



假设现在有个form表单,当页面中提交一个包含中文的请求时,在服务端有可能出现中文乱码问题。
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>Insert title here</title> </head> <body> <form action="registerServlet" method="POST"> 姓名:<input type="text" name="name"><br> 年龄:<input type="text" name="age"><br> <input type="submit" value="注册"> </form> </body> </html>
乱码的产生原因
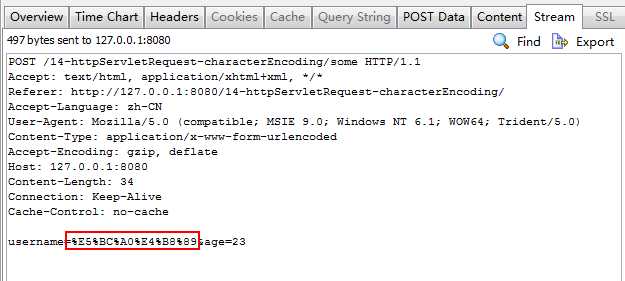
Http协议中规定,数据的传输采用字节编码方式,即无论浏览器提交的数据所包含的中文是什么字符编码格式,一旦由浏览器经过Http 协议传输,则这些数据均将以 字节的形式上传给服务器。 因为 HTTP 协议的底层使用的是 TCP 传输协议。 TCP (Transmission Control Protocol) 传输控制协议 ,是一种面向连接的、可靠的、基于字节流的、端对端的通信协议。在请求中,这些字节均以 开头,并以十六进制形式出现。如 %5A%3D 等。
当用户通过浏览器提交一个包含 UTF 8 编码格式的两个字的中文请求时,浏览器会将这两个中文字符变为六个字节(一般一个 UTF 8 汉字占用三个字节),即形成六个类似 %8E 的字节表 示形式,并将这六个字节上传至 Tomcat 服务器。Tomcat 服务器在接收到这六个字节后,并不知道它们原始采用的是什么字符编码。而Tomcat 默认的编码格式为 ISO 8859-1 。所以会将这六个字节按照 ISO 8859-1 的格式进行编码,这种编码方式不支持中文,这样就出现了乱码。
关于请求的乱码的解决方案
一、针对POST提交方式的解决方案
<!--
设置了请求正文的字符编码,服务器解码的时候会按照UTF-8解码
但是这种方式对于GET方式的请求不适用,因为只对请求正文有作用,
GET方式的请求正文为空行,请求的参数出现在请求行 -->
request.setCharacterEncoding("UTF-8");
二、针对GET提交方式的解决方案
对于GET方式提交的情况,上述中设置request.setCharacterEncoding("UTF-8");是不会起作用的,因为GET方式的请求参数是在请求行
目前了解的两种解决方案:
①Tomcat的版本影响,我自己试了一下Tomcat的7.*版本的,什么都不设置的话,会有乱码,但是用7.*以上的Tomcat服务器8.*,9.*的版本就不会出现乱码
②当我们以GET方式向服务器提交数据的话,在地址栏中,URL中URI部分的参数提交的中文会以字节的方式显示,对于请求路径中所携带参数的解析,由 Tomcat 服务器完成。而 Tomcat 服务器的字符编码默认为 ISO8859-1 ,所以会将请求路径中所携带的数据,按照 ISO8859 1 进行编码。

这种情况下我们可以通过修改 Tomcat 默认字符编码的方式来解决 GET 提交方式中携带中文的乱码问题。在 Tomcat 安装目录的 conf/server.xml 中,找到端口号为 8080 的 <Connector>标签,在其中添加 URIEncoding=UTF-8 的设置,即可将 Tomcat 默认字符编码修改为 UTF-8 。
(不建议,如果服务器有多个虚拟服务器,修改后会重启多个应用程序)

三、万能的解决方案(比较通用但是还是有弊端)
String name = request.getParameter("name");
byte[] bytes = name.getBytes("ISO8859-1");
name = new String(bytes, "UTF-8");
该方式无需设置Tomcat 中的 server.xml 中的 Tomcat 默认字符编码,无需设置 request的请求体的字符编码。从数据在请求中的存放形式,到数据被Tomcat 中的 Servlet 接收到后的存放形式,均是由单个字 节的形式存在,而在众多字符编码格式中, ISO8859-1 为单字节编码,所以,首先以 ISO8859 -1 的形式先对单字节的数据进行编码,并将编码后的数据存放在字节数组中。然后,再将字节数组中的数据,按照指定的 UTF -8 格式进行解码,即变为了需要的 UTF- 8 字符编码的数据,解决了中文乱码问题。
编码,即重新编排,即打散,将字符串 打散后按照指定编码进行重新编排。 这里的编码使用的是 String 的 getBytes() 方法,完成的工作是:按照当前字符编码将数据打散。
解码,即解释执行,即组装,对打散的字符按照指定编码组装后进行解释执行。 这里的解码使用的是StringString的带参构造器,完成的工作是:按照原有字符编码将数据组装。的带参构造器,完成的工作是:按照原有字符编码将数据组装。
该方式针对POST与与GET提交方式,均起作用。
响应的乱码问题
产生原因:之所以响应时会产生乱码,是因为 HTTP 协议中规定,默认响应体的字符编码为ISO-8859-1 。所以,若要解决乱码问题,就需要修改响应体的默认编码。
解决方案:
①
response.setContentType("text/html“);//设置MIME类型
response.setCharacterEncoding("UTF-8");
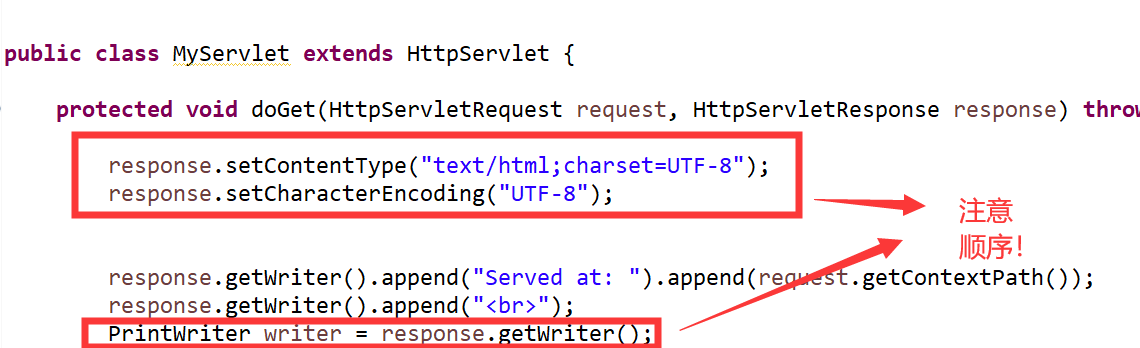
修改 MIME 的字符编码,即修改响应体的字符编码。但使用 setCharacterEncoding() 方法的前提是,之前必须要通过使用方法 setContentType() 方法设置响应内容的 MIME 类型。否则 setCharacterEncoding() 方法不起作用。
②
response.setContentType("text/html;charset=UTF-8");
用于 设置响应 内容 的 MIME 类型 ,其中可以指定 MIME 的字符编码。而 MIME 的字符编码,即响应体的字符编码 。
①②是一样的,没啥区别!!!
浏览器会根据响应体字符编码,自动调整其对响应体内容的解码方式,即会使用响应体的字符编码显示响应体内容。不过,需要注意一点,这些设置,必须在PrintWriter 对象产生之前先设置,否则将不起作用。
重定向的乱码解决方式
//底层按字节流传输,打散 name = URLEncoder.encode(name, "UTF-8"); //另一边接收 //组装 name = URLDecoder.decode(name, "UTF-8");
byte[] bytes = name.getBytes("ISO8859-1");
name = new String(bytes, "UTF-8");

