
iceoryx源码阅读(四)——共享内存通信(二)
0 导引
-
iceoryx源码阅读(六)——共享内存创建
-
iceoryx源码阅读(七)——服务发现机制
-
iceoryx源码阅读(九)——等待与通知机制
本文阅读与共享内存通信相关的逻辑。发布者首先获取一块共享内存,往其中写入数据,然后向消息队列中推入消息描述数据,订阅者从消息队列中读取消息描述数据。本文从四方面进行解读:队列数据结构、共享内存获取、消息发送逻辑、消息接收逻辑。
1 队列数据结构
根据前文知道,队列元素为ShmSafeUnmanagedChunk,其中存放的是ChunkManagement所在共享内存段的id和相对该共享内存首地址的偏移,具体如下所示:
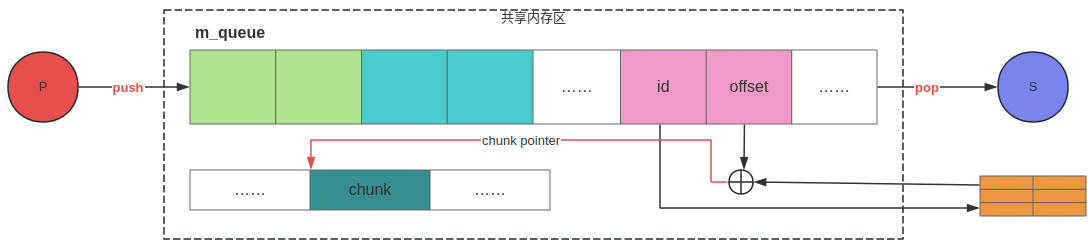
消息队列由如下代码定义:
struct ChunkQueueData : public LockingPolicy
{
// ...
static constexpr uint64_t MAX_CAPACITY = ChunkQueueDataProperties_t::MAX_QUEUE_CAPACITY;
cxx::VariantQueue<mepoo::ShmSafeUnmanagedChunk, MAX_CAPACITY> m_queue;
// ...
};
struct ChunkDistributorData : public LockingPolicy
{
// ...
using QueueContainer_t =
cxx::vector<memory::RelativePointer<ChunkQueueData_t>, ChunkDistributorDataProperties_t::MAX_QUEUES>;
QueueContainer_t m_queues;
// ...
};
struct ChunkReceiverData : public ChunkQueueDataType
{
// ...
};
-
ChunkDistributorData是发布者所持有的队列数据结构,由于一个发布者会分发至多个订阅端,所以持有多个队列。 -
ChunkReceiverData是订阅者的组件,它继承自ChunkQueueData,内部只有一个队列,队列元素类型为ShmSafeUnmanagedChunk。
上述代码中,队列数据结构的类型为cxx::VariantQueue<mepoo::ShmSafeUnmanagedChunk, MAX_CAPACITY>。从类名看,是一个变长数组,但实际上这是一个定长数组,以下是相关数据结构定义:
enum class VariantQueueTypes : uint64_t
{
FiFo_SingleProducerSingleConsumer = 0,
SoFi_SingleProducerSingleConsumer = 1,
FiFo_MultiProducerSingleConsumer = 2,
SoFi_MultiProducerSingleConsumer = 3
};
template <typename ValueType, uint64_t Capacity>
class VariantQueue
{
public:
using fifo_t = variant<concurrent::FiFo<ValueType, Capacity>,
concurrent::SoFi<ValueType, Capacity>,
concurrent::ResizeableLockFreeQueue<ValueType, Capacity>,
concurrent::ResizeableLockFreeQueue<ValueType, Capacity>>;
// ...
private:
VariantQueueTypes m_type;
fifo_t m_fifo;
};
fifo_t是队列底层结构类型,可能是concurrent::FiFo、concurrent::SoFi、concurrent::ResizeableLockFreeQueue之一,至于使用哪一种,由枚举值m_type确定。这三个内部会依赖以下数据结构:
template <typename ElementType, uint64_t Capacity>
struct NonZeroedBuffer
{
struct alignas(ElementType) element_t
{
cxx::byte_t data[sizeof(ElementType)];
};
element_t value[Capacity];
};
上面这一结构本质就是一个数组,其元素类型类型为Element。
2 共享内存获取
发送数据前,应用程序首先需要先获取一块合适大小的Chunk,往其中写入数据,然后调用消息发送接口进行发送。
2.1 PublisherImpl::loan
职责:
获取一块共享内存,并调用构造函数进行初始化。
入参:
args:模板变参,用于调用待传类型的构造函数,也可以不传。
返回:
Sample类型实例,本质是对用户可操作的共享内存段的封装。
template <typename T, typename H, typename BasePublisherType>
template <typename... Args>
inline cxx::expected<Sample<T, H>, AllocationError>
PublisherImpl<T, H, BasePublisherType>::loan(Args&&... args) noexcept
{
return std::move(loanSample().and_then([&](auto& sample) { new (sample.get()) T(std::forward<Args>(args)...); }));
}
整体代码分析:
首先调用loanSample方法获取共享内存,然后调用构造函数进行初始化,这里使用Placement new语法。需要指出的是,loanSample返回的是将用于存放用户数据的首地址,而不是Chunk的首地址。
2.2 PublisherImpl::loanSample
职责:
分配共享内存,并将其转换为Sample类型,并返回。
返回:
Sample类型实例。
template <typename T, typename H, typename BasePublisherType>
inline cxx::expected<Sample<T, H>, AllocationError> PublisherImpl<T, H, BasePublisherType>::loanSample() noexcept
{
static constexpr uint32_t USER_HEADER_SIZE{std::is_same<H, mepoo::NoUserHeader>::value ? 0U : sizeof(H)};
auto result = port().tryAllocateChunk(sizeof(T), alignof(T), USER_HEADER_SIZE, alignof(H));
if (result.has_error())
{
return cxx::error<AllocationError>(result.get_error());
}
else
{
return cxx::success<Sample<T, H>>(convertChunkHeaderToSample(result.value()));
}
}
整体代码分析:
首先调用tryAllocateChunk获得一块共享内存,并构造Sample实例。
2.3 PublisherPortUser::tryAllocateChunk
职责:
分配共享内存,并将其转换为Sample类型,并返回。
入参:
4个用于计算所需共享内存大小的参数,这里不展开介绍了。
返回值:
共享内存首地址(类型为ChunkHeader *,见4.1 Chunk管理结构)
cxx::expected<mepoo::ChunkHeader*, AllocationError>
PublisherPortUser::tryAllocateChunk(const uint32_t userPayloadSize,
const uint32_t userPayloadAlignment,
const uint32_t userHeaderSize,
const uint32_t userHeaderAlignment) noexcept
{
return m_chunkSender.tryAllocate(
getUniqueID(), userPayloadSize, userPayloadAlignment, userHeaderSize, userHeaderAlignment);
}
整体代码分析:
上述函数只是简单地调用ChunkSender的tryAllocate方法。
2.4 ChunkSender::tryAllocate
职责:
调用MemoryManager的成员方法getChunk得到共享内存块或复用最后一次使用的共享内存块。
入参:
同上(略)
返回值:
指向共享内存块首地址的指针,类型为ChunkHeader。
template <typename ChunkSenderDataType>
inline cxx::expected<mepoo::ChunkHeader*, AllocationError>
ChunkSender<ChunkSenderDataType>::tryAllocate(const UniquePortId originId,
const uint32_t userPayloadSize,
const uint32_t userPayloadAlignment,
const uint32_t userHeaderSize,
const uint32_t userHeaderAlignment) noexcept
{
const auto chunkSettingsResult =
mepoo::ChunkSettings::create(userPayloadSize, userPayloadAlignment, userHeaderSize, userHeaderAlignment);
if (chunkSettingsResult.has_error())
{
return cxx::error<AllocationError>(AllocationError::INVALID_PARAMETER_FOR_USER_PAYLOAD_OR_USER_HEADER);
}
const auto& chunkSettings = chunkSettingsResult.value();
const uint32_t requiredChunkSize = chunkSettings.requiredChunkSize();
auto& lastChunkUnmanaged = getMembers()->m_lastChunkUnmanaged;
mepoo::ChunkHeader* lastChunkChunkHeader =
lastChunkUnmanaged.isNotLogicalNullptrAndHasNoOtherOwners() ? lastChunkUnmanaged.getChunkHeader() : nullptr;
if (lastChunkChunkHeader && (lastChunkChunkHeader->chunkSize() >= requiredChunkSize))
{
/* * * * * 见代码段2-4-1:复用最近一次分配的共享内存 * * * * */
}
else
{
/* * * * * 见代码段2-4-2:分配一块新的未使用的共享内存 * * * * */
}
}
逐段代码分析:
-
LINE 09 ~ LINE 17: 计算所需共享内存大小。
-
LINE 19 ~ LINE 30: 判断最近一次分配的共享内存块是否所有订阅者都已读取,并且大小超过所需大小,则复用最近一次分配的共享内存块,否则新分配共享内存块。
代码段2-4-1:复用最近一次分配的共享内存
auto sharedChunk = lastChunkUnmanaged.cloneToSharedChunk();
if (getMembers()->m_chunksInUse.insert(sharedChunk))
{
auto chunkSize = lastChunkChunkHeader->chunkSize();
lastChunkChunkHeader->~ChunkHeader();
new (lastChunkChunkHeader) mepoo::ChunkHeader(chunkSize, chunkSettings);
lastChunkChunkHeader->setOriginId(originId);
return cxx::success<mepoo::ChunkHeader*>(lastChunkChunkHeader);
}
else
{
return cxx::error<AllocationError>(AllocationError::TOO_MANY_CHUNKS_ALLOCATED_IN_PARALLEL);
}
整体代码分析:
如果正在使用的共享内存块未满,则插入,并析构之前的数据,同时在这块内存上构造新的ChunkHeader;否则返回错误。
代码段2-4-2:分配一块新的未使用的共享内存
auto getChunkResult = getMembers()->m_memoryMgr->getChunk(chunkSettings);
if (!getChunkResult.has_error())
{
auto& chunk = getChunkResult.value();
// if the application allocated too much chunks, return no more chunks
if (getMembers()->m_chunksInUse.insert(chunk))
{
// END of critical section
chunk.getChunkHeader()->setOriginId(originId);
return cxx::success<mepoo::ChunkHeader*>(chunk.getChunkHeader());
}
else
{
// release the allocated chunk
chunk = nullptr;
return cxx::error<AllocationError>(AllocationError::TOO_MANY_CHUNKS_ALLOCATED_IN_PARALLEL);
}
}
else
{
/// @todo iox-#1012 use cxx::error<E2>::from(E1); once available
return cxx::error<AllocationError>(cxx::into<AllocationError>(getChunkResult.get_error()));
}
整体代码分析:
调用MemoryManager的成员方法getChunk获取共享内存块,如果获取成功,存入数组m_chunksInUse。如果获取失败或数组已满,则返回获取失败,此时根据RAII原理,SharedChunk的析构函数会自动将共享内存块返还给MemPool。
m_chunksInUse内部封装的数组元素的类型为我们在上一篇文章中介绍的ShmSafeUnmanagedChunk,这个类型不具有引用计数,为什么退出作用域不会被析构?
为什么要存m_chunksInUse数组?原因如下:我们看到tryAllocate返回的是消息内存块的指针,而消息发送的时候需要使用SharedChunk,我们无法将前者转换为后者。所以,此处存入数组,消息发送函数中通过消息内存块的指针查找对应数组元素,恢复出SharedChunk实例,具体见3.3。
3 消息发送逻辑
本质是往消息队列推入消息描述结构ShmSafeUnmanagedChunk。
3.1 PublisherImpl::publish
职责:
上层应用程序调用此方法推送消息。
入参:
sample:用户负载数据的封装实例。
template <typename T, typename H, typename BasePublisherType>
inline void PublisherImpl<T, H, BasePublisherType>::publish(Sample<T, H>&& sample) noexcept
{
auto userPayload = sample.release(); // release the Samples ownership of the chunk before publishing
auto chunkHeader = mepoo::ChunkHeader::fromUserPayload(userPayload);
port().sendChunk(chunkHeader);
}
整体代码分析:
上述代码从sample中取出用户负载数据指针,据此计算Chunk首地址,然后调用sendChunk进行发送。
根据用户负载数据指针计算Chunk首地址其实就是减去一个偏移量,具体计算方法如下:
ChunkHeader* ChunkHeader::fromUserPayload(void* const userPayload) noexcept
{
if (userPayload == nullptr)
{
return nullptr;
}
uint64_t userPayloadAddress = reinterpret_cast<uint64_t>(userPayload);
auto backOffset = reinterpret_cast<UserPayloadOffset_t*>(userPayloadAddress - sizeof(UserPayloadOffset_t));
return reinterpret_cast<ChunkHeader*>(userPayloadAddress - *backOffset);
}
其中偏移放在payload之前,即:*backOffset。
3.2 PublisherPortUser::sendChunk
职责:
发送用户数据。
入参:
chunkHeader:ChunkHeader类型的指针,Chunk的首地址。
void PublisherPortUser::sendChunk(mepoo::ChunkHeader* const chunkHeader) noexcept
{
const auto offerRequested = getMembers()->m_offeringRequested.load(std::memory_order_relaxed);
if (offerRequested)
{
m_chunkSender.send(chunkHeader);
}
else
{
m_chunkSender.pushToHistory(chunkHeader);
}
}
整体代码分析:
3.3 ChunkSender::send
职责:
发送用户数据。
入参:
chunkHeader:ChunkHeader指针,Chunk的首地址。
template <typename ChunkSenderDataType>
inline uint64_t ChunkSender<ChunkSenderDataType>::send(mepoo::ChunkHeader* const chunkHeader) noexcept
{
uint64_t numberOfReceiverTheChunkWasDelivered{0};
mepoo::SharedChunk chunk(nullptr);
// BEGIN of critical section, chunk will be lost if the process terminates in this section
if (getChunkReadyForSend(chunkHeader, chunk))
{
numberOfReceiverTheChunkWasDelivered = this->deliverToAllStoredQueues(chunk);
getMembers()->m_lastChunkUnmanaged.releaseToSharedChunk();
getMembers()->m_lastChunkUnmanaged = chunk;
}
// END of critical section
return numberOfReceiverTheChunkWasDelivered;
}
逐段代码分析:
-
LINE 05 ~ LINE 07: 根据
chunkHeader指针和m_chunksInUse数组,恢复SharedChunk实例; -
LINE 09 ~ LINE 09: 调用基类的成员方法
deliverToAllStoredQueues向各队列发送(推入)消息; -
LINE 11 ~ LINE 12: 更新
m_lastChunkUnmanaged实例,以提升性能。
3.4 ChunkDistributor::deliverToAllStoredQueues
template <typename ChunkDistributorDataType>
inline uint64_t ChunkDistributor<ChunkDistributorDataType>::deliverToAllStoredQueues(mepoo::SharedChunk chunk) noexcept
{
uint64_t numberOfQueuesTheChunkWasDeliveredTo{0U};
typename ChunkDistributorDataType::QueueContainer_t remainingQueues;
/* * * * * 见代码段3-3-1:向队列发送消息,失败入remainingQueues * * * * */
/* * * * * 见代码段3-3-2:发送失败的不断尝试重新发送 * * * * */
addToHistoryWithoutDelivery(chunk);
return numberOfQueuesTheChunkWasDeliveredTo;
}
整体代码分析:
这部分没有什么内容,主要实现在代码段3-3-1和代码段3-3-2。
代码段3-3-1:
{
{
typename MemberType_t::LockGuard_t lock(*getMembers());
bool willWaitForConsumer = getMembers()->m_consumerTooSlowPolicy == ConsumerTooSlowPolicy::WAIT_FOR_CONSUMER;
// send to all the queues
for (auto& queue : getMembers()->m_queues)
{
bool isBlockingQueue = (willWaitForConsumer && queue->m_queueFullPolicy == QueueFullPolicy::BLOCK_PRODUCER);
if (pushToQueue(queue.get(), chunk))
{
++numberOfQueuesTheChunkWasDeliveredTo;
}
else
{
if (isBlockingQueue)
{
remainingQueues.emplace_back(queue);
}
else
{
++numberOfQueuesTheChunkWasDeliveredTo;
ChunkQueuePusher_t(queue.get()).lostAChunk();
}
}
}
}
整体代码分析:
这段代码整体上是遍历所有订阅者队列,调用pushToQueue向消息队列推入消息,实现消息发送。但是消息队列的长度是有限的,如果由于订阅者处理速度太慢,队列满了应该怎么处理,根据设置,可以选择两种应对策略:
-
将队列保存下来(LINE 17 ~ LINE 20),后续对这些队列不断尝试发送,直到所有队列推送成功,见代码段3-3-2;
-
将队列标记为有消息丢失(LINE 22 ~ LINE 25):
template <typename ChunkQueueDataType>
inline void ChunkQueuePusher<ChunkQueueDataType>::lostAChunk() noexcept
{
getMembers()->m_queueHasLostChunks.store(true, std::memory_order_relaxed);
}
代码段3-3-2:不断尝试发送,直到所有消息发送成功
cxx::internal::adaptive_wait adaptiveWait;
while (!remainingQueues.empty())
{
adaptiveWait.wait();
{
typename MemberType_t::LockGuard_t lock(*getMembers());
/* * * * * 见代码段3-3-3:与活跃队列求交 * * * * */
for (uint64_t i = remainingQueues.size() - 1U; !remainingQueues.empty(); --i)
{
if (pushToQueue(remainingQueues[i].get(), chunk))
{
remainingQueues.erase(remainingQueues.begin() + i);
++numberOfQueuesTheChunkWasDeliveredTo;
}
if (i == 0U)
{
break;
}
}
}
}
整体代码分析:
这部分代码就是对剩余未发送成功的队列进行重新发送,直到所有队列发送成功。每轮尝试中间会使用yield或sleep函数等待一段时间,以免不必要的性能浪费。同时,发送过程中,还会与当前活跃队列求交,如下:
代码段3-3-3:与活跃队列求交
typename ChunkDistributorDataType::QueueContainer_t queueIntersection(remainingQueues.size());
auto greaterThan = [](memory::RelativePointer<ChunkQueueData_t>& a,
memory::RelativePointer<ChunkQueueData_t>& b) -> bool {
return reinterpret_cast<uint64_t>(a.get()) > reinterpret_cast<uint64_t>(b.get());
};
std::sort(getMembers()->m_queues.begin(), getMembers()->m_queues.end(), greaterThan);
std::sort(remainingQueues.begin(), remainingQueues.end(), greaterThan);
auto iter = std::set_intersection(getMembers()->m_queues.begin(),
getMembers()->m_queues.end(),
remainingQueues.begin(),
remainingQueues.end(),
queueIntersection.begin(),
greaterThan);
queueIntersection.resize(static_cast<uint64_t>(iter - queueIntersection.begin()));
remainingQueues = queueIntersection;
整体代码分析:
上面这段代码就是求解remainingQueues和当前活跃队列m_queues交集,以免发生无限循环。set_intersection是C++标准库函数,详见:https://en.cppreference.com/w/cpp/algorithm/set_intersection
至此,消息发送的流程分析完毕。
4 小结
本文介绍了消息发布者获取共享内存块和发送逻辑,下文将介绍消息订阅者的接收逻辑。

