Java入门——(6)集合
关键词:Collection接口、Map接口、Iterator接口、泛型、Collections工具类、Arrays工具类
一、集合概述
当数据多了需要存储,需要容器,而数据的个数不确定,无法使用数组,这时可以使用Java中另一个容器——集合,位于java.util 。
1、集合和数组的区别?
① 数组的长度是固定的。
集合的长度是可变的。
②数组中存储的是同一类型的元素,可以存储基本数据类型值。
集合存储的都是对象。而且对象的类型可以不一致。
2、什么时候使用集合呢?
当对象多的时候,先进行存储。
3、集合体系框架图
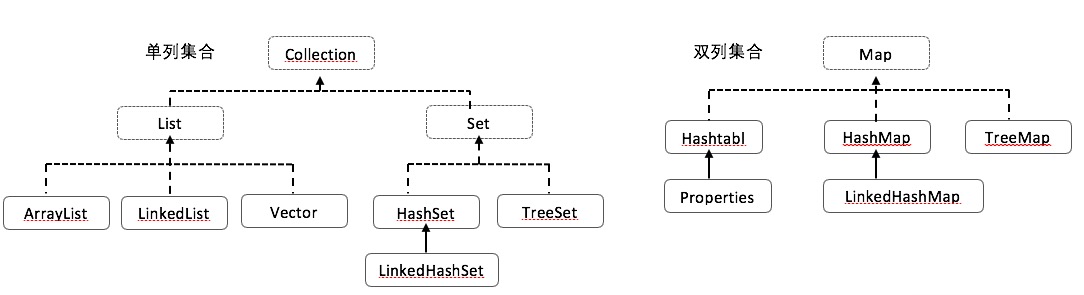
二、Collection接口
Collection接口:单列集合类的根接口

1、List接口:有序的,带索引的,通过索引就可以精确的操作集合中的元素,允许出现重复的元素。
使用List解决插入元素的问题,因为add方法追加。
List接口的特有方法,全部是围绕索引来定义的。
List获取元素的方式有两种:一种是迭代,一种是遍历+get方法。
List接口是支持对元素进行curd增删改查动作的。

①Vector:可以增长的数组结构。同步的。效率非常低,已被ArrayList替代。
②ArrayList:是数组结构,长度是可变的(原理创建新数组+复制数组),查询速度很快,增删较慢,不同步的。(应用广)。
示例:

1 public class Example01 {
2 public static void main(String[] args) {
3 ArrayList list = new ArrayList(); //创建ArrayList集合
4 list.add("stu1");
5 list.add("stu2");
6 list.add("stu3");
7 list.add("stu4");
8 System.out.println("集合的长度:"+list.size());//获得集合中元素的个数
9 System.out.println("集合的第二个元素:"+list.get(1));//取出并打印指定位置的元素
10 }
11 }
运行结果:
集合的长度:4 集合的第二个元素:stu2
③LinktedList:是链接结构,增删速度快,查询速度慢。可用于实现堆栈,队列。特有:围绕头和为展开定义的。
堆栈:先进后出First in Last Out FILO 可以理解为手枪弹夹
队列:先进先出First in First Out FILO 可以理解为排队买票
常用方法示例:
1 public class Example02 {
2 public static void main(String[] args) {
3 LinkedList link = new LinkedList();//创建LinkedList集合
4 link.add("stu1");
5 link.add("stu2");
6 link.add("stu3");
7 link.add("stu4");
8 System.out.println(link.toString());//取出元素并打印该集合中的元素
9 link.add(3,"Student"); //向该集合中的指定位置插入元素
10 link.addFirst("First"); //向该集合第一个位置插入元素
11 link.addLast("Last"); //向该集合第一个位置插入元素
12 System.out.println(link);
13 System.out.println(link.getFirst()); //取出该集合第一个元素
14 System.out.println(link.getLast()); //取出该集合最后一个个元素
15 link.remove(3); //移除该集合中指定位置的元素
16 link.removeFirst(); //移除该集合中第一个元素
17 link.removeLast(); //移除该集合中最后一个个元素
18 System.out.println(link);
19 }
20 }
运行结果:
[stu1, stu2, stu3, stu4] [First, stu1, stu2, stu3, Student, stu4, Last] First Last [stu1, stu2, Student, stu4]
2、Iterator接口
集合的取出方式:
①创建集合对象
Collection coll = new ArrayList();
②获取容器的迭代器对象,通过iterator方法;
Iterator it = coll.iterator();
③使用具体的迭代器对象获取集合中的元素;
while (it.hasNext()){
System.out.println(it.next());
}
实际开发建议使用以下方法(随着迭代完成,迭代器随之变成垃圾被清除,可以减少所占内存):
for(Iterator it = coll.iterator();it.hasNext();){
System.out.println(it.next());
}
该迭代器无法再迭代的过程中修改数组元素,否则会发生并发修改异常(ConcurrentModificationException)。
3、foreach:
其实就是增强for循环,用于遍历Collection和数组通常只能遍历元素,不要在遍历的过程中做对集合元素的操作。
格式:
for(元素数据类型 变量 :collection集合or数组()){执行语句}
和老式for循环的区别?
注意:新for循环必须有被遍历的目标。目标只能是Collection或者是数组。
建议:遍历数组时,如果仅为遍历,可以使用增强for,如果要对数组的元素进行操作,使用老式for循环可以通过角标操作。
示例:
1 public class Foreach {
2 static String [] strs = {"aaa","bbb","ccc"};
3 public static void main(String[] args) {
4 //foreach循环遍历数组
5 for(Object obj : strs){
6 System.out.println(obj);
7 }
8 System.out.println("______________");
9 //foreach循环遍历数组并修改(修改失败)
10 for (String str : strs){
11 str="ddd";
12 }
13 System.out.println("foreach循环修改后的数组:"+strs[0]+","+strs[1]+","+strs[2]);
14 //for循环遍历数组
15 for(int i = 0;i<strs.length;i++){
16 strs[i]="ddd";
17 }
18 System.out.println("普通for循环修改后的数组:"+strs[0]+","+strs[1]+","+strs[2]);
19 }
20 }
运行结果:
1 aaa 2 bbb 3 ccc 4 ______________ 5 foreach循环修改后的数组:aaa,bbb,ccc 6 普通for循环修改后的数组:ddd,ddd,ddd
4、ListIterator迭代器
Iterator的子类,该列表迭代只有List接口有,而且这个迭代器可以完成在迭代过程中的增删改查动作。

add方法示例:
1 public class AddDemo {
2 public static void main(String[] args) {
3
4 //在最前面添加
5 List<String> list1 = new LinkedList<String>(Arrays.asList(
6 new String[] { "a", "b", "c" }));
7 ListIterator<String> listIterator1 = list1.listIterator();
8 listIterator1.add("D");
9 listIterator1.add("E");
10 System.out.println(list1);//[D, E, a, b, c]
11 //在最后面添加
12 List<String> list2 = new LinkedList<String>(Arrays.asList(
13 new String[] { "a", "b", "c" }));
14 ListIterator<String> listIterator2 = list2.listIterator();
15 while (listIterator2.hasNext()) {
16 listIterator2.next();
17 }
18 listIterator2.add("D");
19 listIterator2.add("E");
20 System.out.println(list2);//[a, b, c, D, E]
21 //在每个元素的前面和后面都添加
22 List<String> list3 = new LinkedList<String>(Arrays.asList(
23 new String[] { "a", "b", "c" }));
24 ListIterator<String> listIterator3 = list3.listIterator();
25 while (listIterator3.hasNext()) {
26 listIterator3.add("前面");
27 listIterator3.next();
28 listIterator3.add("后面");
29 }
30 System.out.println(list3);//[前面, a, 后面, 前面, b, 后面, 前面, c, 后面]
31 //在指定元素的前面和后面添加
32 List<String> list4 = new LinkedList<String>(Arrays.asList(
33 new String[] { "a", "b", "c" }));
34 ListIterator<String> listIterator4 = list4.listIterator();
35 while (listIterator4.hasNext()) {
36 if (listIterator4.next().equals("a")) {//现在指向的是a的后面
37 listIterator4.previous();//先重新指向a的前面,这里不用担心NoSuchElementException
38 listIterator4.add("前面");//在前面添加元素,添加后还是指向的a的前面
39 listIterator4.next();//向后【再】移动一位,现在指向的是a的后面
40 listIterator4.add("后面");//在a的后面添加元素
41 }
42 }
43 System.out.println(list4);//[前面, a, 后面, b, c]
44 }
45 }
remove方法示例:
1 public class RemoveDemo {
2 public static void main(String[] args) {
3
4 // 执行next()或previous()后不能先执行了 add()方法。
5 // 因为add()方法执行以后,迭代器已经移动了,这样所要删除的目标元素指向不明,会报异常。
6 //标准的做法:在next之后才能remove
7 List<String> list2 = new LinkedList<String>(Arrays.asList(
8 new String[] { "b", "a", "b", "c", "b", }));
9 ListIterator<String> listIterator2 = list2.listIterator();
10 while (listIterator2.hasNext()) {
11 if (listIterator2.next().equals("b")) {listIterator2.remove();}
12 }
13 System.out.println(list2);//[a, c]
14
15 //移除指定范围内的所有元素
16 List<String> list3 = new LinkedList<String>(Arrays.asList(
17 new String[] { "a", "开始", "b", "c", "d", "结束", "e" }));
18 ListIterator<String> listIterator3 = list3.listIterator();
19 while (listIterator3.hasNext()) {
20 if (listIterator3.next().equals("开始")) {
21 listIterator3.remove();//注释掉这行代码则不移除"开始"
22 while (listIterator3.hasNext()) {
23 if (!listIterator3.next().equals("结束")) {
24 listIterator3.remove();//remove之后必须再调用next方法后才能再remove
25 } else {
26 listIterator3.remove();//注释掉这行代码则不移除"结束"
27 break;//结束while循环
28 }
29 }
30 }
31 }
32 System.out.println(list3);//[a, e]
33 //替换指定元素
34 List<String> list5 = new LinkedList<String>(Arrays.asList(
35 new String[] { "a", "b", "c" }));
36 ListIterator<String> listIterator5 = list5.listIterator();
37 while (listIterator5.hasNext()) {
38 if (listIterator5.next().equals("b")) {
39 listIterator5.remove();
40 listIterator5.add("替换");
41 }
42 }
43 System.out.println(list5);//[a, 替换, c]
44 }
45 }
5、Set接口
不包含重复元素的集合,不保证顺序。而且方法和Collection一致。Set集合取出元素的方式只有一种:迭代器。
①HashSet:哈希表结构,不同步,保证元素唯一性的方式依赖于: hashCode(),equals()方法。查询速度快。哈希值是根据存储位置来计算。
1 class Student{
2 private String id;
3 private String name;
4 public Student(String id,String name){
5 this.id = id;
6 this.name = name;
7 }
8 // 重写toString方法
9 public String toString(){
10 return id+":"+name;
11 }
12 // 重写hashCode方法
13 public int hashCode(){
14 return id.hashCode();//返回id属性的哈希值
15 }
16 // 重写equals方法
17 public boolean equals(Object obj){
18 if(this==obj){ //判断是否为同一个对象
19 return true; //如果是,直接返回true
20 }
21 if (!(obj instanceof Student)){ //判断对象是否Student类型
22 return false; //如果对象不是Student类型,返回false
23 }
24 Student stu = (Student)obj; //将对象强转为Student类型
25 boolean b= this.id.equals(stu.id); //判断id值是否相同
26 return b; //返回判断结果
27 }
28 }
29 public class HashSetDemo {
30 public static void main(String[] args) {
31 HashSet set = new HashSet();
32 Student stu1= new Student("1","Jack");
33 Student stu2= new Student("2","Rose");
34 Student stu3= new Student("2","Rose");
35 set.add(stu1);
36 set.add(stu2);
37 set.add(stu3);
38 System.out.println(set);
39 }
40 }
运行结果:
[1:Jack, 2:Rose] 若不重写hashCode()和equals()方法,则输出结果是: [2:Rose,1:Jack, 2:Rose]
②TreeSet:可以对Set集合中的元素进行排序。使用的是二叉树结构。如何保证元素唯一性的?使用的是对象比较方法的结果是否为0,是0,视为相同元素不存。
元素的排序比较有两种方式:
- 元素自身具备自然排序,其实就是实现了Comparable接口重写compareTo方法。如果元素自身不具备自然排序,或具备的自然排序不是所需要的,这时只能用第二种方式。
- 比较器,其实就是在创建TreeSet集合时,在构造函数中指定具体的比较方式。需要定义一个类实现Comparator接口,重写compare方法。
-
![复制代码]()
1 class Student implements Comparable{ //定义Student类实现Comparable接口 2 String name; 3 int age; 4 public Student(String name,int age){ //创建构造方法 5 this.name = name; 6 this.age = age; 7 } 8 public String toString(){ //重写Object类toString()方法,返回描述信息 9 return name+":"+age; 10 } 11 public int compareTo(Object obj){ //重写Comparable接口compareTo方法 12 Student s =(Student) obj; //将比较对象强转为Student类型 13 if (this.age -s.age>0){ //定义比较方法 14 return 1; 15 } 16 if (this.age-s.age==0){ 17 return this.name.compareTo(s.name);//将比较结果返回 18 } 19 return -1; 20 } 21 } 22 public class TreeSetDemo { 23 public static void main(String[] args) { 24 TreeSet ts = new TreeSet(); 25 ts.add(new Student("Jack",19)); 26 ts.add(new Student("Rose",18)); 27 ts.add(new Student("Tom",19)); 28 ts.add(new Student("Rose",18)); 29 Iterator it = ts.iterator(); 30 while (it.hasNext()){ 31 System.out.println(it.next()); 32 } 33 } 34 }
运行结果:
Rose:18
Jack:19
Tom:19![复制代码]()
到此为止:在往集合中存储对象时,通常该对象都需要覆盖hashCode,equals,同时实现Comparable接口,建立对象的自然排序。通常还有一个方法也会复写toString();
三、Map接口:
双列集合Map集合的特点:内部存储的都是键key值value对,必须要保证键的唯一性。
Map集合常用方法

①Hashtable---数据结构:哈希表。是同步的,不允许null作为键和值。被HashMap替代。
子类Properties:属性表,键和值都是字符串,而且可以结合流进行键值操作。唯一一个可以和IO流结合使用的集合类。
②HashMap---数据结构:哈希表。不是同步的,允许null作为键和值。
示例:
1 public class Example15 {
2 public static void main(String[] args){
3 Map map = new HashMap(); //创建Map对象
4 map.put("1","Jack"); //存储键和值,键相同,值覆盖
5 map.put("2","Rose");
6 map.put("3","Lucy");
7 map.put("3","Mary");
8 System.out.println("1:"+map.get("1"));//根据键获取值
9 System.out.println("2:"+map.get("2"));
10 System.out.println("3:"+map.get("3"));
11 }
12 }
Map集合的两种遍历方式:
1 public class Example16 {
2 public static void main(String[] args){
3 //第一种先遍历Map集合中所有的键,再跟据键获取相应的值。
4 Map map1 = new HashMap(); //创建Map对象
5 map1.put("1","Jack"); //存储键和值
6 map1.put("2","Rose");
7 map1.put("3","Lucy");
8 Set keySet1 = map1.keySet(); //获取键的集合
9 Iterator it1 = keySet1.iterator();
10 while (keySet1.iterator().hasNext()){ // 迭代键的集合
11 Object key = it1.next();
12 Object value = map1.get(key); //获得每个键所对应的值
13 System.out.println(key+":"+value);
14 }
15
16 //第二种先获取集合中的所有映射关系,然后从映射关系中取出键和值
17 Map map2 = new HashMap();
18 map2.put("1","Jack"); //存储键和值
19 map2.put("2","Rose");
20 map2.put("3","Lucy");
21 Set entrySet = map2.entrySet();
22 Iterator it = entrySet.iterator(); //获取Iterator对象
23 while (it.hasNext()){
24 Map.Entry entry = (Map.Entry)(it.next()); //获取集合中键值对映射关系
25 Object key = entry.getKey(); //获取Entry中的键
26 Object value = entry.getValue(); //获取Entry中的值
27 System.out.println(key+":"+value);
28 }
29 }
30 }
运行结果:
1:Jack 2:Rose 3:Lucy
LinkedHashMap:基于链表+哈希表。可以保证map集合有序(存入和取出的顺序一致)。
③TreeMap---数据结构:二叉树,保证键的唯一性,同步的,可以对map集合中的键进行排序。
1 //按学号从大排到小
2 public class Example20 {
3 public static void main(String[] args) {
4 TreeMap tm = new TreeMap(new MyCompartor()); //传入一个自定义比较器
5 tm.put("1","Jack"); //存储键和值
6 tm.put("2","Rose");
7 tm.put("3","Lucy");
8 Set keySet = tm.keySet(); //获取键的集合
9 Iterator it = keySet.iterator(); // 迭代键的集合
10 while (it.hasNext()){
11 Object key = it.next();
12 Object value = tm.get(key); //获得每个键所对应的值
13 System.out.println(key+":"+value);
14 }
15 }
16 }
17 class MyCompartor implements Comparator{ //自定义比较器
18 public int compare(Object o1, Object o2) { //实现比较方法
19 String id1 = (String) o1; //将Object类型的参数强转为String类型
20 String id2 = (String) o2;
21 return id2.compareTo(id1); //将比较结果之后的值返回,按字典相反顺序进行排序
22 }
23 }
运行结果:
3:Lucy 2:Rose 1:Jack
四、 泛型(parameterized type)
1、泛型的使用
体现<数据类型>,<>也是括号,往括号里写都写其实就是在传递参数。
格式:ArrayList<参数化类型> list = new ArrayList<参数化类型>();
泛型的优点:安全机制;将运行时期的ClassCastExecption转移到了编译时期变成了编译失败。泛型技术,是给编译器使用的技术。避免了强转的麻烦。
示例:
![复制代码]()
![复制代码]()
1 public class Example23 {
2 public static void main(String[] args) {
3 ArrayList<String> list = new ArrayList<String>();
4 list.add("String");
5 list.add("Collection");
6 for(String str:list){
7 System.out.println(str);
8 }
9 }
10 }
2、自定义泛型:
需求:请自己提供一个容器类。
分析:你要做一个容器类,你就应该知道容器类具备什么基本功能?
添加功能 save()
获取功能 get()
要做这样的方法,save是不是应该有参数呢?肯定的。
get()应该有参数吗?这里我们可以不给形式参数,但是一定要有返回值类型。
基本格式:
void save (参数类型 参数){…}
返回值类型 get(){…..}
为了让我们的容器类能够存储任意类型的对象,我就应该给save()方法中的参数定义为object类型。
当然,get()方法的返回值类型应该是object类型。
出现问题:A 不兼容类型 B 类型转换异常
需求:自己定义一个泛型类并使用
如何定义一个泛型类呢?
就是把泛型安装其格式加在类上。
格式:
<参数化类型>可以是E、T这样有意义的单词。
使用泛型后,我们可以不用再做类型转换了。
//在创建类时,声明参数类型为T
class 类名<T>{
T temp;
//在创建save()方法时,指定参数类型为T
public void save (T temp){this.temp = temp}
//在创建get()方法时,指定返回值类型为T
public T get(){
return temp;
}
}
示例:
1 class CachePool<T>{
2 T temp;
3 public void save(T temp){
4 this.temp=temp;
5 }
6 public T get() {
7 return temp;
8 }
9 }
10 public class Example26 {
11 public static void main(String[] args) {
12 CachePool<Integer> pool = new CachePool<Integer>();
13 pool.save(new Integer(1));
14 Integer temp = pool.get();
15 System.out.println(temp);
16 }
17 }
五、Collections工具类
Collections:集合框架中的用于操作集合对象工具类。都是静态方法。
- 获取Collection最值。
- 对List集合排序,也可以用二分查找。
- 对排序逆序。
- 可以将非同步的集合转变成同步的集合。如:Xxx synchronizedXxx(Xxx) -------List synchronizedList (List)
//排序操作
1 public class Example27 { 2 public static void main(String[] args) { 3 ArrayList list = new ArrayList(); 4 Collections.addAll(list,"c","z","B","K"); 5 System.out.println("排序前:"+list); 6 Collections.reverse(list); 7 System.out.println("反转后:"+list); 8 Collections.shuffle(list); 9 System.out.println("按自然顺序排序后:"+list); 10 Collections.sort(list); 11 System.out.println("洗牌后:"+list); 12 } 13 }
运行结果:
排序前:[c, z, B, K] 反转后:[K, B, z, c] 按自然顺序排序后:[c, B, K, z] 洗牌后:[B, K, c, z]
//查找、替换操作
1 public class Example28 {
2 public static void main(String[] args) {
3 ArrayList list = new ArrayList();
4 Collections.addAll(list,-3,2,9,5,8);
5 System.out.println("集合中的元素:"+list);
6 System.out.println("集合中的最大元素:"+Collections.max(list));
7 System.out.println("集合中的最小元素:"+Collections.min(list));
8 Collections.replaceAll(list,8,0); //将集合中的8用0替换掉
9 System.out.println("替换后的集合:"+list);
10 }
11 }
运行结果:
集合中的元素:[-3, 2, 9, 5, 8] 集合中的最大元素:9 集合中的最小元素:-3 替换后的集合:[-3, 2, 9, 5, 0]
六、Arrays:用于操作数组的工具类。类中定义的都是静态工具方法。
- 对数组排序。
- 二分查找。
- 数组复制。
- 对两个数组进行元素的比较,判断两个数组是否相同。
- 将数组转成字符串。
![复制代码]()
1 //使用Arrays的sort()方法排序 2 public class Example29 { 3 public static void main(String[] args) { 4 int[] arr={9,8,3,5,2}; 5 System.out.print("排序前:"); 6 printArray(arr); 7 Arrays.sort(arr); 8 System.out.print("排序后:"); 9 printArray(arr); 10 } 11 public static void printArray(int[] arr) { 12 System.out.print("["); 13 for (int x=0;x<arr.length;x++){ 14 if (x!=arr.length-1){ 15 System.out.print(arr[x]+","); 16 }else { 17 System.out.println(arr[x]+"]"); 18 19 } 20 } 21 } 22 }排序前:[9,8,3,5,2]
排序后:[2,3,5,8,9]![复制代码]()
-
![复制代码]()
1 //使用Arrays的binarySearch(Object[] a,Object key)方法查找元素 2 class Example { 3 public void run() { 4 int[] arr={9,8,3,5,2}; 5 Arrays.sort(arr);//调用排序方法,对数组排序 6 int index = Arrays.binarySearch(arr,3);//查找指定元素3 7 System.out.println("数组排序后元素3的索引是:"+index);//输出打印元素所在的索引位置 8 } 9 }
数组排序后元素3的索引是:1![复制代码]()
-
![复制代码]()
1 //使用Arrays的copyOfRange(int[] original,int from,int to)方法拷贝元素 2 class Example31 { 3 public void run() { 4 int[] arr={9,8,3,5,2}; 5 int[] copies=Arrays.copyOfRange(arr,1,7); 6 for (int i =0;i<arr.length;i++){ 7 System.out.print(copies[i]+","); 8 } 9 } 10 }
【8,3,5,2,0,0】![复制代码]()
![复制代码]()
1 //使用Arrays的fill(Object[] a,Object val)方法填充元素 2 class Example{ 3 public void run() { 4 int[] arr={1,2,3,4}; 5 Arrays.fill(arr,8); 6 for (int i =0;i<arr.length;i++){ 7 System.out.print(i+":"+arr[i]+“---”); 8 } 9 } 10 }
0:8---1:8---2:8---3:8![复制代码]()
![复制代码]()
1 //使用Arrays的toString(int [] ,arr)方法把数组转换为字符串 2 class Example{ 3 public void run() { 4 int[] arr={9,8,3,5,2}; 5 String arrString=Arrays.toString(arr); //使用toString()方法将数组转换为字符串 6 System.out.println(arrString); 7 } 8 }[9, 8, 3, 5, 2]
![复制代码]()
6、数组转成list集合——asList() 。
数组转成集合:就是为了使用集合的方法操作数组中的元素。
但是不要使用增删等改变长度的方法。add remove 发生UnsupportedOperationException
如果数组中存储的是基本数据类型,那么转成集合,数组对象会作为集合中的元素存在。数组中元素是引用数据类型时,转成,数组元素会作为集合元素存在。
7、集合转成数组——toArray().
为什么集合转成数组呢?
为了限制对元素的增删操作。
如果传递的数组的长度小于集合的长度,会创建一个同类型的数组长度为集合的长度。
如果传递的数组的长度大于集合的长度,就会使用这个数组,没有存储元素的位置为null。
长度最好直接定义为何集合长度一致。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号