyHashMapTest代码
package Test.testtest; import java.util.ArrayList; import java.util.HashMap; import java.util.List; import java.util.Map; /** * @Auther: 李景然 * @Date: 2018/5/24 23:04 * @Description: */ public class MyHashMapTest { public static void main(String[] args) { //初始化100000个英雄对象 ArrayList<Hero> arrayList=new ArrayList<>(); for (int i=0;i<100000;i++){ String str="hero-"+String.valueOf(Math.random()*9000+1000).substring(0,4); arrayList.add(new Hero(str)); } //初始化HashMap HashMap<String,ArrayList<Hero>> hashMap=new HashMap<>(); for (Hero h:arrayList){ ArrayList<Hero> list=hashMap.get(h.getName()); if(list==null){ list=new ArrayList<>(); hashMap.put(h.getName(),list); } list.add(h); } //初始化MyHashMap MyHashMap myHashMap=new MyHashMap(); for (Hero h:arrayList){ ArrayList<Hero> list=(ArrayList<Hero>)(myHashMap.get(h.getName())); if(list==null){ list=new ArrayList<>(); myHashMap.put(h.getName(),list); } list.add(h); } searchOfHashMapTest(hashMap,"hero-5555"); searchOfMyHashMapTest(myHashMap,"hero-5555"); } //使用hashMap循环来找hero-5555 private static void searchOfHashMapTest(HashMap<String,ArrayList<Hero>> hashMap,String key){ double startTime=System.currentTimeMillis(); ArrayList<Hero> list=hashMap.get(key); double endTime=System.currentTimeMillis(); if(list!=null){ System.out.println("使用hashMap循环来找hero-5555:找到"+list.size()+"个;用时:"+(endTime-startTime)+"毫秒"); }else{ System.out.println("使用hashMap循环来找hero-5555:找到"+0+"个;用时:"+(endTime-startTime)+"毫秒"); } } //使用myHashMap循环来找hero-5555 private static void searchOfMyHashMapTest(MyHashMap myHashMap,String key){ double startTime=System.currentTimeMillis(); int count=0; ArrayList<Hero> list=(ArrayList<Hero>) myHashMap.get(key); double endTime=System.currentTimeMillis(); if(list!=null){ System.out.println("使用myHashMap循环来找hero-5555:找到"+list.size()+"个;用时:"+(endTime-startTime)+"毫秒"); }else{ System.out.println("使用myHashMap循环来找hero-5555:找到"+0+"个;用时:"+(endTime-startTime)+"毫秒"); } }
运行结果:

虽然用HashMap或者MyHashMap查询速度快,几乎不花费时间。但是要用HashMap或者MyHashMap,我们首先要把ArrayList中的数据转移到HashMap或者MyHashMap中,这个也需要消耗时间,降低性能(从这个中可以看出 练习-查找内容性能比较)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号