
mysql多线程备份与还原工具mydumper
(一)mydumper介绍
之前我们已经学过如何使用mysqldump备份恢复数据库:《mysql逻辑备份与还原工具mysqldump》,就目前来说,mysqldump是使用最广泛的MySQL备份工具。但经过个人长期使用下来,发现存在几个问题:
- 不支持多线程备份,也不支持多线程恢复。如果数据库较大,带来的问题就是备份恢复时间长。
- 备份出来的文件为一个整体,当需要某个表的数据时,无法从一个整体中取出。
这个时候我们可以考虑使用mydumper来备份数据库,相对于mysqldump,mydumper有什么特点呢?
- 并行性。并行备份,并行恢复,可以提升备份恢复速度
- 备份文件易于管理。备份出来的文件基于表为单位,一个sql文件记录一个表的信息。
- 一致性。维护所有线程的快照,提供准确的主日志和从日志位置
- 可管理性。支持PCRE(perl语音的正则表达式),用于指定数据库和表的包含/排除
(二)mydumper/myloader安装
建立mydumper的依赖项
# 安装开发工具: yum install -y cmake gcc gcc-c++ git make # 安装GLib,ZLib和PCRE的开发版本: yum install -y glib2-devel mysql-devel openssl-devel pcre-devel zlib-devel yum install -y mysql-devel yum install -y Percona-Server-devel-57 yum install -y mariadb-devel
安装mydumper/myloader
yum install https://github.com/maxbube/mydumper/releases/download/v0.10.5/mydumper-0.10.5-1.el7.x86_64.rpm
查看安装情况:
[root@hosta ~]# which mydumper /usr/bin/mydumper [root@hosta ~]# which myloader /usr/bin/myloader
(三)mydumper/myloader参数介绍
(3.1)mydumper常用参数
可以使用 mydumper --help 来查看相关使用参数。这里列出一些常用的参数:
[连接数据库参数]
--host , -h :待备份数据库主机名或者IP
--user , -u :待备份数据库用户名
--password , -p :数据库密码,特别注意,mydumper参数与值需要空格分开
--port , -P :数据库端口
--socket , -S :socket file文件
[备份范围参数]
--database , -B :dump的数据库
--tables-list , -T :要备份的表,多个表使用逗号分隔
--regex , -x :使用正则表达式去匹配符合条件的数据库和表
--build-empty-files , -e :如果表没有数据,则创建空文件
--insert-ignore , -N :dump行数据通过INSERT IGNORE INTO而不是INSERT INTO
--no-schemas , -m :不dump表的schema数据,即表的元数据
--no-data , -d :不dump表的行数据
--triggers , -G :dump触发器
--events , -E :dump EVENTS(定时任务)
--routines ,-R :dump存储过程和函数
--no-views ,-W :不dump视图
[长时间的查询]
--long-query-retries :尝试检查长时间的查询,默认0,不重试
--long-query-retry-interval :检查长时间查询的语句的间隔,默认60s
--long-query-guard , -l :长时间执行超时秒数,默认60s
--kill-long-query , -K :杀掉长时间的查询而不是终止dump操作
[锁]
--no-locks , -k :不使用临时共享读锁,会造成不一致性备份
--no-backup-locks :不使用Percona Backup Locks
--less-locking :使用较少的锁来实现备份。具体见:https://www.percona.com/blog/2014/06/13/mydumper-less-locking/
[其它]
--threads , -t :dump线程数量,默认是4
--outputdir , -o :dump文件输出路径,默认export-YYYYMMDD-HHMMSS
--rows , -r :将表拆分为N行的块,默认无限制(不拆分)
--compress , -c :压缩输出文件
--conpress-input , -C :使用客户端协议连接到MySQL server压缩,个人理解为dump的过程就开始进行压缩,以便于占用较少的带宽
--binlogs , -b :从server以及dump file得到binlog日志
--logfile , -L :mydumper操作的日志记录文件名
--[skip-]tz-utc :在dump文件头部设SET TIME_ZONE='+00:00'去允许,默认使用--skip-tz-utc服务器有不同的时区或者数据被移动到不同的时区,默认使用--skip-tz-utc
--chunk-filesize , -F :当数据文件大于多少MB时,进行文件分割
--complete-insert :使用包含列名的完整INSERT语句
(3.2)myloader常用参数
--threads , -t :用于还原数据的线程数,默认为4
--directory , -d :要还原的mydumper备份目录
--database , -B :要还原到哪个数据库
--queries-per-transaction , -q :恢复时多少行提交一次,默认1000行
--overwrite-tables , -o :在恢复时,如果表存在,则先删除
--enable-binlog , -e :启用binlog,这个参数非常重要,如果在主节点进行数据导入,同时同步到从节点,需要开启该参数,默认关闭
(四)使用mydumper/myloader备份还原数据库
(4.1)使用mydumper备份数据库
(4.1.1)备份数据库(全部、单个、多个)
-- 导出所有数据库,不包含mysql|test|information_schema|performance_schema|sys。且对trigger(G)、routines(R)、events(E)也导出,进行数据压缩(c),且8线程(t)导出 mydumper -u root -p 123456 -P 3306 -h 192.168.10.11 --regex '^(?!(mysql|test|information_schema|performance_schema|sys))' -G -R -E -c -t 8 -o /root/backup -- 备份单个数据库 mydumper -u root -p 123456 -P 3306 -h 192.168.10.11 --database lijiamandb -G -R -E -c -t 8 -o /root/backup -- 备份lijiamandb和db1数据库,且对trigger(G)、routines(R)、events(E)也导出,且8线程(t)导出 mydumper -u root -p 123456 -P 3306 -h 192.168.10.11 --regex 'lijiamandb|db1' -G -R -E -t 8 -o /root/backup
* 需要注意的是,备份单个数据库可以使用database参数进行,但是备份多个数据库该参数就不好用了,需要使用上面的则表达式
(4.1.2)备份表
-- 备份多个表 mydumper -u root -p 123456 -P 3306 -h 192.168.10.11 --database lijiamandb --tables-list test01,test02 -G -R -E -o /root/backup
备份所有数据库,备份的结果如下:
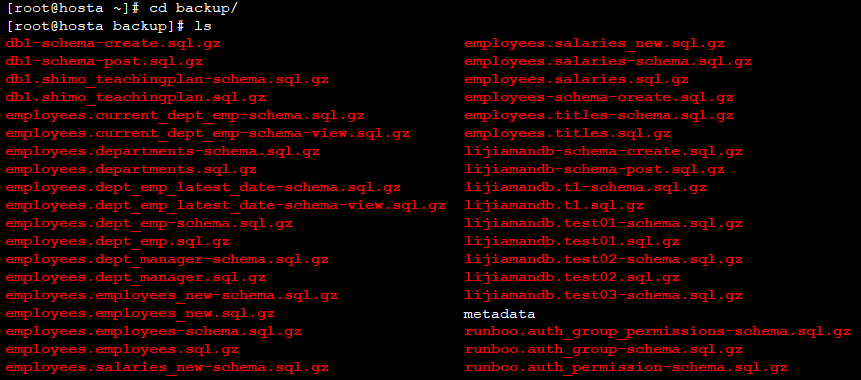
我们可以仔细观察这些文件,主要的文件类型有:
- metadata :当前备份到各个主从节点的位点(log、pos),这对于我们使用基于位点的同步是必要的
- {db_name}-schema-create.sql.gz :创建数据库的SQL
- {db_name}-schema-post.sql.gz :该数据库trigger(G)、routines(R)、events(E)的信息
- {db_name}.{table_name}-schema.sql.gz :表创建SQL
- {db_name}.{table_name}.sql.gz :表数据SQL
详细看一下其中的内容:
(Ⅰ)metadata:记录了主库机器从库的位点信息
Started dump at: 2021-05-23 00:10:15 SHOW MASTER STATUS: Log: master-bin.000065 Pos: 194 GTID:9d62e676-723d-11ea-83cf-000c29923d50:1-2, 9d6a0a08-723d-11ea-83a1-000c29fb6200:1-920094 SHOW SLAVE STATUS: Host: 192.168.10.12 Log: master-bin.000014 Pos: 194 GTID:9d62e676-723d-11ea-83cf-000c29923d50:1-2, 9d6a0a08-723d-11ea-83a1-000c29fb6200:1-920094 Finished dump at: 2021-05-23 00:11:08
(Ⅱ)lijiamandb-schema-create.sql :记录了创建lijiamandb数据库的SQL
CREATE DATABASE /*!32312 IF NOT EXISTS*/ `lijiamandb` /*!40100 DEFAULT CHARACTER SET utf8 */;
(Ⅲ)lijiamandb-schema-post.sql :记录了函数、过程、EVENT、Trigger等的创建SQL


SET @PREV_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT; SET @PREV_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS; SET @PREV_COLLATION_CONNECTION=@@COLLATION_CONNECTION; SET character_set_client = utf8mb4; SET character_set_results = utf8mb4; SET collation_connection = utf8mb4_general_ci; DROP PROCEDURE IF EXISTS `p_insert`; CREATE DEFINER=`root`@`%` PROCEDURE `p_insert`() BEGIN #Routine body goes here... DECLARE str1 varchar(30); DECLARE str2 varchar(30); DECLARE i int; set i = 0; while i < 100000 do set str1 = substring(md5(rand()),1,25); insert into test01(name) values(str1); set str2 = substring(md5(rand()),1,25); insert into test02(name) values(str2); set i = i + 1; end while; END; SET character_set_client = @PREV_CHARACTER_SET_CLIENT; SET character_set_results = @PREV_CHARACTER_SET_RESULTS; SET collation_connection = @PREV_COLLATION_CONNECTION; SET @PREV_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT; SET @PREV_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS; SET @PREV_COLLATION_CONNECTION=@@COLLATION_CONNECTION; SET character_set_client = utf8mb4; SET character_set_results = utf8mb4; SET collation_connection = utf8mb4_general_ci; DROP EVENT IF EXISTS `e_insert`; CREATE DEFINER=`root`@`%` EVENT `e_insert` ON SCHEDULE EVERY 90 SECOND STARTS '2020-04-23 10:43:47' ON COMPLETION PRESERVE ENABLE DO call p_insert(); SET character_set_client = @PREV_CHARACTER_SET_CLIENT; SET character_set_results = @PREV_CHARACTER_SET_RESULTS; SET collation_connection = @PREV_COLLATION_CONNECTION;
(Ⅳ)lijiamandb.t1-schema.sql:记录了表结构创建的SQL
/*!40101 SET NAMES binary*/; /*!40014 SET FOREIGN_KEY_CHECKS=0*/; /*!40103 SET TIME_ZONE='+00:00' */; CREATE TABLE `t1` ( `c1` char(1) NOT NULL, `c2` char(1) NOT NULL, `c3` char(1) NOT NULL, `c4` char(1) NOT NULL, `c5` char(1) NOT NULL, KEY `idx_c1234` (`c1`,`c2`,`c3`,`c4`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
(Ⅴ) lijiamandb.t1.sql:记录了t1的行数据
/*!40101 SET NAMES binary*/; /*!40014 SET FOREIGN_KEY_CHECKS=0*/; /*!40103 SET TIME_ZONE='+00:00' */; INSERT INTO `t1` VALUES ("1","1","1","1","1"), ("2","2","2","2","2"), ("3","3","3","3","3"), ("4","4","4","4","4"), ("5","5","5","5","5");
(4.2)使用myloader还原数据库
myloader导入数据
myloader -u root -p 123456 -P 3306 -h 192.168.10.11 -e -d /root/backup/ -t 8
(五)总结
本篇文章大致学习了mydumper的用法,发现有较多的优异特性。可以实现多线程备份恢复,备份文件基于表保存,便于后续使用。那么mydumper有没有缺点呢?我认为mydumper没有数据冲突的处理方案,mysqldump提供了insert-ingore来处理数据导入冲突,但是mydumper没有。如果要在已存在数据的表上进行增量导入,为了解决数据冲突,还是得使用mysqldump。
【完】

 浙公网安备 33010602011771号
浙公网安备 33010602011771号