
VGG
前言
VGGNet是牛津大学计算机视觉组(VisualGeometry Group)和GoogleDeepMind公司的研究员一起研发的的深度卷积神经网络。VGGNet探索了卷积神经网络的深度与其性能之间的关系,通过反复堆叠3*3的小型卷积核和2*2的最大池化层,VGGNet成功地构筑了16~19层深的卷积神经网络。VGGNet相比之前state-of-the-art的网络结构,错误率大幅下降,并取得了ILSVRC 2014比赛分类项目的第2名和定位项目的第1名。同时VGGNet的拓展性很强,迁移到其他图片数据上的泛化性非常好。VGGNet的结构非常简洁,整个网络都使用了同样大小的卷积核尺寸(3*3)和最大池化尺寸(2*2)。到目前为止,VGGNet依然经常被用来提取图像特征。VGGNet训练后的模型参数在其官方网站上开源了,可用来在特定的图像分类任务上进行再训练(相当于提供了非常好的初始化权重),因此被用在了很多地方。
VGG原理
VGG16相比AlexNet的一个改进是采用连续的几个3x3的卷积核代替AlexNet中的较大卷积核(11x11,7x7,5x5)。对于给定的感受野(与输出有关的输入图片的局部大小),采用堆积的小卷积核是优于采用大的卷积核,因为多层非线性层可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)。
简单来说,在VGG中,使用了3个3x3卷积核来代替7x7卷积核,使用了2个3x3卷积核来代替5*5卷积核,这样做的主要目的是在保证具有相同感知野的条件下,提升了网络的深度,在一定程度上提升了神经网络的效果。
比如,3个步长为1的3x3卷积核的一层层叠加作用可看成一个大小为7的感受野(其实就表示3个3x3连续卷积相当于一个7x7卷积),其参数总量为 3x(9xC^2) ,如果直接使用7x7卷积核,其参数总量为 49xC^2 ,这里 C 指的是输入和输出的通道数。很明显,27xC^2小于49xC^2,即减少了参数;而且3x3卷积核有利于更好地保持图像性质。
这里解释一下为什么使用2个3x3卷积核可以来代替5*5卷积核:
5x5卷积看做一个小的全连接网络在5x5区域滑动,我们可以先用一个3x3的卷积滤波器卷积,然后再用一个全连接层连接这个3x3卷积输出,这个全连接层我们也可以看做一个3x3卷积层。这样我们就可以用两个3x3卷积级联(叠加)起来代替一个 5x5卷积。
VGG网络结构
下面是VGG网络的结构(VGG16和VGG19都在):
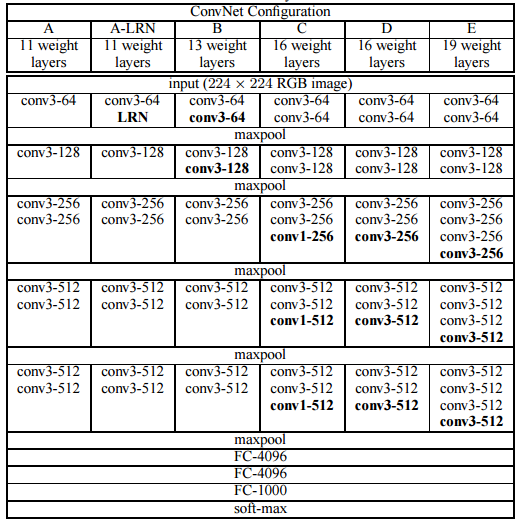
- VGG16包含了16个隐藏层(13个卷积层和3个全连接层),如上图中的D列所示
- VGG19包含了19个隐藏层(16个卷积层和3个全连接层),如上图中的E列所示
VGG网络的结构非常一致,从头到尾全部使用的是3x3的卷积和2x2的max pooling
VGG-16
假设这个小图是我们的输入图像,尺寸是224×224×3,进行第一个卷积之后得到224×224×64的特征图,接着还有一层224×224×64,得到这样2个厚度为64的卷积层,意味着我们用64个过滤器进行了两次卷积。正如我在前面提到的,这里采用的都是大小为3×3,步幅为1的过滤器,并且都是采用same卷积,所以我就不再把所有的层都画出来了,只用一串数字代表这些网络。
接下来创建一个池化层,池化层将输入图像进行压缩,从224×224×64缩小到多少呢?没错,减少到112×112×64。然后又是若干个卷积层,使用129个过滤器,以及一些same卷积,我们看看输出什么结果,112×112×128.然后进行池化,可以推导出池化后的结果是这样(56×56×128)。接着再用256个相同的过滤器进行三次卷积操作,然后再池化,然后再卷积三次,再池化。如此进行几轮操作后,将最后得到的7×7×512的特征图进行全连接操作,得到4096个单元,然后进行softmax激活,输出从1000个对象中识别的结果。
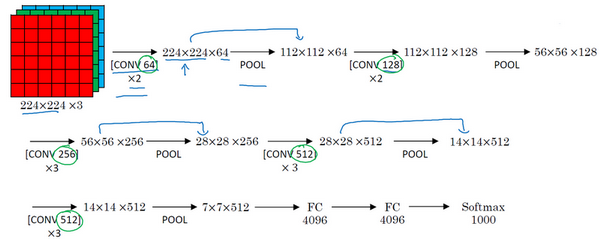
顺便说一下,VGG-16的这个数字16,就是指在这个网络中包含16个卷积层和全连接层。确实是个很大的网络,总共包含约1.38亿个参数,即便以现在的标准来看都算是非常大的网络。但VGG-16的结构并不复杂,这点非常吸引人,而且这种网络结构很规整,都是几个卷积层后面跟着可以压缩图像大小的池化层,池化层缩小图像的高度和宽度。同时,卷积层的过滤器数量变化存在一定的规律,由64翻倍变成128,再到256和512。作者可能认为512已经足够大了,所以后面的层就不再翻倍了。无论如何,每一步都进行翻倍,或者说在每一组卷积层进行过滤器翻倍操作,正是设计此种网络结构的另一个简单原则。这种相对一致的网络结构对研究者很有吸引力,而它的主要缺点是需要训练的特征数量非常巨大。
VGG优缺点
VGG优点
VGGNet的结构非常简洁,整个网络都使用了同样大小的卷积核尺寸(3x3)和最大池化尺寸(2x2)。
几个小滤波器(3x3)卷积层的组合比一个大滤波器(5x5或7x7)卷积层好:
验证了通过不断加深网络结构可以提升性能。
VGG缺点
VGG耗费更多计算资源,并且使用了更多的参数(这里不是3x3卷积的锅),导致更多的内存占用(140M)。其中绝大多数的参数都是来自于第一个全连接层。VGG可是有3个全连接层啊!
代码实现,分别用原生tensorflow和slim实现
tensorflow

1 import tensorflow as tf 2 3 #VGGNet-16包含很多层卷积,我们先写一个函数conv_op,用来创建卷积层并把本层的参数存入参数列表。 4 def conv_op(input_op,name,kh,kw,n_out,dh,dw,p): 5 n_in = input_op.get_shape()[-1].value 6 with tf.name_scope(name) as scope: 7 kernel = tf.get_variable(scope+'w',shape=[kh,kw,n_in,n_out],dtype=tf.float32,initializer=tf.contrib.layers.xavier_initializer_conv2d()) 8 conv = tf.nn.conv2d(input_op,kernel,(1,dh,dw,1),padding='SAME') 9 bias_init_val = tf.constant(0.0,shape=[n_out],dtype=tf.float32) 10 biases = tf.Variable(bias_init_val,trainable=True,name='b') 11 z = tf.nn.bias_add(conv,biases) 12 activation = tf.nn.relu(z,name=scope) 13 p += [kernel,biases] 14 return activation 15 16 def fc_op(input_op,name,n_out,p): 17 n_in = input_op.get_shape()[-1].value 18 with tf.name_scope(name) as scope: 19 kernel = tf.get_variable(scope + "w", shape=[n_in, n_out], dtype=tf.float32,initializer=tf.contrib.layers.xavier_initializer()) 20 biases = tf.Variable(tf.constant(0.1, shape=[n_out], dtype=tf.float32), name='b') 21 activation = tf.nn.relu_layer(input_op, kernel, biases, name=scope) 22 p += [kernel, biases] 23 return activation 24 25 def mpool_op(input_op, name, kh, kw, dh, dw): 26 return tf.nn.max_pool(input_op, ksize=[1, kh, kw, 1], strides=[1, dh, dw, 1], padding='SAME', name=name) 27 28 29 def inference_op(input_op,keep_prob): 30 p = [] 31 conv1_1 = conv_op(input_op,name='conv1_1',kh=3,kw=3,n_out=64,dh=1,dw=1,p=p) 32 conv1_2 = conv_op(conv1_1, name="conv1_2", kh=3, kw=3, n_out=64, dh=1, dw=1, p=p) 33 pool1 = mpool_op(conv1_2, name="pool1", kh=2, kw=2, dw=2, dh=2) 34 35 conv2_1 = conv_op(pool1, name="conv2_1", kh=3, kw=3, n_out=128, dh=1, dw=1, p=p) 36 conv2_2 = conv_op(conv2_1, name="conv2_2", kh=3, kw=3, n_out=128, dh=1, dw=1, p=p) 37 pool2 = mpool_op(conv2_2, name="pool2", kh=2, kw=2, dw=2, dh=2) 38 39 conv3_1 = conv_op(pool2, name="conv3_1", kh=3, kw=3, n_out=256, dh=1, dw=1, p=p) 40 conv3_2 = conv_op(conv3_1, name="conv3_2", kh=3, kw=3, n_out=256, dh=1, dw=1, p=p) 41 conv3_3 = conv_op(conv3_2, name="conv3_3", kh=3, kw=3, n_out=256, dh=1, dw=1, p=p) 42 pool3 = mpool_op(conv3_3, name="pool3", kh=2, kw=2, dw=2, dh=2) 43 44 conv4_1 = conv_op(pool3, name="conv4_1", kh=3, kw=3, n_out=512, dh=1, dw=1, p=p) 45 conv4_2 = conv_op(conv4_1, name="conv4_2", kh=3, kw=3, n_out=512, dh=1, dw=1, p=p) 46 conv4_3 = conv_op(conv4_2, name="conv4_3", kh=3, kw=3, n_out=512, dh=1, dw=1, p=p) 47 pool4 = mpool_op(conv4_3, name="pool4", kh=2, kw=2, dw=2, dh=2) 48 49 conv5_1 = conv_op(pool4, name="conv5_1", kh=3, kw=3, n_out=512, dh=1, dw=1, p=p) 50 conv5_2 = conv_op(conv5_1, name="conv5_2", kh=3, kw=3, n_out=512, dh=1, dw=1, p=p) 51 conv5_3 = conv_op(conv5_2, name="conv5_3", kh=3, kw=3, n_out=512, dh=1, dw=1, p=p) 52 pool5 = mpool_op(conv5_3, name="pool5", kh=2, kw=2, dw=2, dh=2) 53 54 shp = pool5.get_shape() 55 flattened_shape = shp[1].value * shp[2].value * shp[3].value 56 resh1 = tf.reshape(pool5, [-1, flattened_shape], name="resh1") 57 58 fc6 = fc_op(resh1, name="fc6", n_out=4096, p=p) 59 fc6_drop = tf.nn.dropout(fc6, keep_prob, name="fc6_drop") 60 61 fc7 = fc_op(fc6_drop, name="fc7", n_out=4096, p=p) 62 fc7_drop = tf.nn.dropout(fc7, keep_prob, name="fc7_drop") 63 64 fc8 = fc_op(fc7_drop, name="fc8", n_out=1000, p=p) 65 softmax = tf.nn.softmax(fc8) 66 predictions = tf.argmax(softmax, 1) 67 return predictions, softmax, fc8, p
slim实现
1 def vgg16(inputs): 2 with slim.arg_scope([slim.conv2d, slim.fully_connected], 3 activation_fn=tf.nn.relu, 4 weights_initializer=tf.truncated_normal_initializer(0.0, 0.01), 5 weights_regularizer=slim.l2_regularizer(0.0005)): 6 net = slim.repeat(inputs, 2, slim.conv2d, 64, [3, 3], scope='conv1') 7 net = slim.max_pool2d(net, [2, 2], scope='pool1') 8 net = slim.repeat(net, 2, slim.conv2d, 128, [3, 3], scope='conv2') 9 net = slim.max_pool2d(net, [2, 2], scope='pool2') 10 net = slim.repeat(net, 3, slim.conv2d, 256, [3, 3], scope='conv3') 11 net = slim.max_pool2d(net, [2, 2], scope='pool3') 12 net = slim.repeat(net, 3, slim.conv2d, 512, [3, 3], scope='conv4') 13 net = slim.max_pool2d(net, [2, 2], scope='pool4') 14 net = slim.repeat(net, 3, slim.conv2d, 512, [3, 3], scope='conv5') 15 net = slim.max_pool2d(net, [2, 2], scope='pool5') 16 net = slim.flatten(net) 17 net = slim.fully_connected(net, 4096, scope='fc6') 18 net = slim.dropout(net, 0.5, scope='dropout6') 19 net = slim.fully_connected(net, 4096, scope='fc7') 20 net = slim.dropout(net, 0.5, scope='dropout7') 21 net = slim.fully_connected(net, 1000, activation_fn=None, scope='fc8') 22 return net

【推荐】还在用 ECharts 开发大屏?试试这款永久免费的开源 BI 工具!
【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步