
一步一步搭建MySQL高可用架构MHA
目录:
(一)认识MHA
(1.1)MHA概述
(1.2)MHA架构及其工作原理
(1.3)使用MHA的优势
(二)MHA安装--源码安装
(2.1)主机配置
(2.2)MySQL主从复制搭建(1主2从,启用gtid)
(2.3)安装MHA Node(在所有节点安装)
(2.4)安装MHA Manager(在监控节点安装)
(三)MHA配置(MHA Manager节点)
(3.1)SSH节点互信配置
(3.2)MHA配置文件
(3.3)VIP切换配置
(3.4)检查MHA配置是否正确
(四)MHA Manager相关脚本说明
(4.1)masterha_manager
(4.2)masterha_master_switch
(4.2.1)手动故障转移
(4.2.2)在线主从切换
(4.3)masterha_secondary_check
(五)MHA使用测试
(5.1)MHA故障切换测试(主节点服务器运行正常,数据库实例down)
(5.2)MHA故障切换测试(主节点服务器异常down)
(5.3)MHA手动故障切换测试
(5.4)MHA手动在线主从切换测试
(六)故障节点恢复
(七)其它
(7.1)定期清理日志的脚本
(7.2)选择哪个主机作为主节点
(一)认识MHA
(1.1)MHA概述
MHA是一套Perl编写的脚本,用来维护MySQL主从复制中Master节点的高可用。官方对其描述:Master High Availability Manager and tools for MySQL (MHA) for automating master failover and fast master switch.
主要功能有:
1.failover:主节点发生故障,将提升从节点为主节点。
2.switchover:主节点进行停机维护,需将主节点切换到新的服务器上。
主节点进行故障转移的难点:以一主多从的MySQL架构为例,如果主服务器崩溃,则需要选择一个最新的从服务器,将其升级为新的主节点。然后让其他从节点服务器从新的主服务器上开始复制。实际上,这是一个较为复杂的过程。即使可以识别到最新的从节点,其它从节点可能尚未收到所有二进制日志事件,如果复制开始后连接到新的主服务器,则这些从服务器将丢失事务,这将导致一致性问题。为避免一致性问题,需要在最新的主服务器启动之前,先识别丢失的binlog事件(尚未到达所有从服务器),并将其依次应用于每一个从服务器,此操作非常复杂,并且难以手动执行。
MHA的目标是在没有任何备用计算机的情况下,尽快使主机故障转移的恢复过程完全自动化。恢复过程包括:确定新的主服务器,识别从属服务器之间的差异中继日志事件,将必要的事件应用于新的主服务器,同步其它从属服务器并使它们从新的主服务器开始复制。根据复制延迟,MHA通常可以在10到30秒的停机事件内进行故障转移。
(1.2)MHA架构及其工作原理
MHA组件包含2部分:MHA Manager和MHA Node。其中:
Manager主要用于:监视MySQL主服务器,控制主服务器故障转移。一个Manager可以管理多个MHA集群;
Node主要用于:①保存以故障主节点的binlog;②通过比较relay log,查找从节点的日志差异,确定哪一个是最新节点,应用差异日志;③purge relay log。
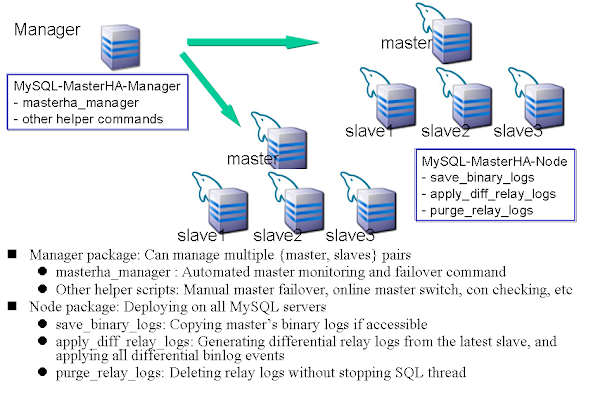
MHA工作原理为:
1.验证主从复制状态并识别当前的主服务器。确认主从节点的状态,如果主从节点数据库运行正常,则MHA Manager会一直监控主从节点的状态,如果从节点异常,则MHA停止运行;
2.如果MHA Manager连续3次无法连接到主服务器,则认为主服务器出现故障;
3.此时MHA会尝试通过MySQL的从节点连接到主节点,再次确认主节点运行状态,如果从节点也无法连接到主节点,说明MySQL主节点出现故障,启动主节点故障转移;
4.启动故障转移后,MHA Manager首先确认是否可以ssh连接到主节点,如果ssh可以访问,则所有从节点将从主节点拷贝还未执行的binlog日志到节点上执行;如果ssh也无法访问到主节点,则MHA会到从节点执行"show slave status"判断哪个从节点应用到了最新的日志,然后其他节点到该节点拷贝relay log到自己节点应用,最终实现所有从节点应用日志到同一时间;
5.启动选主机制,选择出主节点,启动VIP漂移
6.将其他从接节点指到新的主节点
(1.3)使用MHA的优势
使用MHA的主要优势如下:
- 主节点故障转移和从节点升级快速完成。在从节点复制延迟较小的情况下,通常10~30S即可完成故障转移;
- 主节点崩溃不会导致数据不一致。从节点之间可以识别relay log的日志事件,并应用于每一个主机,保证所有从节点数据一致;
- 无需修改当前的MySQL配置;
- 无性能损失。MHA默认每隔3s向MySQL主节点发送一个简单的查询,不会过多的消耗服务器性能;
- 适用于任何存储引擎。
(二)MHA安装--源码安装
基础资源信息:
| IP地址 | 主机名称 | 操作系统 | 用途 |
| 192.168.10.5 | monitor | centos 7.4 | MHA Manager主机 |
| 192.168.10.11 | node1 | centos 7.4 | MySQL主从复制,主节点 |
| 192.168.10.12 | node2 | centos 7.4 | MySQL主从复制,从节点,候选主节点 |
| 192.168.10.13 | node3 | centos 7.4 | MySQL主从复制,从节点 |
| 192.168.10.10 | / | / | 虚拟IP,用来做主节点IP漂移 |
(2.1)主机配置
1.配置/etc/hosts文件
[root@monitor ~]# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.10.5 monitor 192.168.10.11 node1 192.168.10.12 node2 192.168.10.13 node3
2.配置epel源,MHA依赖于其它包使用默认的centos yum源无法安装全部的依赖包,建议添加epel源
# RHEL/Centos7源 yum install -y https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm # 使新配置的源生效 yum clean yum makecache
(2.2)MySQL主从复制搭建(1主2从,启用gtid)
MySQL版本:MySQL 5.7
MHA本身并不构建复制环境,需要自己搭建MySQL的主从复制环境,这里构建基于GTID的主从复制。
MySQL安装链接:https://www.cnblogs.com/lijiaman/p/10743102.html
MySQL基于GDIT的主从搭建:https://www.cnblogs.com/lijiaman/p/12315379.html
MySQL参数配置如下:

[mysql] # 设置mysql客户端默认字符集 default-character-set=utf8 [mysqld] ##### 1.基础参数 ####### # 是禁用dns解析,mysql的授权表中就不能使用主机名了,只能使用IP skip-name-resolve # 设置3306端口 port = 3306 # 设置mysql的安装目录 basedir=/mysql # 设置mysql数据库的数据的存放目录 datadir=/mysql/data # 允许最大连接数 max_connections=1000 # 服务端使用的字符集默认为8比特编码的latin1字符集 character-set-server=utf8 # 创建新表时将使用的默认存储引擎 default-storage-engine=INNODB # 表名不区分大小写 lower_case_table_names=1 max_allowed_packet=16M # error log 使用系统时区 log_timestamps = 1 # 使用root用户启动mysql数据库 user = root ##### 2.复制相关参数配置 ##### server_id = 1 # 要求所有节点不相同 binlog_format=ROW log_bin=/mysql/binlog/node1-bin max_binlog_size=1G sync_binlog=1 innodb_flush_log_at_trx_commit=1 ##### 3.启用GTID相关参数 ##### gtid_mode=ON enforce-gtid-consistency=ON ##### 4.MHA要求参数 ##### # 0表示禁止 SQL 线程在执行完一个 relay log 后自动将其删除,对于MHA场景下,对于某些滞后从库的恢复依赖于其他从库的relay log,因此采取禁用自动删除功能 relay_log_purge = 0 # 从节点需设置为只读 # read_only = 1
备注:3个节点不同的参数为:log_bin、server_id、read_only
(2.3)安装MHA Node(在所有节点安装)
MHA可以使用源码编译安装,也可以使用rpm包直接,这里使用源码编译安装。
STEP1:下载MHA Node源码安装包
进入github网站:https://github.com/yoshinorim/mha4mysql-node/releases/tag/v0.58,下载最新版本的MHA Node。
STEP2:安装MHA Node的依赖包,需要在所有节点都进行安装
# 官方文档中提示,mha node安装只依赖于该包 yum install -y perl-DBD-MySQL # 在实际安装过程中,发现还需要该包 yum install -y perl-CPAN
STEP3:安装mha node
# 解压安装包 $ tar -xzvf mha4mysql-node-0.58.tar.gz # 安装MHA Node $ perl Makefile.PL $ make $ make install
Note:在实际安装过程中,报错
[root@node1 mha4mysql-node-0.58]# perl Makefile.PL
Can't locate ExtUtils/MakeMaker.pm in @INC (@INC contains: inc /usr/local/lib64/perl5 /usr/local/share/perl5 /usr/lib64/perl5/vendor_perl /usr/share/perl5/vendor_perl /usr/lib64/perl5 /usr/share/perl5 .) at inc/Module/Install/Can.pm line 5.
BEGIN failed--compilation aborted at inc/Module/Install/Can.pm line 5.
Compilation failed in require at inc/Module/Install.pm line 307.
Can't locate ExtUtils/MakeMaker.pm in @INC (@INC contains: inc /usr/local/lib64/perl5 /usr/local/share/perl5 /usr/lib64/perl5/vendor_perl /usr/share/perl5/vendor_perl /usr/lib64/perl5 /usr/share/perl5 .) at inc/Module/Install/Makefile.pm line 4.
BEGIN failed--compilation aborted at inc/Module/Install/Makefile.pm line 4.
Compilation failed in require at inc/Module/Install.pm line 307.
Can't locate ExtUtils/MM_Unix.pm in @INC (@INC contains: inc /usr/local/lib64/perl5 /usr/local/share/perl5 /usr/lib64/perl5/vendor_perl /usr/share/perl5/vendor_perl /usr/lib64/perl5 /usr/share/perl5 .) at inc/Module/Install/Metadata.pm line 322.
解决方案:
[root@node1 mha4mysql-node-0.58]# yum install -y perl-CPAN
STEP4:安装确认
安装完成之后,会在所有节点的/usr/local/bin/目录下生成node相关的脚本
[root@node3 bin]# cd /usr/local/bin/ [root@node3 bin]# ll -r-xr-xr-x. 1 root root 17639 Mar 29 15:04 apply_diff_relay_logs -r-xr-xr-x. 1 root root 4807 Mar 29 15:04 filter_mysqlbinlog -r-xr-xr-x. 1 root root 8337 Mar 29 15:04 purge_relay_logs -r-xr-xr-x. 1 root root 7525 Mar 29 15:04 save_binary_logs
MHA Node整个安装过程操作日志:


1 [root@monitor ~]# tar -xzvf mha4mysql-node-0.58.tar.gz 2 mha4mysql-node-0.58/ 3 mha4mysql-node-0.58/inc/ 4 mha4mysql-node-0.58/inc/Module/ 5 mha4mysql-node-0.58/inc/Module/Install/ 6 mha4mysql-node-0.58/inc/Module/Install/Fetch.pm 7 mha4mysql-node-0.58/inc/Module/Install/Metadata.pm 8 mha4mysql-node-0.58/inc/Module/Install/AutoInstall.pm 9 mha4mysql-node-0.58/inc/Module/Install/Win32.pm 10 mha4mysql-node-0.58/inc/Module/Install/WriteAll.pm 11 mha4mysql-node-0.58/inc/Module/Install/Can.pm 12 mha4mysql-node-0.58/inc/Module/Install/Include.pm 13 mha4mysql-node-0.58/inc/Module/Install/Makefile.pm 14 mha4mysql-node-0.58/inc/Module/Install/Scripts.pm 15 mha4mysql-node-0.58/inc/Module/Install/Base.pm 16 mha4mysql-node-0.58/inc/Module/AutoInstall.pm 17 mha4mysql-node-0.58/inc/Module/Install.pm 18 mha4mysql-node-0.58/debian/ 19 mha4mysql-node-0.58/debian/compat 20 mha4mysql-node-0.58/debian/changelog 21 mha4mysql-node-0.58/debian/rules 22 mha4mysql-node-0.58/debian/copyright 23 mha4mysql-node-0.58/debian/control 24 mha4mysql-node-0.58/bin/ 25 mha4mysql-node-0.58/bin/purge_relay_logs 26 mha4mysql-node-0.58/bin/filter_mysqlbinlog 27 mha4mysql-node-0.58/bin/save_binary_logs 28 mha4mysql-node-0.58/bin/apply_diff_relay_logs 29 mha4mysql-node-0.58/AUTHORS 30 mha4mysql-node-0.58/MANIFEST 31 mha4mysql-node-0.58/t/ 32 mha4mysql-node-0.58/t/perlcriticrc 33 mha4mysql-node-0.58/t/99-perlcritic.t 34 mha4mysql-node-0.58/README 35 mha4mysql-node-0.58/COPYING 36 mha4mysql-node-0.58/META.yml 37 mha4mysql-node-0.58/lib/ 38 mha4mysql-node-0.58/lib/MHA/ 39 mha4mysql-node-0.58/lib/MHA/BinlogPosFinderElp.pm 40 mha4mysql-node-0.58/lib/MHA/BinlogPosFindManager.pm 41 mha4mysql-node-0.58/lib/MHA/BinlogPosFinderXid.pm 42 mha4mysql-node-0.58/lib/MHA/BinlogPosFinder.pm 43 mha4mysql-node-0.58/lib/MHA/BinlogHeaderParser.pm 44 mha4mysql-node-0.58/lib/MHA/NodeConst.pm 45 mha4mysql-node-0.58/lib/MHA/NodeUtil.pm 46 mha4mysql-node-0.58/lib/MHA/SlaveUtil.pm 47 mha4mysql-node-0.58/lib/MHA/BinlogManager.pm 48 mha4mysql-node-0.58/Makefile.PL 49 mha4mysql-node-0.58/rpm/ 50 mha4mysql-node-0.58/rpm/masterha_node.spec 51 [root@monitor ~]# 52 [root@monitor ~]# 53 [root@monitor ~]# ll 54 total 697468 55 -rw-------. 1 root root 1325 Oct 24 2019 anaconda-ks.cfg 56 -rw-r--r--. 1 root root 119801 Mar 29 15:14 mha4mysql-manager-0.58.tar.gz 57 drwxr-xr-x. 8 lijiaman lijiaman 168 Mar 23 2018 mha4mysql-node-0.58 58 -rw-r--r--. 1 root root 56220 Mar 29 15:14 mha4mysql-node-0.58.tar.gz 59 -rw-r--r--. 1 root root 714022690 Mar 17 16:28 mysql-5.7.27-el7-x86_64.tar.gz 60 [root@monitor ~]# cd mha4mysql- 61 -bash: cd: mha4mysql-: No such file or directory 62 [root@monitor ~]# cd mha4mysql-node-0.58 63 [root@monitor mha4mysql-node-0.58]# ls 64 AUTHORS bin COPYING debian inc lib Makefile.PL MANIFEST META.yml README rpm t 65 [root@monitor mha4mysql-node-0.58]# perl Makefile.PL 66 Can't locate ExtUtils/MakeMaker.pm in @INC (@INC contains: inc /usr/local/lib64/perl5 /usr/local/share/perl5 /usr/lib64/perl5/vendor_perl /usr/share/perl5/vendor_perl /usr/lib64/perl5 /usr/share/perl5 .) at inc/Module/Install/Can.pm line 5. 67 BEGIN failed--compilation aborted at inc/Module/Install/Can.pm line 5. 68 Compilation failed in require at inc/Module/Install.pm line 307. 69 Can't locate ExtUtils/MakeMaker.pm in @INC (@INC contains: inc /usr/local/lib64/perl5 /usr/local/share/perl5 /usr/lib64/perl5/vendor_perl /usr/share/perl5/vendor_perl /usr/lib64/perl5 /usr/share/perl5 .) at inc/Module/Install/Makefile.pm line 4. 70 BEGIN failed--compilation aborted at inc/Module/Install/Makefile.pm line 4. 71 Compilation failed in require at inc/Module/Install.pm line 307. 72 Can't locate ExtUtils/MM_Unix.pm in @INC (@INC contains: inc /usr/local/lib64/perl5 /usr/local/share/perl5 /usr/lib64/perl5/vendor_perl /usr/share/perl5/vendor_perl /usr/lib64/perl5 /usr/share/perl5 .) at inc/Module/Install/Metadata.pm line 322. 73 [root@monitor mha4mysql-node-0.58]# 74 [root@monitor mha4mysql-node-0.58]# 75 [root@monitor mha4mysql-node-0.58]# yum install -y perl-CPAN 76 Loaded plugins: fastestmirror 77 Loading mirror speeds from cached hostfile 78 * base: mirrors.cqu.edu.cn 79 * epel: mirrors.bfsu.edu.cn 80 * extras: mirrors.cqu.edu.cn 81 ... 略 ... 82 Installed: 83 perl-CPAN.noarch 0:1.9800-299.el7_9 84 85 Dependency Installed: 86 gdbm-devel.x86_64 0:1.10-8.el7 libdb-devel.x86_64 0:5.3.21-25.el7 perl-Digest.noarch 0:1.17-245.el7 87 perl-Digest-SHA.x86_64 1:5.85-4.el7 perl-ExtUtils-Install.noarch 0:1.58-299.el7_9 perl-ExtUtils-MakeMaker.noarch 0:6.68-3.el7 88 perl-ExtUtils-Manifest.noarch 0:1.61-244.el7 perl-ExtUtils-ParseXS.noarch 1:3.18-3.el7 perl-Test-Harness.noarch 0:3.28-3.el7 89 perl-devel.x86_64 4:5.16.3-299.el7_9 perl-local-lib.noarch 0:1.008010-4.el7 pyparsing.noarch 0:1.5.6-9.el7 90 systemtap-sdt-devel.x86_64 0:4.0-13.el7 91 92 Dependency Updated: 93 libdb.x86_64 0:5.3.21-25.el7 libdb-utils.x86_64 0:5.3.21-25.el7 94 95 Complete! 96 [root@monitor mha4mysql-node-0.58]# perl Makefile.PL 97 *** Module::AutoInstall version 1.06 98 *** Checking for Perl dependencies... 99 [Core Features] 100 - DBI ...loaded. (1.627) 101 - DBD::mysql ...loaded. (4.023) 102 *** Module::AutoInstall configuration finished. 103 Checking if your kit is complete... 104 Looks good 105 Writing Makefile for mha4mysql::node 106 [root@monitor mha4mysql-node-0.58]# make 107 cp lib/MHA/BinlogManager.pm blib/lib/MHA/BinlogManager.pm 108 cp lib/MHA/BinlogPosFindManager.pm blib/lib/MHA/BinlogPosFindManager.pm 109 cp lib/MHA/BinlogPosFinderXid.pm blib/lib/MHA/BinlogPosFinderXid.pm 110 cp lib/MHA/BinlogHeaderParser.pm blib/lib/MHA/BinlogHeaderParser.pm 111 cp lib/MHA/BinlogPosFinder.pm blib/lib/MHA/BinlogPosFinder.pm 112 cp lib/MHA/BinlogPosFinderElp.pm blib/lib/MHA/BinlogPosFinderElp.pm 113 cp lib/MHA/NodeUtil.pm blib/lib/MHA/NodeUtil.pm 114 cp lib/MHA/SlaveUtil.pm blib/lib/MHA/SlaveUtil.pm 115 cp lib/MHA/NodeConst.pm blib/lib/MHA/NodeConst.pm 116 cp bin/filter_mysqlbinlog blib/script/filter_mysqlbinlog 117 /usr/bin/perl "-Iinc" -MExtUtils::MY -e 'MY->fixin(shift)' -- blib/script/filter_mysqlbinlog 118 cp bin/apply_diff_relay_logs blib/script/apply_diff_relay_logs 119 /usr/bin/perl "-Iinc" -MExtUtils::MY -e 'MY->fixin(shift)' -- blib/script/apply_diff_relay_logs 120 cp bin/purge_relay_logs blib/script/purge_relay_logs 121 /usr/bin/perl "-Iinc" -MExtUtils::MY -e 'MY->fixin(shift)' -- blib/script/purge_relay_logs 122 cp bin/save_binary_logs blib/script/save_binary_logs 123 /usr/bin/perl "-Iinc" -MExtUtils::MY -e 'MY->fixin(shift)' -- blib/script/save_binary_logs 124 Manifying blib/man1/filter_mysqlbinlog.1 125 Manifying blib/man1/apply_diff_relay_logs.1 126 Manifying blib/man1/purge_relay_logs.1 127 Manifying blib/man1/save_binary_logs.1 128 [root@monitor mha4mysql-node-0.58]# make install 129 Installing /usr/local/share/perl5/MHA/BinlogManager.pm 130 Installing /usr/local/share/perl5/MHA/BinlogPosFindManager.pm 131 Installing /usr/local/share/perl5/MHA/BinlogPosFinderXid.pm 132 Installing /usr/local/share/perl5/MHA/BinlogHeaderParser.pm 133 Installing /usr/local/share/perl5/MHA/BinlogPosFinder.pm 134 Installing /usr/local/share/perl5/MHA/BinlogPosFinderElp.pm 135 Installing /usr/local/share/perl5/MHA/NodeUtil.pm 136 Installing /usr/local/share/perl5/MHA/SlaveUtil.pm 137 Installing /usr/local/share/perl5/MHA/NodeConst.pm 138 Installing /usr/local/share/man/man1/filter_mysqlbinlog.1 139 Installing /usr/local/share/man/man1/apply_diff_relay_logs.1 140 Installing /usr/local/share/man/man1/purge_relay_logs.1 141 Installing /usr/local/share/man/man1/save_binary_logs.1 142 Installing /usr/local/bin/filter_mysqlbinlog 143 Installing /usr/local/bin/apply_diff_relay_logs 144 Installing /usr/local/bin/purge_relay_logs 145 Installing /usr/local/bin/save_binary_logs 146 Appending installation info to /usr/lib64/perl5/perllocal.pod 147 [root@monitor mha4mysql-node-0.58]#
(2.4)安装MHA Manager(在监控节点安装)
STEP1:下载MHA Manager源码安装包
进入github网站:https://github.com/yoshinorim/mha4mysql-manager/releases/tag/v0.58,下载最新版本的MHA Manager。
STEP2:安装MHA Manager的依赖包
需要特别注意,MHA Manager也依赖于MHA Node,因此需要在Manager节点也安装node。
# 官方文档中提示,mha node安装依赖包 yum install -y perl-DBD-MySQL yum install -y perl-Config-Tiny yum install -y perl-Log-Dispatch yum install -y perl-Parallel-ForkManager
STEP3:安装mha manager
# 解压安装包 $ tar -zxf mha4mysql-manager-0.58.tar.gz # 安装MHA Manager $ perl Makefile.PL $ make $ make install
STEP4:安装确认
安装完成之后,会在MHA Manager节点的/usr/local/bin/目录下生成manager相关的脚本
[root@monitor mha4mysql-manager-0.58]# cd /usr/local/bin/ [root@monitor bin]# ll -r-xr-xr-x. 1 root root 17639 Mar 29 15:17 apply_diff_relay_logs -r-xr-xr-x. 1 root root 4807 Mar 29 15:17 filter_mysqlbinlog -r-xr-xr-x. 1 root root 1995 Mar 29 15:20 masterha_check_repl -r-xr-xr-x. 1 root root 1779 Mar 29 15:20 masterha_check_ssh -r-xr-xr-x. 1 root root 1865 Mar 29 15:20 masterha_check_status -r-xr-xr-x. 1 root root 3201 Mar 29 15:20 masterha_conf_host -r-xr-xr-x. 1 root root 2517 Mar 29 15:20 masterha_manager -r-xr-xr-x. 1 root root 2165 Mar 29 15:20 masterha_master_monitor -r-xr-xr-x. 1 root root 2373 Mar 29 15:20 masterha_master_switch -r-xr-xr-x. 1 root root 5172 Mar 29 15:20 masterha_secondary_check -r-xr-xr-x. 1 root root 1739 Mar 29 15:20 masterha_stop -r-xr-xr-x. 1 root root 8337 Mar 29 15:17 purge_relay_logs -r-xr-xr-x. 1 root root 7525 Mar 29 15:17 save_binary_logs
MHA Manager整个安装过程操作日志:
1 [root@monitor ~]# tar -xzvf mha4mysql-manager-0.58.tar.gz 2 mha4mysql-manager-0.58/ 3 mha4mysql-manager-0.58/inc/ 4 mha4mysql-manager-0.58/inc/Module/ 5 mha4mysql-manager-0.58/inc/Module/Install/ 6 mha4mysql-manager-0.58/inc/Module/Install/Fetch.pm 7 mha4mysql-manager-0.58/inc/Module/Install/Metadata.pm 8 mha4mysql-manager-0.58/inc/Module/Install/AutoInstall.pm 9 mha4mysql-manager-0.58/inc/Module/Install/Win32.pm 10 mha4mysql-manager-0.58/inc/Module/Install/WriteAll.pm 11 mha4mysql-manager-0.58/inc/Module/Install/Can.pm 12 mha4mysql-manager-0.58/inc/Module/Install/Include.pm 13 mha4mysql-manager-0.58/inc/Module/Install/Makefile.pm 14 mha4mysql-manager-0.58/inc/Module/Install/Scripts.pm 15 mha4mysql-manager-0.58/inc/Module/Install/Base.pm 16 mha4mysql-manager-0.58/inc/Module/AutoInstall.pm 17 mha4mysql-manager-0.58/inc/Module/Install.pm 18 mha4mysql-manager-0.58/debian/ 19 mha4mysql-manager-0.58/debian/compat 20 mha4mysql-manager-0.58/debian/changelog 21 mha4mysql-manager-0.58/debian/docs 22 mha4mysql-manager-0.58/debian/rules 23 mha4mysql-manager-0.58/debian/copyright 24 mha4mysql-manager-0.58/debian/control 25 mha4mysql-manager-0.58/bin/ 26 mha4mysql-manager-0.58/bin/masterha_check_status 27 mha4mysql-manager-0.58/bin/masterha_check_ssh 28 mha4mysql-manager-0.58/bin/masterha_master_monitor 29 mha4mysql-manager-0.58/bin/masterha_manager 30 mha4mysql-manager-0.58/bin/masterha_master_switch 31 mha4mysql-manager-0.58/bin/masterha_stop 32 mha4mysql-manager-0.58/bin/masterha_secondary_check 33 mha4mysql-manager-0.58/bin/masterha_check_repl 34 mha4mysql-manager-0.58/bin/masterha_conf_host 35 mha4mysql-manager-0.58/AUTHORS 36 mha4mysql-manager-0.58/MANIFEST 37 mha4mysql-manager-0.58/tests/ 38 mha4mysql-manager-0.58/tests/intro.txt 39 mha4mysql-manager-0.58/tests/t/ 40 mha4mysql-manager-0.58/tests/t/t_online_3tier.sh 41 mha4mysql-manager-0.58/tests/t/t_mm_ro_fail.sh 42 mha4mysql-manager-0.58/tests/t/t_large_data_slow.sh 43 mha4mysql-manager-0.58/tests/t/t_recover_master_fail.sh 44 mha4mysql-manager-0.58/tests/t/t_4tier.sh 45 mha4mysql-manager-0.58/tests/t/t_online_slave_sql_stop.sh 46 mha4mysql-manager-0.58/tests/t/t_online_3tier_slave.sh 47 mha4mysql-manager-0.58/tests/t/grant_nopass.sql 48 mha4mysql-manager-0.58/tests/t/t_manual.sh 49 mha4mysql-manager-0.58/tests/t/t_mm_noslaves.sh 50 mha4mysql-manager-0.58/tests/t/t_online_mm_3tier.sh 51 mha4mysql-manager-0.58/tests/t/t_advisory_select.sh 52 mha4mysql-manager-0.58/tests/t/mha_test_mm_online.cnf.tmpl 53 mha4mysql-manager-0.58/tests/t/t_ignore_nostart.sh 54 mha4mysql-manager-0.58/tests/t/t_dual_master_error.sh 55 mha4mysql-manager-0.58/tests/t/t_large_data_sql_fail.sh 56 mha4mysql-manager-0.58/tests/t/t_mm_subm_dead.sh 57 mha4mysql-manager-0.58/tests/t/t_online_3tier_slave_keep.sh 58 mha4mysql-manager-0.58/tests/t/mha_test_connect.cnf.tmpl 59 mha4mysql-manager-0.58/tests/t/t_latest_recovery3.sh 60 mha4mysql-manager-0.58/tests/t/t_save_master_log.sh 61 mha4mysql-manager-0.58/tests/t/t_needsync_1_ssh.sh 62 mha4mysql-manager-0.58/tests/t/t_mm.sh 63 mha4mysql-manager-0.58/tests/t/t_needsync_flush_slave.sh 64 mha4mysql-manager-0.58/tests/t/t_online_slave_pass.sh 65 mha4mysql-manager-0.58/tests/t/t_ignore_start.sh 66 mha4mysql-manager-0.58/tests/t/my.cnf 67 mha4mysql-manager-0.58/tests/t/t_large_data_sql_stop.sh 68 mha4mysql-manager-0.58/tests/t/t_filter_incorrect.sh 69 mha4mysql-manager-0.58/tests/t/start_m.sh 70 mha4mysql-manager-0.58/tests/t/t_large_data_bulk.sh 71 mha4mysql-manager-0.58/tests/t/master_ip_failover 72 mha4mysql-manager-0.58/tests/t/t_large_data.sh 73 mha4mysql-manager-0.58/tests/t/t_new_master_heavy_wait.sh 74 mha4mysql-manager-0.58/tests/t/t_data_io_error.sh 75 mha4mysql-manager-0.58/tests/t/t_large_data_tran.sh 76 mha4mysql-manager-0.58/tests/t/t_needsync_1_pass.sh 77 mha4mysql-manager-0.58/tests/t/t_save_master_log_pass.sh 78 mha4mysql-manager-0.58/tests/t/my-row.cnf 79 mha4mysql-manager-0.58/tests/t/t_online_slave.sh 80 mha4mysql-manager-0.58/tests/t/t_latest_recovery2.sh 81 mha4mysql-manager-0.58/tests/t/t_online_filter.sh 82 mha4mysql-manager-0.58/tests/t/stop_s1.sh 83 mha4mysql-manager-0.58/tests/t/init.sh 84 mha4mysql-manager-0.58/tests/t/t_ignore_recovery1.sh 85 mha4mysql-manager-0.58/tests/t/t_online_busy.sh 86 mha4mysql-manager-0.58/tests/t/t_keep_relay_log_purge.sh 87 mha4mysql-manager-0.58/tests/t/t_needsync_1.sh 88 mha4mysql-manager-0.58/tests/t/t_apply_many_logs.sh 89 mha4mysql-manager-0.58/tests/t/t_apply_many_logs3.sh 90 mha4mysql-manager-0.58/tests/t/t_slave_stop.sh 91 mha4mysql-manager-0.58/tests/t/t_slave_incorrect.sh 92 mha4mysql-manager-0.58/tests/t/bulk_tran_insert.pl 93 mha4mysql-manager-0.58/tests/t/mha_test_multi_online.cnf.tmpl 94 mha4mysql-manager-0.58/tests/t/stop_m.sh 95 mha4mysql-manager-0.58/tests/t/start_s4.sh 96 mha4mysql-manager-0.58/tests/t/t_4tier_subm_dead.sh 97 mha4mysql-manager-0.58/tests/t/mha_test_online.cnf.tmpl 98 mha4mysql-manager-0.58/tests/t/t_slave_sql_start3.sh 99 mha4mysql-manager-0.58/tests/t/run_bg.sh 100 mha4mysql-manager-0.58/tests/t/t_needsync_2_pass.sh 101 mha4mysql-manager-0.58/tests/t/t_apply_many_logs2.sh 102 mha4mysql-manager-0.58/tests/t/mha_test_mm.cnf.tmpl 103 mha4mysql-manager-0.58/tests/t/stop_s4.sh 104 mha4mysql-manager-0.58/tests/t/t_needsync_1_nocm.sh 105 mha4mysql-manager-0.58/tests/t/t_ignore_recovery4.sh 106 mha4mysql-manager-0.58/tests/t/t_advisory_connect.sh 107 mha4mysql-manager-0.58/tests/t/t_normal_crash.sh 108 mha4mysql-manager-0.58/tests/t/t_mm_normal_skip_reset.sh 109 mha4mysql-manager-0.58/tests/t/t_slave_sql_start2.sh 110 mha4mysql-manager-0.58/tests/t/t_slave_sql_start.sh 111 mha4mysql-manager-0.58/tests/t/t_normal_crash_nocm.sh 112 mha4mysql-manager-0.58/tests/t/t_mm_3tier_subm_dead.sh 113 mha4mysql-manager-0.58/tests/t/mha_test_err1.cnf.tmpl 114 mha4mysql-manager-0.58/tests/t/mha_test_reset.cnf.tmpl 115 mha4mysql-manager-0.58/tests/t/t_needsync_fail.sh 116 mha4mysql-manager-0.58/tests/t/t_needsync_1_nopass.sh 117 mha4mysql-manager-0.58/tests/t/start_s1.sh 118 mha4mysql-manager-0.58/tests/t/t_needsync_flush.sh 119 mha4mysql-manager-0.58/tests/t/run.sh 120 mha4mysql-manager-0.58/tests/t/master_ip_failover_blank 121 mha4mysql-manager-0.58/tests/t/mha_test.cnf.tmpl 122 mha4mysql-manager-0.58/tests/t/t_save_master_log_ssh.sh 123 mha4mysql-manager-0.58/tests/t/kill_m.sh 124 mha4mysql-manager-0.58/tests/t/t_online_slave_fail.sh 125 mha4mysql-manager-0.58/tests/t/t_binary.sh 126 mha4mysql-manager-0.58/tests/t/t_needsync_flush3.sh 127 mha4mysql-manager-0.58/tests/t/t_recover_slave_fail.sh 128 mha4mysql-manager-0.58/tests/t/mha_test_ignore.cnf.tmpl 129 mha4mysql-manager-0.58/tests/t/t_ignore_recovery3.sh 130 mha4mysql-manager-0.58/tests/t/force_start_m.sh 131 mha4mysql-manager-0.58/tests/t/t_recover_slave_ok.sh 132 mha4mysql-manager-0.58/tests/t/t_mm_normal.sh 133 mha4mysql-manager-0.58/tests/t/start_s2.sh 134 mha4mysql-manager-0.58/tests/t/t_online_mm_3tier_slave.sh 135 mha4mysql-manager-0.58/tests/t/insert.pl 136 mha4mysql-manager-0.58/tests/t/grant.sql 137 mha4mysql-manager-0.58/tests/t/stop_s2.sh 138 mha4mysql-manager-0.58/tests/t/waitpid 139 mha4mysql-manager-0.58/tests/t/t_mm_subm_dead_many.sh 140 mha4mysql-manager-0.58/tests/t/t_ignore_recovery2.sh 141 mha4mysql-manager-0.58/tests/t/tran_insert.pl 142 mha4mysql-manager-0.58/tests/t/insert_binary.pl 143 mha4mysql-manager-0.58/tests/t/t_online_mm.sh 144 mha4mysql-manager-0.58/tests/t/mha_test_nopass.cnf.tmpl 145 mha4mysql-manager-0.58/tests/t/t_needsync_2.sh 146 mha4mysql-manager-0.58/tests/t/mha_test_online_pass.cnf.tmpl 147 mha4mysql-manager-0.58/tests/t/t_needsync_2_ssh.sh 148 mha4mysql-manager-0.58/tests/t/mha_test_multi.cnf.tmpl 149 mha4mysql-manager-0.58/tests/t/run_tests 150 mha4mysql-manager-0.58/tests/t/mha_test_latest.cnf.tmpl 151 mha4mysql-manager-0.58/tests/t/t_online_mm_skip_reset.sh 152 mha4mysql-manager-0.58/tests/t/t_online_normal.sh 153 mha4mysql-manager-0.58/tests/t/env.sh 154 mha4mysql-manager-0.58/tests/t/t_needsync_flush2.sh 155 mha4mysql-manager-0.58/tests/t/t_conf.sh 156 mha4mysql-manager-0.58/tests/t/t_mm_subm_dead_noslave.sh 157 mha4mysql-manager-0.58/tests/t/mha_test_ssh.cnf.tmpl 158 mha4mysql-manager-0.58/tests/t/mha_test_err2.cnf.tmpl 159 mha4mysql-manager-0.58/tests/t/t_mm_3tier.sh 160 mha4mysql-manager-0.58/tests/t/t_no_relay_log.sh 161 mha4mysql-manager-0.58/tests/t/change_relay_log_info.sh 162 mha4mysql-manager-0.58/tests/t/t_new_master_heavy.sh 163 mha4mysql-manager-0.58/tests/t/mha_test_pass.cnf.tmpl 164 mha4mysql-manager-0.58/tests/t/t_latest_recovery1.sh 165 mha4mysql-manager-0.58/tests/t/t_recover_slave_fail2.sh 166 mha4mysql-manager-0.58/tests/t/t_large_data_bulk_slow.sh 167 mha4mysql-manager-0.58/tests/t/check 168 mha4mysql-manager-0.58/tests/t/t_large_data_slow2.sh 169 mha4mysql-manager-0.58/tests/run_suites.sh 170 mha4mysql-manager-0.58/t/ 171 mha4mysql-manager-0.58/t/perlcriticrc 172 mha4mysql-manager-0.58/t/99-perlcritic.t 173 mha4mysql-manager-0.58/README 174 mha4mysql-manager-0.58/samples/ 175 mha4mysql-manager-0.58/samples/scripts/ 176 mha4mysql-manager-0.58/samples/scripts/master_ip_failover 177 mha4mysql-manager-0.58/samples/scripts/power_manager 178 mha4mysql-manager-0.58/samples/scripts/send_report 179 mha4mysql-manager-0.58/samples/scripts/master_ip_online_change 180 mha4mysql-manager-0.58/samples/conf/ 181 mha4mysql-manager-0.58/samples/conf/app1.cnf 182 mha4mysql-manager-0.58/samples/conf/masterha_default.cnf 183 mha4mysql-manager-0.58/COPYING 184 mha4mysql-manager-0.58/META.yml 185 mha4mysql-manager-0.58/lib/ 186 mha4mysql-manager-0.58/lib/MHA/ 187 mha4mysql-manager-0.58/lib/MHA/ManagerAdmin.pm 188 mha4mysql-manager-0.58/lib/MHA/Server.pm 189 mha4mysql-manager-0.58/lib/MHA/MasterRotate.pm 190 mha4mysql-manager-0.58/lib/MHA/Config.pm 191 mha4mysql-manager-0.58/lib/MHA/ManagerAdminWrapper.pm 192 mha4mysql-manager-0.58/lib/MHA/ServerManager.pm 193 mha4mysql-manager-0.58/lib/MHA/HealthCheck.pm 194 mha4mysql-manager-0.58/lib/MHA/ManagerConst.pm 195 mha4mysql-manager-0.58/lib/MHA/DBHelper.pm 196 mha4mysql-manager-0.58/lib/MHA/SSHCheck.pm 197 mha4mysql-manager-0.58/lib/MHA/FileStatus.pm 198 mha4mysql-manager-0.58/lib/MHA/ManagerUtil.pm 199 mha4mysql-manager-0.58/lib/MHA/MasterFailover.pm 200 mha4mysql-manager-0.58/lib/MHA/MasterMonitor.pm 201 mha4mysql-manager-0.58/Makefile.PL 202 mha4mysql-manager-0.58/rpm/ 203 mha4mysql-manager-0.58/rpm/masterha_manager.spec 204 [root@monitor ~]# 205 [root@monitor ~]# 206 [root@monitor ~]# cd mha4mysql-manager-0.58 207 [root@monitor mha4mysql-manager-0.58]# ls 208 AUTHORS bin COPYING debian inc lib Makefile.PL MANIFEST META.yml README rpm samples t tests 209 [root@monitor mha4mysql-manager-0.58]# perl Makefile.PL 210 *** Module::AutoInstall version 1.06 211 *** Checking for Perl dependencies... 212 [Core Features] 213 - DBI ...loaded. (1.627) 214 - DBD::mysql ...loaded. (4.023) 215 - Time::HiRes ...loaded. (1.9725) 216 - Config::Tiny ...loaded. (2.14) 217 - Log::Dispatch ...loaded. (2.41) 218 - Parallel::ForkManager ...loaded. (1.18) 219 - MHA::NodeConst ...loaded. (0.58) 220 *** Module::AutoInstall configuration finished. 221 Checking if your kit is complete... 222 Looks good 223 Writing Makefile for mha4mysql::manager 224 [root@monitor mha4mysql-manager-0.58]# make 225 cp lib/MHA/ManagerUtil.pm blib/lib/MHA/ManagerUtil.pm 226 cp lib/MHA/Config.pm blib/lib/MHA/Config.pm 227 cp lib/MHA/HealthCheck.pm blib/lib/MHA/HealthCheck.pm 228 cp lib/MHA/ServerManager.pm blib/lib/MHA/ServerManager.pm 229 cp lib/MHA/ManagerConst.pm blib/lib/MHA/ManagerConst.pm 230 cp lib/MHA/FileStatus.pm blib/lib/MHA/FileStatus.pm 231 cp lib/MHA/ManagerAdmin.pm blib/lib/MHA/ManagerAdmin.pm 232 cp lib/MHA/ManagerAdminWrapper.pm blib/lib/MHA/ManagerAdminWrapper.pm 233 cp lib/MHA/MasterFailover.pm blib/lib/MHA/MasterFailover.pm 234 cp lib/MHA/MasterRotate.pm blib/lib/MHA/MasterRotate.pm 235 cp lib/MHA/MasterMonitor.pm blib/lib/MHA/MasterMonitor.pm 236 cp lib/MHA/Server.pm blib/lib/MHA/Server.pm 237 cp lib/MHA/SSHCheck.pm blib/lib/MHA/SSHCheck.pm 238 cp lib/MHA/DBHelper.pm blib/lib/MHA/DBHelper.pm 239 cp bin/masterha_stop blib/script/masterha_stop 240 /usr/bin/perl "-Iinc" -MExtUtils::MY -e 'MY->fixin(shift)' -- blib/script/masterha_stop 241 cp bin/masterha_conf_host blib/script/masterha_conf_host 242 /usr/bin/perl "-Iinc" -MExtUtils::MY -e 'MY->fixin(shift)' -- blib/script/masterha_conf_host 243 cp bin/masterha_check_repl blib/script/masterha_check_repl 244 /usr/bin/perl "-Iinc" -MExtUtils::MY -e 'MY->fixin(shift)' -- blib/script/masterha_check_repl 245 cp bin/masterha_check_status blib/script/masterha_check_status 246 /usr/bin/perl "-Iinc" -MExtUtils::MY -e 'MY->fixin(shift)' -- blib/script/masterha_check_status 247 cp bin/masterha_master_monitor blib/script/masterha_master_monitor 248 /usr/bin/perl "-Iinc" -MExtUtils::MY -e 'MY->fixin(shift)' -- blib/script/masterha_master_monitor 249 cp bin/masterha_check_ssh blib/script/masterha_check_ssh 250 /usr/bin/perl "-Iinc" -MExtUtils::MY -e 'MY->fixin(shift)' -- blib/script/masterha_check_ssh 251 cp bin/masterha_master_switch blib/script/masterha_master_switch 252 /usr/bin/perl "-Iinc" -MExtUtils::MY -e 'MY->fixin(shift)' -- blib/script/masterha_master_switch 253 cp bin/masterha_secondary_check blib/script/masterha_secondary_check 254 /usr/bin/perl "-Iinc" -MExtUtils::MY -e 'MY->fixin(shift)' -- blib/script/masterha_secondary_check 255 cp bin/masterha_manager blib/script/masterha_manager 256 /usr/bin/perl "-Iinc" -MExtUtils::MY -e 'MY->fixin(shift)' -- blib/script/masterha_manager 257 Manifying blib/man1/masterha_stop.1 258 Manifying blib/man1/masterha_conf_host.1 259 Manifying blib/man1/masterha_check_repl.1 260 Manifying blib/man1/masterha_check_status.1 261 Manifying blib/man1/masterha_master_monitor.1 262 Manifying blib/man1/masterha_check_ssh.1 263 Manifying blib/man1/masterha_master_switch.1 264 Manifying blib/man1/masterha_secondary_check.1 265 Manifying blib/man1/masterha_manager.1 266 [root@monitor mha4mysql-manager-0.58]# make install 267 Installing /usr/local/share/perl5/MHA/ManagerUtil.pm 268 Installing /usr/local/share/perl5/MHA/Config.pm 269 Installing /usr/local/share/perl5/MHA/HealthCheck.pm 270 Installing /usr/local/share/perl5/MHA/ServerManager.pm 271 Installing /usr/local/share/perl5/MHA/ManagerConst.pm 272 Installing /usr/local/share/perl5/MHA/FileStatus.pm 273 Installing /usr/local/share/perl5/MHA/ManagerAdmin.pm 274 Installing /usr/local/share/perl5/MHA/ManagerAdminWrapper.pm 275 Installing /usr/local/share/perl5/MHA/MasterFailover.pm 276 Installing /usr/local/share/perl5/MHA/MasterRotate.pm 277 Installing /usr/local/share/perl5/MHA/MasterMonitor.pm 278 Installing /usr/local/share/perl5/MHA/Server.pm 279 Installing /usr/local/share/perl5/MHA/SSHCheck.pm 280 Installing /usr/local/share/perl5/MHA/DBHelper.pm 281 Installing /usr/local/share/man/man1/masterha_stop.1 282 Installing /usr/local/share/man/man1/masterha_conf_host.1 283 Installing /usr/local/share/man/man1/masterha_check_repl.1 284 Installing /usr/local/share/man/man1/masterha_check_status.1 285 Installing /usr/local/share/man/man1/masterha_master_monitor.1 286 Installing /usr/local/share/man/man1/masterha_check_ssh.1 287 Installing /usr/local/share/man/man1/masterha_master_switch.1 288 Installing /usr/local/share/man/man1/masterha_secondary_check.1 289 Installing /usr/local/share/man/man1/masterha_manager.1 290 Installing /usr/local/bin/masterha_stop 291 Installing /usr/local/bin/masterha_conf_host 292 Installing /usr/local/bin/masterha_check_repl 293 Installing /usr/local/bin/masterha_check_status 294 Installing /usr/local/bin/masterha_master_monitor 295 Installing /usr/local/bin/masterha_check_ssh 296 Installing /usr/local/bin/masterha_master_switch 297 Installing /usr/local/bin/masterha_secondary_check 298 Installing /usr/local/bin/masterha_manager 299 Appending installation info to /usr/lib64/perl5/perllocal.pod 300 [root@monitor mha4mysql-manager-0.58]# 301
(三)MHA配置(MHA Manager节点)
所有的MHA配置都是在MHA Manager节点完成的,接下来对MHA进行配置。
(3.1)SSH节点互信配置
MHA在failover切换时,需要拷贝binlog/relaylog,需要各个节点无需密码就可以访问,配置如下:
STEP1:在所有节点生成rsa秘钥
# 特别注意,该步骤需要在所有节点执行 [root@monitor ~]# /usr/bin/ssh-keygen -t rsa
STEP2:把所有节点的公钥存放到同一个文件authorized_keys中,可以在任意节点上操作
[root@monitor ~]# cd .ssh/ [root@monitor .ssh]# pwd /root/.ssh ssh 192.168.10.5 cat ~/.ssh/id_rsa.pub >> authorized_keys ssh 192.168.10.11 cat ~/.ssh/id_rsa.pub >> authorized_keys ssh 192.168.10.12 cat ~/.ssh/id_rsa.pub >> authorized_keys ssh 192.168.10.13 cat ~/.ssh/id_rsa.pub >> authorized_keys
STEP3:拷贝authorized_keys文件到其它节点
[root@monitor .ssh]# pwd /root/.ssh scp authorized_keys root@192.168.10.11:`pwd` scp authorized_keys root@192.168.10.12:`pwd` scp authorized_keys root@192.168.10.13:`pwd`
STEP4:验证ssh【可选,后续会使用masterha_check_ssh脚本检查】
ssh 192.168.10.5 hostname ssh 192.168.10.11 hostname ssh 192.168.10.12 hostname ssh 192.168.10.13 hostname
(3.2)MHA配置文件
手动创建配置文件/etc/mha/app1.cnf,信息如下:
[root@monitor ~]# vim /etc/mha/app1.cnf ########## 1.全局配置 ############ [server default] # 设置manager日志 manager_log=/mha/mha4mysql-manager-master/app1/log/manager.log # 设置manager工作路径 manager_workdir=/mha/mha4mysql-manager-master/app1 # 设置master binlog位置,以便主节点MySQL数据库宕了后,MHA可以找到binlog日志位置 master_binlog_dir=/mysql/binlog # 设置自动failover时的切换脚本,该脚本需要手动创建 master_ip_failover_script=/mha/mha4mysql-manager-master/bin/master_ip_failover # 设置手动切换时的切换脚本,该脚本需要手动创建 master_ip_online_change_script=/mha/mha4mysql-manager-master/bin/master_ip_online_change # 设置MHA监控、切换用户。运行所有必需的管理命令,例如STOP SLAVE,CHANGE MASTER和RESET SLAVE user=mhaadmin password="mhaadmin" # 设置复制用户、密码。每个从属服务器上的CHANGE MASTER TO master_user ..中使用的MySQL复制用户名。该用户应在目标主机上具有REPLICATION SLAVE特权。 # 默认情况下,将使用新主服务器上的SHOW SLAVE STATUS中的Master_User(当前作为从服务器运行)。 repl_user=replica repl_password=replica # 设置操作系统层面的ssh登录用户 ssh_user=root # 设置发生切换后发送报警的脚本 # report_script=/mha/mha4mysql-manager-master/bin/send_report # 集群内部检测主节点状态 secondary_check_script=/usr/local/bin/masterha_secondary_check -s node2 -s node3 --user=root --master_host=node1 --master_ip=192.168.10.11 --master_port=3306 # 设置故障发生后关闭故障主机的脚本(主要作用是关闭故障主机防止脑裂) shutdown_script="" # 设置监控master的间隔时间为3秒,若尝试3次没有回应则自动failover ping_interval=5 # 设置远端MySQL在切换时保存binlog的具体位置 remote_workdir=/tmp ########## 2.节点配置 ############ [server1] hostname=192.168.10.11 port=3306 [server2] # 设置为候选master,发生切换后提升为master,即使这个库不是集群中最新的slave candidate_master=1 # 默认情况下一个slave落后master 100Mb的relay logs时MHA将不会选择该slave作为master,通过设置check_repl_delay=0可以保证设置为candidate_master的server一定会提升为新的master check_repl_delay=0 hostname=192.168.10.12 port=3306 [server3] hostname=192.168.10.13 port=3306
相关参数配置:
1.在MHA Manager上创建涉及到的路径
[root@monitor ~]# mkdir -p /mha/mha4mysql-manager-master/app1/log [root@monitor ~]# mkdir -p /mha/mha4mysql-manager-master/bin/
2.在MySQL主节点上创建用于MHA管理的数据库账号mhaadmin
create user 'mhaadmin'@'%' identified WITH mysql_native_password by 'mhaadmin'; grant all privileges on *.* to 'mhaadmin'@'%'; flush privileges;
(3.3)故障转移IP切换配置
MHA还提供了VIP(虚拟IP)切换功能,当MySQL主节点运行正常时,VIP运行在主服务器上,一旦主节点发生故障切换,VIP也会随之切换到新的主节点上,这样的好处是:应用程序使用VIP连接到数据库,即使主库发生故障,也能够继续访问数据库。该文件的路径由MHA配置文件中的master_ip_failover_script参数决定。
STEP1:在Manager节点添加VIP切换脚本
[root@monitor ~]# vi /mha/mha4mysql-manager-master/bin/master_ip_failover #!/usr/bin/env perl # Copyright (C) 2011 DeNA Co.,Ltd. # You should have received a copy of the GNU General Public License # along with this program; if not, write to the Free Software # Foundation, Inc., # 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA ## Note: This is a sample script and is not complete. Modify the script based on your environment. use strict; use warnings FATAL => 'all'; use Getopt::Long; use MHA::DBHelper; my ( $command, $ssh_user, $orig_master_host, $orig_master_ip, $orig_master_port, $new_master_host, $new_master_ip, $new_master_port, $new_master_user, $new_master_password ); # 在每次配置时,修改下面4行即可 my $vip = '192.168.10.10/24'; my $key = '1'; my $ssh_start_vip = "/sbin/ifconfig ens33:$key $vip"; my $ssh_stop_vip = "/sbin/ifconfig ens33:$key down"; GetOptions( 'command=s' => \$command, 'ssh_user=s' => \$ssh_user, 'orig_master_host=s' => \$orig_master_host, 'orig_master_ip=s' => \$orig_master_ip, 'orig_master_port=i' => \$orig_master_port, 'new_master_host=s' => \$new_master_host, 'new_master_ip=s' => \$new_master_ip, 'new_master_port=i' => \$new_master_port, 'new_master_user=s' => \$new_master_user, 'new_master_password=s' => \$new_master_password, ); exit &main(); sub main { print "\n\nIN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip===\n\n"; if ( $command eq "stop" || $command eq "stopssh" ) { my $exit_code = 1; eval { print "Disabling the VIP on old master: $orig_master_host \n"; &stop_vip(); $exit_code = 0; }; if ($@) { warn "Got Error: $@\n"; exit $exit_code; } exit $exit_code; } elsif ( $command eq "start" ) { my $exit_code = 10; eval { print "Enabling the VIP - $vip on the new master - $new_master_host \n"; &start_vip(); $exit_code = 0; }; if ($@) { warn $@; exit $exit_code; } exit $exit_code; } elsif ( $command eq "status" ) { print "Checking the Status of the script.. OK \n"; exit 0; } else { &usage(); exit 1; } } sub start_vip() { `ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`; } sub stop_vip() { return 0 unless ($ssh_user); `ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`; } sub usage { print "Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n"; }
对该脚本授权授予执行的权限
[root@monitor bin]# ll total 4 -rw-r--r--. 1 root root 2725 Mar 29 16:55 master_ip_failover [root@monitor bin]# chmod +x master_ip_failover
Note:在每次配置时,修改下面4行即可
my $vip = '192.168.10.10/24';
my $key = '1';
my $ssh_start_vip = "/sbin/ifconfig ens34:$key $vip";
my $ssh_stop_vip = "/sbin/ifconfig ens34:$key down";
其中:
- $vip是我们定义的虚拟IP,需要与MySQL主机的IP在同一个网段
- $key随便定义一个数字
- $ssh_start_vip和$ssh_stop_vip中存在一个"ens34"参数,是我们VIP绑定的网卡,网上很多文章这里使用的是" eth* ",这是redhat的网卡命名方式,具体使用什么参数,可以ifconfig来决定。
STEP2:在MySQL主节点手动开启VIP
# 在MySQL主节点手动开启VIP /sbin/ifconfig ens34:1 192.168.10.10/24
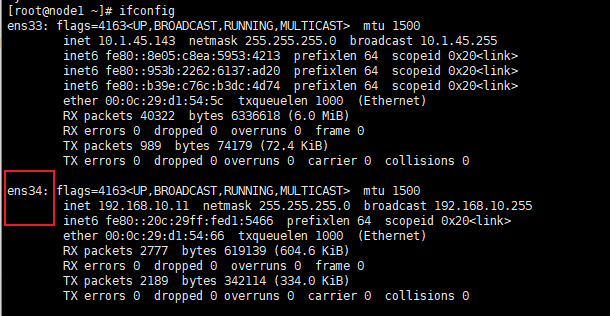
添加VIP前后网卡信息对比
[root@node1 ~]# ifconfig
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.1.45.143 netmask 255.255.255.0 broadcast 10.1.45.255
inet6 fe80::8e05:c8ea:5953:4213 prefixlen 64 scopeid 0x20<link>
inet6 fe80::953b:2262:6137:ad20 prefixlen 64 scopeid 0x20<link>
inet6 fe80::b39e:c76c:b3dc:4d74 prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:d1:54:5c txqueuelen 1000 (Ethernet)
RX packets 40322 bytes 6336618 (6.0 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 989 bytes 74179 (72.4 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
ens34: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.10.11 netmask 255.255.255.0 broadcast 192.168.10.255
inet6 fe80::20c:29ff:fed1:5466 prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:d1:54:66 txqueuelen 1000 (Ethernet)
RX packets 2777 bytes 619139 (604.6 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 2189 bytes 342114 (334.0 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1 (Local Loopback)
RX packets 141 bytes 26024 (25.4 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 141 bytes 26024 (25.4 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[root@node1 ~]# /sbin/ifconfig ens34:1 192.168.10.10/24 # 添加虚拟IP
[root@node1 ~]# ifconfig
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.1.45.143 netmask 255.255.255.0 broadcast 10.1.45.255
inet6 fe80::8e05:c8ea:5953:4213 prefixlen 64 scopeid 0x20<link>
inet6 fe80::953b:2262:6137:ad20 prefixlen 64 scopeid 0x20<link>
inet6 fe80::b39e:c76c:b3dc:4d74 prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:d1:54:5c txqueuelen 1000 (Ethernet)
RX packets 44562 bytes 6706687 (6.3 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 990 bytes 74239 (72.4 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
ens34: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.10.11 netmask 255.255.255.0 broadcast 192.168.10.255
inet6 fe80::20c:29ff:fed1:5466 prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:d1:54:66 txqueuelen 1000 (Ethernet)
RX packets 2914 bytes 629516 (614.7 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 2300 bytes 354878 (346.5 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
ens34:1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.10.10 netmask 255.255.255.0 broadcast 192.168.10.255
ether 00:0c:29:d1:54:66 txqueuelen 1000 (Ethernet)
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1 (Local Loopback)
RX packets 141 bytes 26024 (25.4 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 141 bytes 26024 (25.4 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
(3.4)在线VIP切换配置
除了故障转移需要进行VIP切换,在线主从切换也需要切换VIP,在线切换VIP脚本路径由MHA配置文件中的master_ip_online_change_script参数决定。
在Manager节点添加在线VIP切换脚本:
[root@monitor bin]# vim /mha/mha4mysql-manager-master/bin/master_ip_online_change #!/usr/bin/env perl # Copyright (C) 2011 DeNA Co.,Ltd. # # This program is free software; you can redistribute it and/or modify # it under the terms of the GNU General Public License as published by # the Free Software Foundation; either version 2 of the License, or # (at your option) any later version. # # This program is distributed in the hope that it will be useful, # but WITHOUT ANY WARRANTY; without even the implied warranty of # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the # GNU General Public License for more details. # # You should have received a copy of the GNU General Public License # along with this program; if not, write to the Free Software # Foundation, Inc., # 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA ## Note: This is a sample script and is not complete. Modify the script based on your environment. use strict; use warnings FATAL => 'all'; use Getopt::Long; use MHA::DBHelper; use MHA::NodeUtil; use Time::HiRes qw( sleep gettimeofday tv_interval ); use Data::Dumper; my $_tstart; my $_running_interval = 0.1; my ( $command, $orig_master_is_new_slave, $orig_master_host, $orig_master_ip, $orig_master_port, $orig_master_user, $orig_master_password, $orig_master_ssh_user, $new_master_host, $new_master_ip, $new_master_port, $new_master_user, $new_master_password, $new_master_ssh_user, ); # 在每次配置时,修改下面5行即可 my $vip = '192.168.10.10/24'; my $key = '1'; my $ssh_start_vip = "/sbin/ifconfig ens34:$key $vip"; my $ssh_stop_vip = "/sbin/ifconfig ens34:$key down"; my $ssh_user = "root"; GetOptions( 'command=s' => \$command, 'orig_master_is_new_slave' => \$orig_master_is_new_slave, 'orig_master_host=s' => \$orig_master_host, 'orig_master_ip=s' => \$orig_master_ip, 'orig_master_port=i' => \$orig_master_port, 'orig_master_user=s' => \$orig_master_user, 'orig_master_password=s' => \$orig_master_password, 'orig_master_ssh_user=s' => \$orig_master_ssh_user, 'new_master_host=s' => \$new_master_host, 'new_master_ip=s' => \$new_master_ip, 'new_master_port=i' => \$new_master_port, 'new_master_user=s' => \$new_master_user, 'new_master_password=s' => \$new_master_password, 'new_master_ssh_user=s' => \$new_master_ssh_user, ); exit &main(); sub current_time_us { my ( $sec, $microsec ) = gettimeofday(); my $curdate = localtime($sec); return $curdate . " " . sprintf( "%06d", $microsec ); } sub sleep_until { my $elapsed = tv_interval($_tstart); if ( $_running_interval > $elapsed ) { sleep( $_running_interval - $elapsed ); } } sub get_threads_util { my $dbh = shift; my $my_connection_id = shift; my $running_time_threshold = shift; my $type = shift; $running_time_threshold = 0 unless ($running_time_threshold); $type = 0 unless ($type); my @threads; my $sth = $dbh->prepare("SHOW PROCESSLIST"); $sth->execute(); while ( my $ref = $sth->fetchrow_hashref() ) { my $id = $ref->{Id}; my $user = $ref->{User}; my $host = $ref->{Host}; my $command = $ref->{Command}; my $state = $ref->{State}; my $query_time = $ref->{Time}; my $info = $ref->{Info}; $info =~ s/^\s*(.*?)\s*$/$1/ if defined($info); next if ( $my_connection_id == $id ); next if ( defined($query_time) && $query_time < $running_time_threshold ); next if ( defined($command) && $command eq "Binlog Dump" ); next if ( defined($user) && $user eq "system user" ); next if ( defined($command) && $command eq "Sleep" && defined($query_time) && $query_time >= 1 ); if ( $type >= 1 ) { next if ( defined($command) && $command eq "Sleep" ); next if ( defined($command) && $command eq "Connect" ); } if ( $type >= 2 ) { next if ( defined($info) && $info =~ m/^select/i ); next if ( defined($info) && $info =~ m/^show/i ); } push @threads, $ref; } return @threads; } sub main { if ( $command eq "stop" ) { ## Gracefully killing connections on the current master # 1. Set read_only= 1 on the new master # 2. DROP USER so that no app user can establish new connections # 3. Set read_only= 1 on the current master # 4. Kill current queries # * Any database access failure will result in script die. my $exit_code = 1; eval { ## Setting read_only=1 on the new master (to avoid accident) my $new_master_handler = new MHA::DBHelper(); # args: hostname, port, user, password, raise_error(die_on_error)_or_not $new_master_handler->connect( $new_master_ip, $new_master_port, $new_master_user, $new_master_password, 1 ); print current_time_us() . " Set read_only on the new master.. "; $new_master_handler->enable_read_only(); if ( $new_master_handler->is_read_only() ) { print "ok.\n"; } else { die "Failed!\n"; } $new_master_handler->disconnect(); # Connecting to the orig master, die if any database error happens my $orig_master_handler = new MHA::DBHelper(); $orig_master_handler->connect( $orig_master_ip, $orig_master_port, $orig_master_user, $orig_master_password, 1 ); ## Drop application user so that nobody can connect. Disabling per-session binlog beforehand $orig_master_handler->disable_log_bin_local(); print current_time_us() . " Drpping app user on the orig master..\n"; # FIXME_xxx_drop_app_user($orig_master_handler); ## Waiting for N * 100 milliseconds so that current connections can exit my $time_until_read_only = 15; $_tstart = [gettimeofday]; my @threads = get_threads_util( $orig_master_handler->{dbh}, $orig_master_handler->{connection_id} ); while ( $time_until_read_only > 0 && $#threads >= 0 ) { if ( $time_until_read_only % 5 == 0 ) { printf "%s Waiting all running %d threads are disconnected.. (max %d milliseconds)\n", current_time_us(), $#threads + 1, $time_until_read_only * 100; if ( $#threads < 5 ) { print Data::Dumper->new( [$_] )->Indent(0)->Terse(1)->Dump . "\n" foreach (@threads); } } sleep_until(); $_tstart = [gettimeofday]; $time_until_read_only--; @threads = get_threads_util( $orig_master_handler->{dbh}, $orig_master_handler->{connection_id} ); } ## Setting read_only=1 on the current master so that nobody(except SUPER) can write print current_time_us() . " Set read_only=1 on the orig master.. "; $orig_master_handler->enable_read_only(); if ( $orig_master_handler->is_read_only() ) { print "ok.\n"; } else { die "Failed!\n"; } ## Waiting for M * 100 milliseconds so that current update queries can complete my $time_until_kill_threads = 5; @threads = get_threads_util( $orig_master_handler->{dbh}, $orig_master_handler->{connection_id} ); while ( $time_until_kill_threads > 0 && $#threads >= 0 ) { if ( $time_until_kill_threads % 5 == 0 ) { printf "%s Waiting all running %d queries are disconnected.. (max %d milliseconds)\n", current_time_us(), $#threads + 1, $time_until_kill_threads * 100; if ( $#threads < 5 ) { print Data::Dumper->new( [$_] )->Indent(0)->Terse(1)->Dump . "\n" foreach (@threads); } } sleep_until(); $_tstart = [gettimeofday]; $time_until_kill_threads--; @threads = get_threads_util( $orig_master_handler->{dbh}, $orig_master_handler->{connection_id} ); } ## Terminating all threads print current_time_us() . " Killing all application threads..\n"; $orig_master_handler->kill_threads(@threads) if ( $#threads >= 0 ); print current_time_us() . " done.\n"; $orig_master_handler->enable_log_bin_local(); $orig_master_handler->disconnect(); ## After finishing the script, MHA executes FLUSH TABLES WITH READ LOCK print "Disabling the VIP on old master: $orig_master_host \n"; &stop_vip(); $exit_code = 0; }; if ($@) { warn "Got Error: $@\n"; exit $exit_code; } exit $exit_code; } elsif ( $command eq "start" ) { ## Activating master ip on the new master # 1. Create app user with write privileges # 2. Moving backup script if needed # 3. Register new master's ip to the catalog database # We don't return error even though activating updatable accounts/ip failed so that we don't interrupt slaves' recovery. # If exit code is 0 or 10, MHA does not abort my $exit_code = 10; eval { my $new_master_handler = new MHA::DBHelper(); # args: hostname, port, user, password, raise_error_or_not $new_master_handler->connect( $new_master_ip, $new_master_port, $new_master_user, $new_master_password, 1 ); #####################עzhu shi jin yong er jin zhi ri zhi ########################### ## Set disable log bin #$new_master_handler->disable_log_bin_local(); ######################################### print current_time_us() . " Set read_only=0 on the new master.\n"; ## Set read_only=0 on the new master $new_master_handler->disable_read_only(); #################### zhu shi chuang jian yong hu , bing kai qi bin log ## Creating an app user on the new master # print current_time_us() . " Creating app user on the new master..\n"; # FIXME_xxx_create_app_user($new_master_handler); # $new_master_handler->enable_log_bin_local(); # $new_master_handler->disconnect(); ####################################################################### print "Enabling the VIP - $vip on the new master - $new_master_host \n"; &start_vip(); ## Update master ip on the catalog database, etc $exit_code = 0; }; if ($@) { warn "Got Error: $@\n"; exit $exit_code; } exit $exit_code; } elsif ( $command eq "status" ) { # do nothing &start_vip(); exit 0; } else { &usage(); exit 1; } } # simple system call that enable the VIP on the new master sub start_vip() { `ssh $ssh_user\@$new_master_ip \" $ssh_start_vip \"`; } # A simple system call that disable the VIP on the old_master sub stop_vip() { `ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`; } sub usage { print "Usage: master_ip_online_change --command=start|stop|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n"; die; }
(3.5)检查MHA配置是否正确
MHA配置检查主要检查:SSH节点互信和主从复制状态。
STEP1:SSH节点互信检查
[root@monitor ~]# masterha_check_ssh -conf=/etc/mha/app1.cnf Mon Mar 29 17:07:16 2021 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. Mon Mar 29 17:07:16 2021 - [info] Reading application default configuration from /etc/mha/app1.cnf.. Mon Mar 29 17:07:16 2021 - [info] Reading server configuration from /etc/mha/app1.cnf.. Mon Mar 29 17:07:16 2021 - [info] Starting SSH connection tests.. Mon Mar 29 17:07:17 2021 - [debug] Mon Mar 29 17:07:16 2021 - [debug] Connecting via SSH from root@192.168.10.11(192.168.10.11:22) to root@192.168.10.12(192.168.10.12:22).. Mon Mar 29 17:07:16 2021 - [debug] ok. Mon Mar 29 17:07:16 2021 - [debug] Connecting via SSH from root@192.168.10.11(192.168.10.11:22) to root@192.168.10.13(192.168.10.13:22).. Mon Mar 29 17:07:17 2021 - [debug] ok. Mon Mar 29 17:07:18 2021 - [debug] Mon Mar 29 17:07:16 2021 - [debug] Connecting via SSH from root@192.168.10.12(192.168.10.12:22) to root@192.168.10.11(192.168.10.11:22).. Warning: Permanently added '192.168.10.11' (ECDSA) to the list of known hosts. Mon Mar 29 17:07:17 2021 - [debug] ok. Mon Mar 29 17:07:17 2021 - [debug] Connecting via SSH from root@192.168.10.12(192.168.10.12:22) to root@192.168.10.13(192.168.10.13:22).. Warning: Permanently added '192.168.10.13' (ECDSA) to the list of known hosts. Mon Mar 29 17:07:17 2021 - [debug] ok. Mon Mar 29 17:07:18 2021 - [debug] Mon Mar 29 17:07:17 2021 - [debug] Connecting via SSH from root@192.168.10.13(192.168.10.13:22) to root@192.168.10.11(192.168.10.11:22).. Warning: Permanently added '192.168.10.11' (ECDSA) to the list of known hosts. Mon Mar 29 17:07:17 2021 - [debug] ok. Mon Mar 29 17:07:17 2021 - [debug] Connecting via SSH from root@192.168.10.13(192.168.10.13:22) to root@192.168.10.12(192.168.10.12:22).. Warning: Permanently added '192.168.10.12' (ECDSA) to the list of known hosts. Mon Mar 29 17:07:18 2021 - [debug] ok. Mon Mar 29 17:07:18 2021 - [info] All SSH connection tests passed successfully.
如果最后返回“successfully”字样,则说明SSH节点互信没有问题。
STEP2:主从复制状态检查
[root@monitor ~]# masterha_check_repl -conf=/etc/mha/app1.cnf Mon Mar 29 17:10:58 2021 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. Mon Mar 29 17:10:58 2021 - [info] Reading application default configuration from /etc/mha/app1.cnf.. Mon Mar 29 17:10:58 2021 - [info] Reading server configuration from /etc/mha/app1.cnf.. Mon Mar 29 17:10:58 2021 - [info] MHA::MasterMonitor version 0.58. Mon Mar 29 17:10:59 2021 - [info] GTID failover mode = 1 Mon Mar 29 17:10:59 2021 - [info] Dead Servers: Mon Mar 29 17:10:59 2021 - [info] Alive Servers: Mon Mar 29 17:10:59 2021 - [info] 192.168.10.11(192.168.10.11:3306) Mon Mar 29 17:10:59 2021 - [info] 192.168.10.12(192.168.10.12:3306) Mon Mar 29 17:10:59 2021 - [info] 192.168.10.13(192.168.10.13:3306) Mon Mar 29 17:10:59 2021 - [info] Alive Slaves: Mon Mar 29 17:10:59 2021 - [info] 192.168.10.12(192.168.10.12:3306) Version=5.7.27-log (oldest major version between slaves) log-bin:enabled Mon Mar 29 17:10:59 2021 - [info] GTID ON Mon Mar 29 17:10:59 2021 - [info] Replicating from 192.168.10.11(192.168.10.11:3306) Mon Mar 29 17:10:59 2021 - [info] Primary candidate for the new Master (candidate_master is set) Mon Mar 29 17:10:59 2021 - [info] 192.168.10.13(192.168.10.13:3306) Version=5.7.27-log (oldest major version between slaves) log-bin:enabled Mon Mar 29 17:10:59 2021 - [info] GTID ON Mon Mar 29 17:10:59 2021 - [info] Replicating from 192.168.10.11(192.168.10.11:3306) Mon Mar 29 17:10:59 2021 - [info] Current Alive Master: 192.168.10.11(192.168.10.11:3306) Mon Mar 29 17:10:59 2021 - [info] Checking slave configurations.. Mon Mar 29 17:10:59 2021 - [info] Checking replication filtering settings.. Mon Mar 29 17:10:59 2021 - [info] binlog_do_db= , binlog_ignore_db= Mon Mar 29 17:10:59 2021 - [info] Replication filtering check ok. Mon Mar 29 17:10:59 2021 - [info] GTID (with auto-pos) is supported. Skipping all SSH and Node package checking. Mon Mar 29 17:10:59 2021 - [info] Checking SSH publickey authentication settings on the current master.. Mon Mar 29 17:10:59 2021 - [info] HealthCheck: SSH to 192.168.10.11 is reachable. Mon Mar 29 17:10:59 2021 - [info] 192.168.10.11(192.168.10.11:3306) (current master) +--192.168.10.12(192.168.10.12:3306) +--192.168.10.13(192.168.10.13:3306) Mon Mar 29 17:10:59 2021 - [info] Checking replication health on 192.168.10.12.. Mon Mar 29 17:10:59 2021 - [info] ok. Mon Mar 29 17:10:59 2021 - [info] Checking replication health on 192.168.10.13.. Mon Mar 29 17:10:59 2021 - [info] ok. Mon Mar 29 17:10:59 2021 - [info] Checking master_ip_failover_script status: Mon Mar 29 17:10:59 2021 - [info] /mha/mha4mysql-manager-master/bin/master_ip_failover --command=status --ssh_user=root --orig_master_host=192.168.10.11 --orig_master_ip=192.168.10.11 --orig_master_port=3306 IN SCRIPT TEST====/sbin/ifconfig ens34:1 down==/sbin/ifconfig ens34:1 192.168.10.10/24=== Checking the Status of the script.. OK Mon Mar 29 17:10:59 2021 - [info] OK. Mon Mar 29 17:10:59 2021 - [warning] shutdown_script is not defined. Mon Mar 29 17:10:59 2021 - [info] Got exit code 0 (Not master dead). MySQL Replication Health is OK.
如果最后出现“OK”,则说明主从复制正常。
(四)MHA Manager相关脚本说明
在安装完MHA Manager后,会生成一系列的脚本文件,所有文件机器作用如下:
masterha_check_repl:检查MySQL复制运行情况
masterha_check_ssh:检查MHA与MySQL节点之间的ssh互信
masterha_check_status:检查masterha_manager的运行状态
masterha_manager:启动MHA Manager
masterha_stop:停止MHA Manager
masterha_master_switch :用于手动failover和手动主节点切换
masterha_secondary_check :通过MySQL从节点检查主节点状态
masterha_master_monitor:用于监控MySQL主节点,不常用
masterha_conf_host:一个帮助程序脚本,用于从配置文件中添加/删除主机条目,不常用
这里我们对常用的几个脚本进行学习。
(4.1)masterha_manager
用途:用于启动mha manager,完成自动故障转移。启动方式如下:
# 在前台启动mha manager masterha_manager --conf=/etc/mha/app1.cnf # 在后台启动mha manager nohup masterha_manager --conf=/etc/mha/app1.cnf &
其它重要参数:
--ignore_fail_on_start :默认情况下如果任何从属服务器发生故障,MHA Manager都不会启动故障转移,但是某些情况下,你可能希望进行故障转移。则可以在mha配置文件的节点配置部分添加ignore_fail=1,在masterha_manager添加该参数,及时这些服务器发生故障,MHA也会进行故障转移
--ignore_last_failover :如果先前的故障转移失败,则8小时内不能再次启动故障转移,因为该问题可能再次发生。启动故障转移的步骤通常是手动删除$manager_workdir/$(app_name).failover.error文件;通过设置--ignore_last_failover,无论最近的故障转移状态如何,MHA都会进行故障转移
--last_failover_minute = 分钟 :如果故障转移是最近完成的(默认8小时),则mha manager不会进行故障转移,因为很可能通过故障转移无法解决问题。此参数可以用来修改时间标准
--remove_dead_master_conf :添加此参数后,如果故障转移成功完成,则mha manager会从配置文件删除失效主服务器的部分。如果不加该参数,在切换时不会修改配置文件,此时如果启动masterha_manager,则masterha_manager将停止,并显示错误"there is a dead slave"
(4.2)masterha_master_switch
用途:用于①手动故障转移;在线手动主从切换
手动故障转移主要用于主节点已经down情况下的切换,在线手动主从切换主要是将主节点切换到另一个机器上,以便于进行一些维护工作。
(4.2.1)手动故障转移
手动故障转移示例:
masterha_master_switch --master_state=dead --conf=/etc/app1.cnf --dead_master_host=192.168.10.11 --ignore_last_failover
其它重要参数:
--master_state=dead :必填参数。 可设置为"dead"和"alive",当使用手动故障转移的时候,设置为"dead",当使用在线手动主从切换的时候,设置为"alive"
--dead_master_host = 主机名 :必填参数。死主机的主机名,也可以选择设置--dead_master_ip和--dead_master_port。
--new_master_host = 主机名 :可选参数。显式设置某个节点为MySQL主节点,如果未设置该参数,则MHA会根据选主规则来确定新的主服务器
--new_master_host = 端口号 :可选参数。新主服务器上MySQL实例的侦听端口,默认3306
--interactive = (0 | 1) :切换过程是否启用非交互式。默认1,交互式
--ignore_last_failover :与masterha_manager相同
--remove_dead_master_conf :与masterha_manager相同
(4.2.2)在线主从切换
在线主从切换示例:
masterha_master_switch --master_state=alive --conf=/etc/app1.cnf --new_master_host=192.168.10.11 -- orig_master_is_new_slave
其它重要参数:
--new_master_host = 主机名 : 新主节点的主机名
--orig_master_is_new_slave :主机切换完成后,先前的主机将作为新主机的从机运行。默认情况下,它是禁用的
--running_updates_limit = (秒) :如果MySQL主节点写请求超过这个参数,或者从节点落后于主节点这个值,则切换中止
--remove_orig_master_conf :如果在线切换成果,则MHA将自动移除配置文件中的原始主节点信息
--skip_lock_all_tables :当执行在线切换,在原主节点上运行"flush tables with read lock"确保主节点停止更新
(4.3)masterha_secondary_check
用途:用于主节点状态检查,该脚本需要在mha manager的配置文件的参数secondary_check_script中设置。在MHA的配置文件中,secondary_check_script脚本是可选的,个人建议配置上,为什么呢?我们可以通过下面的图来做说明:
- 当不配置secondary_check_script脚本时,mha manager直接连接到mysql master查看节点状态。此时如果mha manager与MySQL主节点存在网络故障,即使MySQL主节点正常运行,也可能产生误判,导致发生故障转移。
- 当配置了secondary_check_script脚本时,首先mha manager直接连接到mysql master查看节点状态,如果判断主节点异常,则会通过从节点连接到主节点再次判断主节点是否正常,如果3条链路都无法连接到主节点,说明主节点down,不存在误判。

(五)MHA使用测试
如果要进行自动故障切换,则需要启动mha_manager;如果要进行手动故障切换或者手动主从切换,则需要关闭mha manager。
# 启动mha监控MySQL状态 [root@monitor ~]# nohup masterha_manager --conf=/etc/mha/app1.cnf --ignore_last_failover & [1] 30989 [root@monitor ~]# nohup: ignoring input and appending output to ‘nohup.out’ # 查看mha manager的运行状态 [root@monitor ~]# masterha_check_status --conf=/etc/mha/app1.cnf app1 (pid:30989) is running(0:PING_OK), master:192.168.10.11 # 如果要关闭mha manager,使用如下命令 [root@monitor ~]# masterha_stop --conf=/etc/mha/app1.cnf Stopped app1 successfully. [1]+ Exit 1 nohup masterha_manager -conf=/etc/mha/app1.cnf
(5.1)MHA故障切换测试(主节点服务器运行正常,数据库实例down)
STEP1:开启MHA Manager
[root@monitor ~]# nohup masterha_manager --conf=/etc/mha/app1.cnf --ignore_last_failover & [1] 2794 [root@monitor ~]# nohup: ignoring input and appending output to ‘nohup.out’
STEP2:在主节点node1关闭MySQL数据库
[root@node1 ~]# mysqladmin -uroot -p123456 shutdown mysqladmin: [Warning] Using a password on the command line interface can be insecure. [root@node1 ~]# [root@node1 ~]# service mysqld status ERROR! MySQL is not running, but lock file (/var/lock/subsys/mysql) exists
STEP3:查看数据库是否发生了主服务器故障转移
查看节点2,发现该节点的从库信息已经消除,目前已经为主库
[root@node2 ~]# mysql -uroot -p123456 mysql> show slave status \G Empty set (0.00 sec) mysql> show master status \G *************************** 1. row *************************** File: node2-bin.000005 Position: 194 Binlog_Do_DB: Binlog_Ignore_DB: Executed_Gtid_Set: 2db1f74f-8790-11eb-b668-000c29d1545c:1-94186, 30753d6b-8790-11eb-864f-000c2999ad6c:1-2 1 row in set (0.00 sec)
查看节点3,发现其主节点信息已自动变更为节点2
[root@node3 ~]# mysql -uroot -p123456 mysql> show slave status \G *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 192.168.10.12 Master_User: replica Master_Port: 3306 Connect_Retry: 60 Master_Log_File: node2-bin.000005 Read_Master_Log_Pos: 194 Relay_Log_File: node3-relay-bin.000007 Relay_Log_Pos: 407 Relay_Master_Log_File: node2-bin.000005 Slave_IO_Running: Yes Slave_SQL_Running: Yes
STEP4:查看虚拟IP是否已经发生了漂移
节点1的VIP已经被关闭
[root@node1 ~]# ifconfig ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 10.1.45.143 netmask 255.255.255.0 broadcast 10.1.45.255 inet6 fe80::953b:2262:6137:ad20 prefixlen 64 scopeid 0x20<link> ether 00:0c:29:d1:54:5c txqueuelen 1000 (Ethernet) RX packets 14274 bytes 1210361 (1.1 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 20 bytes 1965 (1.9 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 ens34: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.10.11 netmask 255.255.255.0 broadcast 192.168.10.255 inet6 fe80::20c:29ff:fed1:5466 prefixlen 64 scopeid 0x20<link> ether 00:0c:29:d1:54:66 txqueuelen 1000 (Ethernet) RX packets 3095 bytes 356811 (348.4 KiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 2254 bytes 378194 (369.3 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536 inet 127.0.0.1 netmask 255.0.0.0 inet6 ::1 prefixlen 128 scopeid 0x10<host> loop txqueuelen 1 (Local Loopback) RX packets 48 bytes 4194 (4.0 KiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 48 bytes 4194 (4.0 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
节点2的VIP已经自动生成
[root@node2 ~]# ifconfig ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 10.1.45.51 netmask 255.255.255.0 broadcast 10.1.45.255 inet6 fe80::953b:2262:6137:ad20 prefixlen 64 scopeid 0x20<link> inet6 fe80::b39e:c76c:b3dc:4d74 prefixlen 64 scopeid 0x20<link> ether 00:0c:29:99:ad:6c txqueuelen 1000 (Ethernet) RX packets 16102 bytes 1371651 (1.3 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 23 bytes 2286 (2.2 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 ens34: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.10.12 netmask 255.255.255.0 broadcast 192.168.10.255 inet6 fe80::20c:29ff:fe99:ad76 prefixlen 64 scopeid 0x20<link> ether 00:0c:29:99:ad:76 txqueuelen 1000 (Ethernet) RX packets 1474 bytes 153431 (149.8 KiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 1103 bytes 351924 (343.6 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 ens34:1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.10.10 netmask 255.255.255.0 broadcast 192.168.10.255 ether 00:0c:29:99:ad:76 txqueuelen 1000 (Ethernet) lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536 inet 127.0.0.1 netmask 255.0.0.0 inet6 ::1 prefixlen 128 scopeid 0x10<host> loop txqueuelen 1 (Local Loopback) RX packets 0 bytes 0 (0.0 B) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 0 bytes 0 (0.0 B) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
整个切换的日志信息如下:
1 ############################# MHA manager启动日志--开始 #################################### 2 Tue Mar 30 09:54:21 2021 - [info] MHA::MasterMonitor version 0.58. 3 Tue Mar 30 09:54:22 2021 - [info] GTID failover mode = 1 # 是否启用gtid 4 Tue Mar 30 09:54:22 2021 - [info] Dead Servers: 5 Tue Mar 30 09:54:22 2021 - [info] Alive Servers: # 确认所有正常节点 6 Tue Mar 30 09:54:22 2021 - [info] 192.168.10.11(192.168.10.11:3306) 7 Tue Mar 30 09:54:22 2021 - [info] 192.168.10.12(192.168.10.12:3306) 8 Tue Mar 30 09:54:22 2021 - [info] 192.168.10.13(192.168.10.13:3306) 9 Tue Mar 30 09:54:22 2021 - [info] Alive Slaves: # Slave节点信息确认:是否启用binlog,是否启用gtifd,主节点信息,candidate_master参数确认 10 Tue Mar 30 09:54:22 2021 - [info] 192.168.10.12(192.168.10.12:3306) Version=5.7.27-log (oldest major version between slaves) log-bin:enabled 11 Tue Mar 30 09:54:22 2021 - [info] GTID ON 12 Tue Mar 30 09:54:22 2021 - [info] Replicating from 192.168.10.11(192.168.10.11:3306) 13 Tue Mar 30 09:54:22 2021 - [info] Primary candidate for the new Master (candidate_master is set) 14 Tue Mar 30 09:54:22 2021 - [info] 192.168.10.13(192.168.10.13:3306) Version=5.7.27-log (oldest major version between slaves) log-bin:enabled 15 Tue Mar 30 09:54:22 2021 - [info] GTID ON 16 Tue Mar 30 09:54:22 2021 - [info] Replicating from 192.168.10.11(192.168.10.11:3306) 17 Tue Mar 30 09:54:22 2021 - [info] Current Alive Master: 192.168.10.11(192.168.10.11:3306) 18 Tue Mar 30 09:54:22 2021 - [info] Checking slave configurations.. 19 Tue Mar 30 09:54:22 2021 - [info] Checking replication filtering settings.. 20 Tue Mar 30 09:54:22 2021 - [info] binlog_do_db= , binlog_ignore_db= 21 Tue Mar 30 09:54:22 2021 - [info] Replication filtering check ok. 22 Tue Mar 30 09:54:22 2021 - [info] GTID (with auto-pos) is supported. Skipping all SSH and Node package checking. 23 Tue Mar 30 09:54:22 2021 - [info] Checking SSH publickey authentication settings on the current master.. 24 Tue Mar 30 09:54:23 2021 - [info] HealthCheck: SSH to 192.168.10.11 is reachable. 25 Tue Mar 30 09:54:23 2021 - [info] # MySQL主从关系拓扑图 26 192.168.10.11(192.168.10.11:3306) (current master) 27 +--192.168.10.12(192.168.10.12:3306) 28 +--192.168.10.13(192.168.10.13:3306) 29 30 Tue Mar 30 09:54:23 2021 - [info] Checking master_ip_failover_script status: # 检查故障转移IP切换脚本 31 Tue Mar 30 09:54:23 2021 - [info] /mha/mha4mysql-manager-master/bin/master_ip_failover --command=status --ssh_user=root --orig_master_host=192.168.10.11 --orig_master_ip=192.168.10.11 --orig_master_port=3306 32 33 34 IN SCRIPT TEST====/sbin/ifconfig ens34:1 down==/sbin/ifconfig ens34:1 192.168.10.10/24=== 35 36 Checking the Status of the script.. OK 37 Tue Mar 30 09:54:23 2021 - [info] OK. 38 Tue Mar 30 09:54:23 2021 - [warning] shutdown_script is not defined. 39 Tue Mar 30 09:54:23 2021 - [info] Set master ping interval 5 seconds. # 设置mha manager检查MySQL主节点的频率 40 Tue Mar 30 09:54:23 2021 - [info] Set secondary check script: /usr/local/bin/masterha_secondary_check -s node2 -s node3 --user=root --master_host=node1 --master_ip=192.168.10.11 --master_port=3306 # 通过从节点检查主节点的脚本 41 Tue Mar 30 09:54:23 2021 - [info] Starting ping health check on 192.168.10.11(192.168.10.11:3306).. 42 Tue Mar 30 09:54:23 2021 - [info] Ping(SELECT) succeeded, waiting until MySQL doesn't respond.. # mha manager在主节点执行ping成功,持续监控主节点 43 ############################# MHA manager启动日志--结束 #################################### 44 45 46 ############################# MySQL关闭,MHA manager开始切换主节点--开始 #################################### 47 48 ########################################################################################### 49 # 1.检测到mha manager无法连接到mysql主节点,然后通过MySQL从节点再次访问主节点数据库,发现无法 50 # 访问主节点数据库,但是ssh连接是通的 51 ########################################################################################### 52 Tue Mar 30 09:56:18 2021 - [warning] Got error on MySQL select ping: 2006 (MySQL server has gone away) 53 Tue Mar 30 09:56:18 2021 - [info] Executing secondary network check script: /usr/local/bin/masterha_secondary_check -s node2 -s node3 --user=root --master_host=node1 --master_ip=192.168.10.11 --master_port=3306 --user=root --master_host=192.168.10.11 --master_ip=192.168.10.11 --master_port=3306 --master_user=mhaadmin --master_password=mhaadmin --ping_type=SELECT 54 Tue Mar 30 09:56:18 2021 - [info] Executing SSH check script: exit 0 55 Warning: Permanently added 'node2' (ECDSA) to the list of known hosts. 56 Tue Mar 30 09:56:18 2021 - [info] HealthCheck: SSH to 192.168.10.11 is reachable. 57 Monitoring server node2 is reachable, Master is not reachable from node2. OK. 58 Warning: Permanently added 'node3' (ECDSA) to the list of known hosts. 59 Monitoring server node3 is reachable, Master is not reachable from node3. OK. 60 Tue Mar 30 09:56:19 2021 - [info] Master is not reachable from all other monitoring servers. Failover should start. 61 Tue Mar 30 09:56:23 2021 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '192.168.10.11' (111)) 62 Tue Mar 30 09:56:23 2021 - [warning] Connection failed 2 time(s).. 63 Tue Mar 30 09:56:28 2021 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '192.168.10.11' (111)) 64 Tue Mar 30 09:56:28 2021 - [warning] Connection failed 3 time(s).. 65 Tue Mar 30 09:56:33 2021 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '192.168.10.11' (111)) 66 Tue Mar 30 09:56:33 2021 - [warning] Connection failed 4 time(s).. 67 Tue Mar 30 09:56:33 2021 - [warning] Master is not reachable from health checker! 68 Tue Mar 30 09:56:33 2021 - [warning] Master 192.168.10.11(192.168.10.11:3306) is not reachable! 69 Tue Mar 30 09:56:33 2021 - [warning] SSH is reachable. 70 71 ########################################################################################### 72 # 2.检查当前MySQL节点的状态,确认:主节点down,从节点运行正常, 73 # 停止mha监控脚本,开始MySQL主节点切换 74 ########################################################################################### 75 Tue Mar 30 09:56:33 2021 - [info] Connecting to a master server failed. Reading configuration file /etc/masterha_default.cnf and /etc/mha/app1.cnf again, and trying to connect to all servers to check server status.. 76 Tue Mar 30 09:56:33 2021 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. 77 Tue Mar 30 09:56:33 2021 - [info] Reading application default configuration from /etc/mha/app1.cnf.. 78 Tue Mar 30 09:56:33 2021 - [info] Reading server configuration from /etc/mha/app1.cnf.. 79 Tue Mar 30 09:56:34 2021 - [info] GTID failover mode = 1 80 Tue Mar 30 09:56:34 2021 - [info] Dead Servers: 81 Tue Mar 30 09:56:34 2021 - [info] 192.168.10.11(192.168.10.11:3306) 82 Tue Mar 30 09:56:34 2021 - [info] Alive Servers: 83 Tue Mar 30 09:56:34 2021 - [info] 192.168.10.12(192.168.10.12:3306) 84 Tue Mar 30 09:56:34 2021 - [info] 192.168.10.13(192.168.10.13:3306) 85 Tue Mar 30 09:56:34 2021 - [info] Alive Slaves: 86 Tue Mar 30 09:56:34 2021 - [info] 192.168.10.12(192.168.10.12:3306) Version=5.7.27-log (oldest major version between slaves) log-bin:enabled 87 Tue Mar 30 09:56:34 2021 - [info] GTID ON 88 Tue Mar 30 09:56:34 2021 - [info] Replicating from 192.168.10.11(192.168.10.11:3306) 89 Tue Mar 30 09:56:34 2021 - [info] Primary candidate for the new Master (candidate_master is set) 90 Tue Mar 30 09:56:34 2021 - [info] 192.168.10.13(192.168.10.13:3306) Version=5.7.27-log (oldest major version between slaves) log-bin:enabled 91 Tue Mar 30 09:56:34 2021 - [info] GTID ON 92 Tue Mar 30 09:56:34 2021 - [info] Replicating from 192.168.10.11(192.168.10.11:3306) 93 Tue Mar 30 09:56:34 2021 - [info] Checking slave configurations.. 94 Tue Mar 30 09:56:34 2021 - [info] Checking replication filtering settings.. 95 Tue Mar 30 09:56:34 2021 - [info] Replication filtering check ok. 96 Tue Mar 30 09:56:34 2021 - [info] Master is down! 97 Tue Mar 30 09:56:34 2021 - [info] Terminating monitoring script. 98 Tue Mar 30 09:56:34 2021 - [info] Got exit code 20 (Master dead). 99 Tue Mar 30 09:56:34 2021 - [info] MHA::MasterFailover version 0.58. 100 Tue Mar 30 09:56:34 2021 - [info] Starting master failover. 101 Tue Mar 30 09:56:34 2021 - [info] 102 103 ########################################################################################### 104 # phase 1: 检查MySQL主从节点配置信息 105 ########################################################################################### 106 Tue Mar 30 09:56:34 2021 - [info] * Phase 1: Configuration Check Phase.. 107 Tue Mar 30 09:56:34 2021 - [info] 108 Tue Mar 30 09:56:35 2021 - [info] GTID failover mode = 1 109 Tue Mar 30 09:56:35 2021 - [info] Dead Servers: 110 Tue Mar 30 09:56:35 2021 - [info] 192.168.10.11(192.168.10.11:3306) 111 Tue Mar 30 09:56:35 2021 - [info] Checking master reachability via MySQL(double check)... 112 Tue Mar 30 09:56:35 2021 - [info] ok. 113 Tue Mar 30 09:56:35 2021 - [info] Alive Servers: 114 Tue Mar 30 09:56:35 2021 - [info] 192.168.10.12(192.168.10.12:3306) 115 Tue Mar 30 09:56:35 2021 - [info] 192.168.10.13(192.168.10.13:3306) 116 Tue Mar 30 09:56:35 2021 - [info] Alive Slaves: 117 Tue Mar 30 09:56:35 2021 - [info] 192.168.10.12(192.168.10.12:3306) Version=5.7.27-log (oldest major version between slaves) log-bin:enabled 118 Tue Mar 30 09:56:35 2021 - [info] GTID ON 119 Tue Mar 30 09:56:35 2021 - [info] Replicating from 192.168.10.11(192.168.10.11:3306) 120 Tue Mar 30 09:56:35 2021 - [info] Primary candidate for the new Master (candidate_master is set) 121 Tue Mar 30 09:56:35 2021 - [info] 192.168.10.13(192.168.10.13:3306) Version=5.7.27-log (oldest major version between slaves) log-bin:enabled 122 Tue Mar 30 09:56:35 2021 - [info] GTID ON 123 Tue Mar 30 09:56:35 2021 - [info] Replicating from 192.168.10.11(192.168.10.11:3306) 124 Tue Mar 30 09:56:35 2021 - [info] Starting GTID based failover. 125 Tue Mar 30 09:56:35 2021 - [info] 126 Tue Mar 30 09:56:35 2021 - [info] ** Phase 1: Configuration Check Phase completed. 127 Tue Mar 30 09:56:35 2021 - [info] 128 129 ########################################################################################### 130 # phase 2: ① 关闭老的主节点的VIP 131 # ② 关闭老的主节点服务器,我没有配置关闭服务器脚本,因此略过 132 ########################################################################################### 133 Tue Mar 30 09:56:35 2021 - [info] * Phase 2: Dead Master Shutdown Phase.. 134 Tue Mar 30 09:56:35 2021 - [info] 135 Tue Mar 30 09:56:35 2021 - [info] Forcing shutdown so that applications never connect to the current master.. 136 Tue Mar 30 09:56:35 2021 - [info] Executing master IP deactivation script: 137 Tue Mar 30 09:56:35 2021 - [info] /mha/mha4mysql-manager-master/bin/master_ip_failover --orig_master_host=192.168.10.11 --orig_master_ip=192.168.10.11 --orig_master_port=3306 --command=stopssh --ssh_user=root 138 139 140 IN SCRIPT TEST====/sbin/ifconfig ens34:1 down==/sbin/ifconfig ens34:1 192.168.10.10/24=== 141 142 Disabling the VIP on old master: 192.168.10.11 143 Tue Mar 30 09:56:35 2021 - [info] done. 144 Tue Mar 30 09:56:35 2021 - [warning] shutdown_script is not set. Skipping explicit shutting down of the dead master. 145 Tue Mar 30 09:56:35 2021 - [info] * Phase 2: Dead Master Shutdown Phase completed. 146 Tue Mar 30 09:56:35 2021 - [info] 147 148 ########################################################################################### 149 # phase 3: 主节点选举 150 # phase 3.1 : 确认所有数据库节点最新的binlog日志位置,以决定哪个节点的数据是最新的 151 # phase 3.2 : 选取新的MySQL主节点,选举方式取决于章节《(6.2)选择哪个主机作为主节点》, 152 # 日志中有2个phase 3.3,把第一个当做3.2 153 # phase 3.3 : 选取新的主节点,应用差异日志,激活虚拟IP,设置新的主节点为读写状态 154 ########################################################################################### 155 Tue Mar 30 09:56:35 2021 - [info] * Phase 3: Master Recovery Phase.. 156 Tue Mar 30 09:56:35 2021 - [info] 157 Tue Mar 30 09:56:35 2021 - [info] * Phase 3.1: Getting Latest Slaves Phase.. 158 Tue Mar 30 09:56:35 2021 - [info] 159 Tue Mar 30 09:56:35 2021 - [info] The latest binary log file/position on all slaves is node1-bin.000011:194 160 Tue Mar 30 09:56:35 2021 - [info] Retrieved Gtid Set: 2db1f74f-8790-11eb-b668-000c29d1545c:605-94186 161 Tue Mar 30 09:56:35 2021 - [info] Latest slaves (Slaves that received relay log files to the latest): 162 Tue Mar 30 09:56:35 2021 - [info] 192.168.10.12(192.168.10.12:3306) Version=5.7.27-log (oldest major version between slaves) log-bin:enabled 163 Tue Mar 30 09:56:35 2021 - [info] GTID ON 164 Tue Mar 30 09:56:35 2021 - [info] Replicating from 192.168.10.11(192.168.10.11:3306) 165 Tue Mar 30 09:56:35 2021 - [info] Primary candidate for the new Master (candidate_master is set) 166 Tue Mar 30 09:56:35 2021 - [info] 192.168.10.13(192.168.10.13:3306) Version=5.7.27-log (oldest major version between slaves) log-bin:enabled 167 Tue Mar 30 09:56:35 2021 - [info] GTID ON 168 Tue Mar 30 09:56:35 2021 - [info] Replicating from 192.168.10.11(192.168.10.11:3306) 169 Tue Mar 30 09:56:35 2021 - [info] The oldest binary log file/position on all slaves is node1-bin.000011:194 170 Tue Mar 30 09:56:35 2021 - [info] Retrieved Gtid Set: 2db1f74f-8790-11eb-b668-000c29d1545c:605-94186 171 Tue Mar 30 09:56:35 2021 - [info] Oldest slaves: 172 Tue Mar 30 09:56:35 2021 - [info] 192.168.10.12(192.168.10.12:3306) Version=5.7.27-log (oldest major version between slaves) log-bin:enabled 173 Tue Mar 30 09:56:35 2021 - [info] GTID ON 174 Tue Mar 30 09:56:35 2021 - [info] Replicating from 192.168.10.11(192.168.10.11:3306) 175 Tue Mar 30 09:56:35 2021 - [info] Primary candidate for the new Master (candidate_master is set) 176 Tue Mar 30 09:56:35 2021 - [info] 192.168.10.13(192.168.10.13:3306) Version=5.7.27-log (oldest major version between slaves) log-bin:enabled 177 Tue Mar 30 09:56:35 2021 - [info] GTID ON 178 Tue Mar 30 09:56:35 2021 - [info] Replicating from 192.168.10.11(192.168.10.11:3306) 179 Tue Mar 30 09:56:35 2021 - [info] 180 Tue Mar 30 09:56:35 2021 - [info] * Phase 3.3: Determining New Master Phase.. 181 Tue Mar 30 09:56:35 2021 - [info] 182 Tue Mar 30 09:56:35 2021 - [info] Searching new master from slaves.. 183 Tue Mar 30 09:56:35 2021 - [info] Candidate masters from the configuration file: 184 Tue Mar 30 09:56:35 2021 - [info] 192.168.10.12(192.168.10.12:3306) Version=5.7.27-log (oldest major version between slaves) log-bin:enabled 185 Tue Mar 30 09:56:35 2021 - [info] GTID ON 186 Tue Mar 30 09:56:35 2021 - [info] Replicating from 192.168.10.11(192.168.10.11:3306) 187 Tue Mar 30 09:56:35 2021 - [info] Primary candidate for the new Master (candidate_master is set) 188 Tue Mar 30 09:56:35 2021 - [info] Non-candidate masters: 189 Tue Mar 30 09:56:35 2021 - [info] Searching from candidate_master slaves which have received the latest relay log events.. 190 Tue Mar 30 09:56:35 2021 - [info] New master is 192.168.10.12(192.168.10.12:3306) 191 Tue Mar 30 09:56:35 2021 - [info] Starting master failover.. 192 Tue Mar 30 09:56:35 2021 - [info] 193 From: 194 192.168.10.11(192.168.10.11:3306) (current master) 195 +--192.168.10.12(192.168.10.12:3306) 196 +--192.168.10.13(192.168.10.13:3306) 197 198 To: 199 192.168.10.12(192.168.10.12:3306) (new master) 200 +--192.168.10.13(192.168.10.13:3306) 201 Tue Mar 30 09:56:35 2021 - [info] 202 Tue Mar 30 09:56:35 2021 - [info] * Phase 3.3: New Master Recovery Phase.. 203 Tue Mar 30 09:56:35 2021 - [info] 204 Tue Mar 30 09:56:35 2021 - [info] Waiting all logs to be applied.. 205 Tue Mar 30 09:56:35 2021 - [info] done. 206 Tue Mar 30 09:56:35 2021 - [info] Getting new master's binlog name and position.. 207 Tue Mar 30 09:56:35 2021 - [info] node2-bin.000005:194 208 Tue Mar 30 09:56:35 2021 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='192.168.10.12', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='replica', MASTER_PASSWORD='xxx'; 209 Tue Mar 30 09:56:35 2021 - [info] Master Recovery succeeded. File:Pos:Exec_Gtid_Set: node2-bin.000005, 194, 2db1f74f-8790-11eb-b668-000c29d1545c:1-94186, 210 30753d6b-8790-11eb-864f-000c2999ad6c:1-2 211 Tue Mar 30 09:56:35 2021 - [info] Executing master IP activate script: 212 Tue Mar 30 09:56:35 2021 - [info] /mha/mha4mysql-manager-master/bin/master_ip_failover --command=start --ssh_user=root --orig_master_host=192.168.10.11 --orig_master_ip=192.168.10.11 --orig_master_port=3306 --new_master_host=192.168.10.12 --new_master_ip=192.168.10.12 --new_master_port=3306 --new_master_user='mhaadmin' --new_master_password=xxx 213 214 215 IN SCRIPT TEST====/sbin/ifconfig ens34:1 down==/sbin/ifconfig ens34:1 192.168.10.10/24=== 216 217 Enabling the VIP - 192.168.10.10/24 on the new master - 192.168.10.12 218 Tue Mar 30 09:56:36 2021 - [info] OK. 219 Tue Mar 30 09:56:36 2021 - [info] Setting read_only=0 on 192.168.10.12(192.168.10.12:3306).. 220 Tue Mar 30 09:56:36 2021 - [info] ok. 221 Tue Mar 30 09:56:36 2021 - [info] ** Finished master recovery successfully. 222 Tue Mar 30 09:56:36 2021 - [info] * Phase 3: Master Recovery Phase completed. 223 Tue Mar 30 09:56:36 2021 - [info] 224 225 ########################################################################################### 226 # phase 4: 从节点指向新的主节点 227 # 执行reset slave --> change master指向新的主节点 --> 开启slave 228 ########################################################################################### 229 Tue Mar 30 09:56:36 2021 - [info] * Phase 4: Slaves Recovery Phase.. 230 Tue Mar 30 09:56:36 2021 - [info] 231 Tue Mar 30 09:56:36 2021 - [info] 232 Tue Mar 30 09:56:36 2021 - [info] * Phase 4.1: Starting Slaves in parallel.. 233 Tue Mar 30 09:56:36 2021 - [info] 234 Tue Mar 30 09:56:36 2021 - [info] -- Slave recovery on host 192.168.10.13(192.168.10.13:3306) started, pid: 3995. Check tmp log /mha/mha4mysql-manager-master/app1/192.168.10.13_3306_20210330095634.log if it takes time.. 235 Tue Mar 30 09:56:37 2021 - [info] 236 Tue Mar 30 09:56:37 2021 - [info] Log messages from 192.168.10.13 ... 237 Tue Mar 30 09:56:37 2021 - [info] 238 Tue Mar 30 09:56:36 2021 - [info] Resetting slave 192.168.10.13(192.168.10.13:3306) and starting replication from the new master 192.168.10.12(192.168.10.12:3306).. 239 Tue Mar 30 09:56:36 2021 - [info] Executed CHANGE MASTER. 240 Tue Mar 30 09:56:36 2021 - [info] Slave started. 241 Tue Mar 30 09:56:36 2021 - [info] gtid_wait(2db1f74f-8790-11eb-b668-000c29d1545c:1-94186, 242 30753d6b-8790-11eb-864f-000c2999ad6c:1-2) completed on 192.168.10.13(192.168.10.13:3306). Executed 3 events. 243 Tue Mar 30 09:56:37 2021 - [info] End of log messages from 192.168.10.13. 244 Tue Mar 30 09:56:37 2021 - [info] -- Slave on host 192.168.10.13(192.168.10.13:3306) started. 245 Tue Mar 30 09:56:37 2021 - [info] All new slave servers recovered successfully. 246 Tue Mar 30 09:56:37 2021 - [info] 247 248 ########################################################################################### 249 # phase 5: 新的主节点清除之前的slave信息 250 # 新的主节点是之前的slave节点,即使已经变为主节点,通过show slave staus依然可以看到之前的信息, 251 # 该步骤的目的就是清除之前的slave信息 252 ########################################################################################### 253 Tue Mar 30 09:56:37 2021 - [info] * Phase 5: New master cleanup phase.. 254 Tue Mar 30 09:56:37 2021 - [info] 255 Tue Mar 30 09:56:37 2021 - [info] Resetting slave info on the new master.. 256 Tue Mar 30 09:56:37 2021 - [info] 192.168.10.12: Resetting slave info succeeded. 257 Tue Mar 30 09:56:37 2021 - [info] Master failover to 192.168.10.12(192.168.10.12:3306) completed successfully. 258 Tue Mar 30 09:56:37 2021 - [info] 259 260 261 ########################################################################################### 262 # 最后的结论 263 # 切换成功 264 ########################################################################################### 265 ----- Failover Report ----- 266 267 app1: MySQL Master failover 192.168.10.11(192.168.10.11:3306) to 192.168.10.12(192.168.10.12:3306) succeeded 268 269 Master 192.168.10.11(192.168.10.11:3306) is down! 270 271 Check MHA Manager logs at monitor:/mha/mha4mysql-manager-master/app1/log/manager.log for details. 272 273 Started automated(non-interactive) failover. 274 Invalidated master IP address on 192.168.10.11(192.168.10.11:3306) 275 Selected 192.168.10.12(192.168.10.12:3306) as a new master. 276 192.168.10.12(192.168.10.12:3306): OK: Applying all logs succeeded. 277 192.168.10.12(192.168.10.12:3306): OK: Activated master IP address. 278 192.168.10.13(192.168.10.13:3306): OK: Slave started, replicating from 192.168.10.12(192.168.10.12:3306) 279 192.168.10.12(192.168.10.12:3306): Resetting slave info succeeded. 280 Master failover to 192.168.10.12(192.168.10.12:3306) completed successfully. 281 282
(5.2)MHA故障切换测试(主节点服务器异常down)
测试环境:
主节点:192.168.10.11
从节点1:192.168.10.12
从节点2:192.168.10.13
STEP1:开启MHA Manager
[root@monitor bin]# nohup masterha_manager --conf=/etc/mha/app1.cnf --ignore_last_failover & [1] 22973 [root@monitor bin]# nohup: ignoring input and appending output to ‘nohup.out’
STEP2:在主节点node1关闭服务器
[root@node1 ~]# shutdown -h 0
STEP3:查看数据库是否发生了主服务器故障转移
查看节点2,发现该节点的从库信息已经消除,目前已经为主库
[root@node2 ~]# mysql -uroot -p123456 mysql> show slave status \G mysql> show master status \G *************************** 1. row *************************** File: node2-bin.000001 Position: 154 Binlog_Do_DB: Binlog_Ignore_DB: Executed_Gtid_Set: 2db1f74f-8790-11eb-b668-000c29d1545c:1-94186, 30753d6b-8790-11eb-864f-000c2999ad6c:1-2
查看节点3,发现其主节点信息已自动变更为节点2
[root@node3 ~]# mysql -uroot -p123456 mysql> show slave status \G *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 192.168.10.12 Master_User: replica Master_Port: 3306 Connect_Retry: 60 Master_Log_File: node2-bin.000001 Read_Master_Log_Pos: 154 Relay_Log_File: node3-relay-bin.000002 Relay_Log_Pos: 367 Relay_Master_Log_File: node2-bin.000001 Slave_IO_Running: Yes Slave_SQL_Running: Yes
STEP4:查看虚拟IP是否已经发生了漂移,确认已经漂移
[root@node2 ~]# ifconfig ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 10.1.45.51 netmask 255.255.255.0 broadcast 10.1.45.255 inet6 fe80::953b:2262:6137:ad20 prefixlen 64 scopeid 0x20<link> inet6 fe80::b39e:c76c:b3dc:4d74 prefixlen 64 scopeid 0x20<link> ether 00:0c:29:99:ad:6c txqueuelen 1000 (Ethernet) RX packets 87548 bytes 7624146 (7.2 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 16 bytes 1584 (1.5 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 ens34: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.10.12 netmask 255.255.255.0 broadcast 192.168.10.255 inet6 fe80::20c:29ff:fe99:ad76 prefixlen 64 scopeid 0x20<link> ether 00:0c:29:99:ad:76 txqueuelen 1000 (Ethernet) RX packets 225060 bytes 328243958 (313.0 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 12997 bytes 1013311 (989.5 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 ens34:1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.10.10 netmask 255.255.255.0 broadcast 192.168.10.255 ether 00:0c:29:99:ad:76 txqueuelen 1000 (Ethernet)
整个切换的日志信息如下:
1 [root@monitor ~]# tail -100f /mha/mha4mysql-manager-master/app1/log/manager.log 2 3 Tue Mar 30 16:25:15 2021 - [warning] Got timeout on MySQL Ping(SELECT) child process and killed it! at /usr/local/share/perl5/MHA/HealthCheck.pm line 432. 4 Tue Mar 30 16:25:15 2021 - [info] Executing secondary network check script: /usr/local/bin/masterha_secondary_check -s node2 -s node3 --user=root --master_host=node1 --master_ip=192.168.10.11 --master_port=3306 --user=root --master_host=192.168.10.11 --master_ip=192.168.10.11 --master_port=3306 --master_user=mhaadmin --master_password=mhaadmin --ping_type=SELECT 5 Tue Mar 30 16:25:15 2021 - [info] Executing SSH check script: exit 0 6 Tue Mar 30 16:25:20 2021 - [warning] HealthCheck: Got timeout on checking SSH connection to 192.168.10.11! at /usr/local/share/perl5/MHA/HealthCheck.pm line 343. 7 Tue Mar 30 16:25:20 2021 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '192.168.10.11' (4)) 8 Tue Mar 30 16:25:20 2021 - [warning] Connection failed 2 time(s).. 9 Monitoring server node2 is reachable, Master is not reachable from node2. OK. 10 Tue Mar 30 16:25:25 2021 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '192.168.10.11' (4)) 11 Tue Mar 30 16:25:25 2021 - [warning] Connection failed 3 time(s).. 12 Monitoring server node3 is reachable, Master is not reachable from node3. OK. 13 Tue Mar 30 16:25:25 2021 - [info] Master is not reachable from all other monitoring servers. Failover should start. 14 Tue Mar 30 16:25:30 2021 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '192.168.10.11' (4)) 15 Tue Mar 30 16:25:30 2021 - [warning] Connection failed 4 time(s).. 16 Tue Mar 30 16:25:30 2021 - [warning] Master is not reachable from health checker! 17 Tue Mar 30 16:25:30 2021 - [warning] Master 192.168.10.11(192.168.10.11:3306) is not reachable! 18 Tue Mar 30 16:25:30 2021 - [warning] SSH is NOT reachable. 19 Tue Mar 30 16:25:30 2021 - [info] Connecting to a master server failed. Reading configuration file /etc/masterha_default.cnf and /etc/mha/app1.cnf again, and trying to connect to all servers to check server status.. 20 Tue Mar 30 16:25:30 2021 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. 21 Tue Mar 30 16:25:30 2021 - [info] Reading application default configuration from /etc/mha/app1.cnf.. 22 Tue Mar 30 16:25:30 2021 - [info] Reading server configuration from /etc/mha/app1.cnf.. 23 Tue Mar 30 16:25:31 2021 - [info] GTID failover mode = 1 24 Tue Mar 30 16:25:31 2021 - [info] Dead Servers: 25 Tue Mar 30 16:25:31 2021 - [info] 192.168.10.11(192.168.10.11:3306) 26 Tue Mar 30 16:25:31 2021 - [info] Alive Servers: 27 Tue Mar 30 16:25:31 2021 - [info] 192.168.10.12(192.168.10.12:3306) 28 Tue Mar 30 16:25:31 2021 - [info] 192.168.10.13(192.168.10.13:3306) 29 Tue Mar 30 16:25:31 2021 - [info] Alive Slaves: 30 Tue Mar 30 16:25:31 2021 - [info] 192.168.10.12(192.168.10.12:3306) Version=5.7.27-log (oldest major version between slaves) log-bin:enabled 31 Tue Mar 30 16:25:31 2021 - [info] GTID ON 32 Tue Mar 30 16:25:31 2021 - [info] Replicating from 192.168.10.11(192.168.10.11:3306) 33 Tue Mar 30 16:25:31 2021 - [info] Primary candidate for the new Master (candidate_master is set) 34 Tue Mar 30 16:25:31 2021 - [info] 192.168.10.13(192.168.10.13:3306) Version=5.7.27-log (oldest major version between slaves) log-bin:enabled 35 Tue Mar 30 16:25:31 2021 - [info] GTID ON 36 Tue Mar 30 16:25:31 2021 - [info] Replicating from 192.168.10.11(192.168.10.11:3306) 37 Tue Mar 30 16:25:31 2021 - [info] Checking slave configurations.. 38 Tue Mar 30 16:25:31 2021 - [info] Checking replication filtering settings.. 39 Tue Mar 30 16:25:31 2021 - [info] Replication filtering check ok. 40 Tue Mar 30 16:25:31 2021 - [info] Master is down! 41 Tue Mar 30 16:25:31 2021 - [info] Terminating monitoring script. 42 Tue Mar 30 16:25:31 2021 - [info] Got exit code 20 (Master dead). 43 Tue Mar 30 16:25:31 2021 - [info] MHA::MasterFailover version 0.58. 44 Tue Mar 30 16:25:31 2021 - [info] Starting master failover. 45 Tue Mar 30 16:25:31 2021 - [info] 46 Tue Mar 30 16:25:31 2021 - [info] * Phase 1: Configuration Check Phase.. 47 Tue Mar 30 16:25:31 2021 - [info] 48 Tue Mar 30 16:25:32 2021 - [info] GTID failover mode = 1 49 Tue Mar 30 16:25:32 2021 - [info] Dead Servers: 50 Tue Mar 30 16:25:32 2021 - [info] 192.168.10.11(192.168.10.11:3306) 51 Tue Mar 30 16:25:32 2021 - [info] Checking master reachability via MySQL(double check)... 52 Tue Mar 30 16:25:33 2021 - [info] ok. 53 Tue Mar 30 16:25:33 2021 - [info] Alive Servers: 54 Tue Mar 30 16:25:33 2021 - [info] 192.168.10.12(192.168.10.12:3306) 55 Tue Mar 30 16:25:33 2021 - [info] 192.168.10.13(192.168.10.13:3306) 56 Tue Mar 30 16:25:33 2021 - [info] Alive Slaves: 57 Tue Mar 30 16:25:33 2021 - [info] 192.168.10.12(192.168.10.12:3306) Version=5.7.27-log (oldest major version between slaves) log-bin:enabled 58 Tue Mar 30 16:25:33 2021 - [info] GTID ON 59 Tue Mar 30 16:25:33 2021 - [info] Replicating from 192.168.10.11(192.168.10.11:3306) 60 Tue Mar 30 16:25:33 2021 - [info] Primary candidate for the new Master (candidate_master is set) 61 Tue Mar 30 16:25:33 2021 - [info] 192.168.10.13(192.168.10.13:3306) Version=5.7.27-log (oldest major version between slaves) log-bin:enabled 62 Tue Mar 30 16:25:33 2021 - [info] GTID ON 63 Tue Mar 30 16:25:33 2021 - [info] Replicating from 192.168.10.11(192.168.10.11:3306) 64 Tue Mar 30 16:25:33 2021 - [info] Starting GTID based failover. 65 Tue Mar 30 16:25:33 2021 - [info] 66 Tue Mar 30 16:25:33 2021 - [info] ** Phase 1: Configuration Check Phase completed. 67 Tue Mar 30 16:25:33 2021 - [info] 68 Tue Mar 30 16:25:33 2021 - [info] * Phase 2: Dead Master Shutdown Phase.. 69 Tue Mar 30 16:25:33 2021 - [info] 70 Tue Mar 30 16:25:33 2021 - [info] Forcing shutdown so that applications never connect to the current master.. 71 Tue Mar 30 16:25:33 2021 - [info] Executing master IP deactivation script: 72 Tue Mar 30 16:25:33 2021 - [info] /mha/mha4mysql-manager-master/bin/master_ip_failover --orig_master_host=192.168.10.11 --orig_master_ip=192.168.10.11 --orig_master_port=3306 --command=stop 73 74 75 IN SCRIPT TEST====/sbin/ifconfig ens34:1 down==/sbin/ifconfig ens34:1 192.168.10.10/24=== 76 77 Disabling the VIP on old master: 192.168.10.11 78 Tue Mar 30 16:25:33 2021 - [info] done. 79 Tue Mar 30 16:25:33 2021 - [warning] shutdown_script is not set. Skipping explicit shutting down of the dead master. 80 Tue Mar 30 16:25:33 2021 - [info] * Phase 2: Dead Master Shutdown Phase completed. 81 Tue Mar 30 16:25:33 2021 - [info] 82 Tue Mar 30 16:25:33 2021 - [info] * Phase 3: Master Recovery Phase.. 83 Tue Mar 30 16:25:33 2021 - [info] 84 Tue Mar 30 16:25:33 2021 - [info] * Phase 3.1: Getting Latest Slaves Phase.. 85 Tue Mar 30 16:25:33 2021 - [info] 86 Tue Mar 30 16:25:33 2021 - [info] The latest binary log file/position on all slaves is node1-bin.000001:154 87 Tue Mar 30 16:25:33 2021 - [info] Latest slaves (Slaves that received relay log files to the latest): 88 Tue Mar 30 16:25:33 2021 - [info] 192.168.10.12(192.168.10.12:3306) Version=5.7.27-log (oldest major version between slaves) log-bin:enabled 89 Tue Mar 30 16:25:33 2021 - [info] GTID ON 90 Tue Mar 30 16:25:33 2021 - [info] Replicating from 192.168.10.11(192.168.10.11:3306) 91 Tue Mar 30 16:25:33 2021 - [info] Primary candidate for the new Master (candidate_master is set) 92 Tue Mar 30 16:25:33 2021 - [info] 192.168.10.13(192.168.10.13:3306) Version=5.7.27-log (oldest major version between slaves) log-bin:enabled 93 Tue Mar 30 16:25:33 2021 - [info] GTID ON 94 Tue Mar 30 16:25:33 2021 - [info] Replicating from 192.168.10.11(192.168.10.11:3306) 95 Tue Mar 30 16:25:33 2021 - [info] The oldest binary log file/position on all slaves is node1-bin.000001:154 96 Tue Mar 30 16:25:33 2021 - [info] Oldest slaves: 97 Tue Mar 30 16:25:33 2021 - [info] 192.168.10.12(192.168.10.12:3306) Version=5.7.27-log (oldest major version between slaves) log-bin:enabled 98 Tue Mar 30 16:25:33 2021 - [info] GTID ON 99 Tue Mar 30 16:25:33 2021 - [info] Replicating from 192.168.10.11(192.168.10.11:3306) 100 Tue Mar 30 16:25:33 2021 - [info] Primary candidate for the new Master (candidate_master is set) 101 Tue Mar 30 16:25:33 2021 - [info] 192.168.10.13(192.168.10.13:3306) Version=5.7.27-log (oldest major version between slaves) log-bin:enabled 102 Tue Mar 30 16:25:33 2021 - [info] GTID ON 103 Tue Mar 30 16:25:33 2021 - [info] Replicating from 192.168.10.11(192.168.10.11:3306) 104 Tue Mar 30 16:25:33 2021 - [info] 105 Tue Mar 30 16:25:33 2021 - [info] * Phase 3.3: Determining New Master Phase.. 106 Tue Mar 30 16:25:33 2021 - [info] 107 Tue Mar 30 16:25:33 2021 - [info] Searching new master from slaves.. 108 Tue Mar 30 16:25:33 2021 - [info] Candidate masters from the configuration file: 109 Tue Mar 30 16:25:33 2021 - [info] 192.168.10.12(192.168.10.12:3306) Version=5.7.27-log (oldest major version between slaves) log-bin:enabled 110 Tue Mar 30 16:25:33 2021 - [info] GTID ON 111 Tue Mar 30 16:25:33 2021 - [info] Replicating from 192.168.10.11(192.168.10.11:3306) 112 Tue Mar 30 16:25:33 2021 - [info] Primary candidate for the new Master (candidate_master is set) 113 Tue Mar 30 16:25:33 2021 - [info] Non-candidate masters: 114 Tue Mar 30 16:25:33 2021 - [info] Searching from candidate_master slaves which have received the latest relay log events.. 115 Tue Mar 30 16:25:33 2021 - [info] New master is 192.168.10.12(192.168.10.12:3306) 116 Tue Mar 30 16:25:33 2021 - [info] Starting master failover.. 117 Tue Mar 30 16:25:33 2021 - [info] 118 From: 119 192.168.10.11(192.168.10.11:3306) (current master) 120 +--192.168.10.12(192.168.10.12:3306) 121 +--192.168.10.13(192.168.10.13:3306) 122 123 To: 124 192.168.10.12(192.168.10.12:3306) (new master) 125 +--192.168.10.13(192.168.10.13:3306) 126 Tue Mar 30 16:25:33 2021 - [info] 127 Tue Mar 30 16:25:33 2021 - [info] * Phase 3.3: New Master Recovery Phase.. 128 Tue Mar 30 16:25:33 2021 - [info] 129 Tue Mar 30 16:25:33 2021 - [info] Waiting all logs to be applied.. 130 Tue Mar 30 16:25:33 2021 - [info] done. 131 Tue Mar 30 16:25:33 2021 - [info] Getting new master's binlog name and position.. 132 Tue Mar 30 16:25:33 2021 - [info] node2-bin.000001:154 133 Tue Mar 30 16:25:33 2021 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='192.168.10.12', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='replica', MASTER_PASSWORD='xxx'; 134 Tue Mar 30 16:25:33 2021 - [info] Master Recovery succeeded. File:Pos:Exec_Gtid_Set: node2-bin.000001, 154, 2db1f74f-8790-11eb-b668-000c29d1545c:1-94186, 135 30753d6b-8790-11eb-864f-000c2999ad6c:1-2 136 Tue Mar 30 16:25:33 2021 - [info] Executing master IP activate script: 137 Tue Mar 30 16:25:33 2021 - [info] /mha/mha4mysql-manager-master/bin/master_ip_failover --command=start --ssh_user=root --orig_master_host=192.168.10.11 --orig_master_ip=192.168.10.11 --orig_master_port=3306 --new_master_host=192.168.10.12 --new_master_ip=192.168.10.12 --new_master_port=3306 --new_master_user='mhaadmin' --new_master_password=xxx 138 139 140 IN SCRIPT TEST====/sbin/ifconfig ens34:1 down==/sbin/ifconfig ens34:1 192.168.10.10/24=== 141 142 Enabling the VIP - 192.168.10.10/24 on the new master - 192.168.10.12 143 Tue Mar 30 16:25:33 2021 - [info] OK. 144 Tue Mar 30 16:25:33 2021 - [info] Setting read_only=0 on 192.168.10.12(192.168.10.12:3306).. 145 Tue Mar 30 16:25:33 2021 - [info] ok. 146 Tue Mar 30 16:25:33 2021 - [info] ** Finished master recovery successfully. 147 Tue Mar 30 16:25:33 2021 - [info] * Phase 3: Master Recovery Phase completed. 148 Tue Mar 30 16:25:33 2021 - [info] 149 Tue Mar 30 16:25:33 2021 - [info] * Phase 4: Slaves Recovery Phase.. 150 Tue Mar 30 16:25:33 2021 - [info] 151 Tue Mar 30 16:25:33 2021 - [info] 152 Tue Mar 30 16:25:33 2021 - [info] * Phase 4.1: Starting Slaves in parallel.. 153 Tue Mar 30 16:25:33 2021 - [info] 154 Tue Mar 30 16:25:33 2021 - [info] -- Slave recovery on host 192.168.10.13(192.168.10.13:3306) started, pid: 23239. Check tmp log /mha/mha4mysql-manager-master/app1/192.168.10.13_3306_20210330162531.log if it takes time.. 155 Tue Mar 30 16:25:35 2021 - [info] 156 Tue Mar 30 16:25:35 2021 - [info] Log messages from 192.168.10.13 ... 157 Tue Mar 30 16:25:35 2021 - [info] 158 Tue Mar 30 16:25:33 2021 - [info] Resetting slave 192.168.10.13(192.168.10.13:3306) and starting replication from the new master 192.168.10.12(192.168.10.12:3306).. 159 Tue Mar 30 16:25:33 2021 - [info] Executed CHANGE MASTER. 160 Tue Mar 30 16:25:34 2021 - [info] Slave started. 161 Tue Mar 30 16:25:34 2021 - [info] gtid_wait(2db1f74f-8790-11eb-b668-000c29d1545c:1-94186, 162 30753d6b-8790-11eb-864f-000c2999ad6c:1-2) completed on 192.168.10.13(192.168.10.13:3306). Executed 0 events. 163 Tue Mar 30 16:25:35 2021 - [info] End of log messages from 192.168.10.13. 164 Tue Mar 30 16:25:35 2021 - [info] -- Slave on host 192.168.10.13(192.168.10.13:3306) started. 165 Tue Mar 30 16:25:35 2021 - [info] All new slave servers recovered successfully. 166 Tue Mar 30 16:25:35 2021 - [info] 167 Tue Mar 30 16:25:35 2021 - [info] * Phase 5: New master cleanup phase.. 168 Tue Mar 30 16:25:35 2021 - [info] 169 Tue Mar 30 16:25:35 2021 - [info] Resetting slave info on the new master.. 170 Tue Mar 30 16:25:35 2021 - [info] 192.168.10.12: Resetting slave info succeeded. 171 Tue Mar 30 16:25:35 2021 - [info] Master failover to 192.168.10.12(192.168.10.12:3306) completed successfully. 172 Tue Mar 30 16:25:35 2021 - [info] 173 174 ----- Failover Report ----- 175 176 app1: MySQL Master failover 192.168.10.11(192.168.10.11:3306) to 192.168.10.12(192.168.10.12:3306) succeeded 177 178 Master 192.168.10.11(192.168.10.11:3306) is down! 179 180 Check MHA Manager logs at monitor:/mha/mha4mysql-manager-master/app1/log/manager.log for details. 181 182 Started automated(non-interactive) failover. 183 Invalidated master IP address on 192.168.10.11(192.168.10.11:3306) 184 Selected 192.168.10.12(192.168.10.12:3306) as a new master. 185 192.168.10.12(192.168.10.12:3306): OK: Applying all logs succeeded. 186 192.168.10.12(192.168.10.12:3306): OK: Activated master IP address. 187 192.168.10.13(192.168.10.13:3306): OK: Slave started, replicating from 192.168.10.12(192.168.10.12:3306) 188 192.168.10.12(192.168.10.12:3306): Resetting slave info succeeded. 189 Master failover to 192.168.10.12(192.168.10.12:3306) completed successfully.
(5.3)MHA手动故障切换测试
测试环境:
主节点 :192.168.10.11
从节点1:192.168.10.12
从节点2:192.168.10.13
STEP1:手动故障切换操作需要在mha manager停止的情况下操作
[root@monitor ~]# masterha_check_status --conf=/etc/mha/app1.cnf app1 is stopped(2:NOT_RUNNING).
STEP2:在主节点node1关闭MySQL服务
[root@node1 ~]# service mysqld stop
STEP3:手动执行故障切换,默认切换到192.168.10.12,因为这台机器配置了candidate_master=1参数。我们这里主节点强制切到192.168.10.13
masterha_master_switch --master_state=dead --conf=/etc/mha/app1.cnf --dead_master_host=192.168.10.11 --new_master_host=192.168.10.13 --ignore_last_failover
STEP4:查看节点2,发现其主节点信息已自动变更为节点3
[root@node2 ~]# mysql -uroot -p123456 mysql> show slave status \G *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 192.168.10.13 Master_User: replica Master_Port: 3306 Connect_Retry: 60 Master_Log_File: node3-bin.000006 Read_Master_Log_Pos: 194 Relay_Log_File: node2-relay-bin.000009 Relay_Log_Pos: 407 Relay_Master_Log_File: node3-bin.000006 Slave_IO_Running: Yes Slave_SQL_Running: Yes
STEP5:查看虚拟IP是否已经发生了漂移,确认已经漂移
[root@node3 ~]# ifconfig ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 10.1.45.85 netmask 255.255.255.0 broadcast 10.1.45.255 inet6 fe80::8e05:c8ea:5953:4213 prefixlen 64 scopeid 0x20<link> inet6 fe80::953b:2262:6137:ad20 prefixlen 64 scopeid 0x20<link> inet6 fe80::b39e:c76c:b3dc:4d74 prefixlen 64 scopeid 0x20<link> ether 00:0c:29:25:bd:bb txqueuelen 1000 (Ethernet) RX packets 140091 bytes 12147844 (11.5 MiB) RX errors 0 dropped 1 overruns 0 frame 0 TX packets 455 bytes 30047 (29.3 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 ens34: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.10.13 netmask 255.255.255.0 broadcast 192.168.10.255 inet6 fe80::20c:29ff:fe25:bdc5 prefixlen 64 scopeid 0x20<link> ether 00:0c:29:25:bd:c5 txqueuelen 1000 (Ethernet) RX packets 6423 bytes 600863 (586.7 KiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 5034 bytes 1318734 (1.2 MiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 ens34:1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.10.10 netmask 255.255.255.0 broadcast 192.168.10.255 ether 00:0c:29:25:bd:c5 txqueuelen 1000 (Ethernet)
手动故障切换相关日志:
1 [root@monitor ~]# masterha_master_switch --master_state=dead --conf=/etc/mha/app1.cnf --dead_master_host=192.168.10.11 --new_master_host=192.168.10.13 --ignore_last_failover 2 --dead_master_ip=<dead_master_ip> is not set. Using 192.168.10.11. 3 --dead_master_port=<dead_master_port> is not set. Using 3306. 4 Tue Mar 30 17:07:51 2021 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. 5 Tue Mar 30 17:07:51 2021 - [info] Reading application default configuration from /etc/mha/app1.cnf.. 6 Tue Mar 30 17:07:51 2021 - [info] Reading server configuration from /etc/mha/app1.cnf.. 7 Tue Mar 30 17:07:51 2021 - [info] MHA::MasterFailover version 0.58. 8 Tue Mar 30 17:07:51 2021 - [info] Starting master failover. 9 Tue Mar 30 17:07:51 2021 - [info] 10 Tue Mar 30 17:07:51 2021 - [info] * Phase 1: Configuration Check Phase.. 11 Tue Mar 30 17:07:51 2021 - [info] 12 Tue Mar 30 17:07:52 2021 - [info] GTID failover mode = 1 13 Tue Mar 30 17:07:52 2021 - [info] Dead Servers: 14 Tue Mar 30 17:07:52 2021 - [info] 192.168.10.11(192.168.10.11:3306) 15 Tue Mar 30 17:07:52 2021 - [info] Checking master reachability via MySQL(double check)... 16 Tue Mar 30 17:07:52 2021 - [info] ok. 17 Tue Mar 30 17:07:52 2021 - [info] Alive Servers: 18 Tue Mar 30 17:07:52 2021 - [info] 192.168.10.12(192.168.10.12:3306) 19 Tue Mar 30 17:07:52 2021 - [info] 192.168.10.13(192.168.10.13:3306) 20 Tue Mar 30 17:07:52 2021 - [info] Alive Slaves: 21 Tue Mar 30 17:07:52 2021 - [info] 192.168.10.12(192.168.10.12:3306) Version=5.7.27-log (oldest major version between slaves) log-bin:enabled 22 Tue Mar 30 17:07:52 2021 - [info] GTID ON 23 Tue Mar 30 17:07:52 2021 - [info] Replicating from 192.168.10.11(192.168.10.11:3306) 24 Tue Mar 30 17:07:52 2021 - [info] Primary candidate for the new Master (candidate_master is set) 25 Tue Mar 30 17:07:52 2021 - [info] 192.168.10.13(192.168.10.13:3306) Version=5.7.27-log (oldest major version between slaves) log-bin:enabled 26 Tue Mar 30 17:07:52 2021 - [info] GTID ON 27 Tue Mar 30 17:07:52 2021 - [info] Replicating from 192.168.10.11(192.168.10.11:3306) 28 Master 192.168.10.11(192.168.10.11:3306) is dead. Proceed? (yes/NO): yes 29 Tue Mar 30 17:07:54 2021 - [info] Starting GTID based failover. 30 Tue Mar 30 17:07:54 2021 - [info] 31 Tue Mar 30 17:07:54 2021 - [info] ** Phase 1: Configuration Check Phase completed. 32 Tue Mar 30 17:07:54 2021 - [info] 33 Tue Mar 30 17:07:54 2021 - [info] * Phase 2: Dead Master Shutdown Phase.. 34 Tue Mar 30 17:07:54 2021 - [info] 35 Tue Mar 30 17:07:54 2021 - [info] HealthCheck: SSH to 192.168.10.11 is reachable. 36 Tue Mar 30 17:07:54 2021 - [info] Forcing shutdown so that applications never connect to the current master.. 37 Tue Mar 30 17:07:54 2021 - [info] Executing master IP deactivation script: 38 Tue Mar 30 17:07:54 2021 - [info] /mha/mha4mysql-manager-master/bin/master_ip_failover --orig_master_host=192.168.10.11 --orig_master_ip=192.168.10.11 --orig_master_port=3306 --command=stopssh --ssh_user=root 39 40 41 IN SCRIPT TEST====/sbin/ifconfig ens34:1 down==/sbin/ifconfig ens34:1 192.168.10.10/24=== 42 43 Disabling the VIP on old master: 192.168.10.11 44 SIOCSIFFLAGS: Cannot assign requested address 45 Tue Mar 30 17:07:55 2021 - [info] done. 46 Tue Mar 30 17:07:55 2021 - [warning] shutdown_script is not set. Skipping explicit shutting down of the dead master. 47 Tue Mar 30 17:07:55 2021 - [info] * Phase 2: Dead Master Shutdown Phase completed. 48 Tue Mar 30 17:07:55 2021 - [info] 49 Tue Mar 30 17:07:55 2021 - [info] * Phase 3: Master Recovery Phase.. 50 Tue Mar 30 17:07:55 2021 - [info] 51 Tue Mar 30 17:07:55 2021 - [info] * Phase 3.1: Getting Latest Slaves Phase.. 52 Tue Mar 30 17:07:55 2021 - [info] 53 Tue Mar 30 17:07:55 2021 - [info] The latest binary log file/position on all slaves is node1-bin.000004:154 54 Tue Mar 30 17:07:55 2021 - [info] Latest slaves (Slaves that received relay log files to the latest): 55 Tue Mar 30 17:07:55 2021 - [info] 192.168.10.12(192.168.10.12:3306) Version=5.7.27-log (oldest major version between slaves) log-bin:enabled 56 Tue Mar 30 17:07:55 2021 - [info] GTID ON 57 Tue Mar 30 17:07:55 2021 - [info] Replicating from 192.168.10.11(192.168.10.11:3306) 58 Tue Mar 30 17:07:55 2021 - [info] Primary candidate for the new Master (candidate_master is set) 59 Tue Mar 30 17:07:55 2021 - [info] 192.168.10.13(192.168.10.13:3306) Version=5.7.27-log (oldest major version between slaves) log-bin:enabled 60 Tue Mar 30 17:07:55 2021 - [info] GTID ON 61 Tue Mar 30 17:07:55 2021 - [info] Replicating from 192.168.10.11(192.168.10.11:3306) 62 Tue Mar 30 17:07:55 2021 - [info] The oldest binary log file/position on all slaves is node1-bin.000004:154 63 Tue Mar 30 17:07:55 2021 - [info] Oldest slaves: 64 Tue Mar 30 17:07:55 2021 - [info] 192.168.10.12(192.168.10.12:3306) Version=5.7.27-log (oldest major version between slaves) log-bin:enabled 65 Tue Mar 30 17:07:55 2021 - [info] GTID ON 66 Tue Mar 30 17:07:55 2021 - [info] Replicating from 192.168.10.11(192.168.10.11:3306) 67 Tue Mar 30 17:07:55 2021 - [info] Primary candidate for the new Master (candidate_master is set) 68 Tue Mar 30 17:07:55 2021 - [info] 192.168.10.13(192.168.10.13:3306) Version=5.7.27-log (oldest major version between slaves) log-bin:enabled 69 Tue Mar 30 17:07:55 2021 - [info] GTID ON 70 Tue Mar 30 17:07:55 2021 - [info] Replicating from 192.168.10.11(192.168.10.11:3306) 71 Tue Mar 30 17:07:55 2021 - [info] 72 Tue Mar 30 17:07:55 2021 - [info] * Phase 3.3: Determining New Master Phase.. 73 Tue Mar 30 17:07:55 2021 - [info] 74 Tue Mar 30 17:07:55 2021 - [info] 192.168.10.13 can be new master. 75 Tue Mar 30 17:07:55 2021 - [info] New master is 192.168.10.13(192.168.10.13:3306) 76 Tue Mar 30 17:07:55 2021 - [info] Starting master failover.. 77 Tue Mar 30 17:07:55 2021 - [info] 78 From: 79 192.168.10.11(192.168.10.11:3306) (current master) 80 +--192.168.10.12(192.168.10.12:3306) 81 +--192.168.10.13(192.168.10.13:3306) 82 83 To: 84 192.168.10.13(192.168.10.13:3306) (new master) 85 +--192.168.10.12(192.168.10.12:3306) 86 87 Starting master switch from 192.168.10.11(192.168.10.11:3306) to 192.168.10.13(192.168.10.13:3306)? (yes/NO): yes 88 Tue Mar 30 17:07:56 2021 - [info] New master decided manually is 192.168.10.13(192.168.10.13:3306) 89 Tue Mar 30 17:07:56 2021 - [info] 90 Tue Mar 30 17:07:56 2021 - [info] * Phase 3.3: New Master Recovery Phase.. 91 Tue Mar 30 17:07:56 2021 - [info] 92 Tue Mar 30 17:07:56 2021 - [info] Waiting all logs to be applied.. 93 Tue Mar 30 17:07:56 2021 - [info] done. 94 Tue Mar 30 17:07:56 2021 - [info] Replicating from the latest slave 192.168.10.12(192.168.10.12:3306) and waiting to apply.. 95 Tue Mar 30 17:07:56 2021 - [info] Waiting all logs to be applied on the latest slave.. 96 Tue Mar 30 17:07:56 2021 - [info] Resetting slave 192.168.10.13(192.168.10.13:3306) and starting replication from the new master 192.168.10.12(192.168.10.12:3306).. 97 Tue Mar 30 17:07:56 2021 - [info] Executed CHANGE MASTER. 98 Tue Mar 30 17:07:57 2021 - [info] Slave started. 99 Tue Mar 30 17:07:57 2021 - [info] Waiting to execute all relay logs on 192.168.10.13(192.168.10.13:3306).. 100 Tue Mar 30 17:07:57 2021 - [info] master_pos_wait(node2-bin.000001:154) completed on 192.168.10.13(192.168.10.13:3306). Executed 0 events. 101 Tue Mar 30 17:07:57 2021 - [info] done. 102 Tue Mar 30 17:07:57 2021 - [info] done. 103 Tue Mar 30 17:07:57 2021 - [info] Getting new master's binlog name and position.. 104 Tue Mar 30 17:07:57 2021 - [info] node3-bin.000006:194 105 Tue Mar 30 17:07:57 2021 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='192.168.10.13', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='replica', MASTER_PASSWORD='xxx'; 106 Tue Mar 30 17:07:57 2021 - [info] Master Recovery succeeded. File:Pos:Exec_Gtid_Set: node3-bin.000006, 194, 2db1f74f-8790-11eb-b668-000c29d1545c:1-94186, 107 30753d6b-8790-11eb-864f-000c2999ad6c:1-2, 108 32a16250-8790-11eb-b587-000c2925bdbb:1-2 109 Tue Mar 30 17:07:57 2021 - [info] Executing master IP activate script: 110 Tue Mar 30 17:07:57 2021 - [info] /mha/mha4mysql-manager-master/bin/master_ip_failover --command=start --ssh_user=root --orig_master_host=192.168.10.11 --orig_master_ip=192.168.10.11 --orig_master_port=3306 --new_master_host=192.168.10.13 --new_master_ip=192.168.10.13 --new_master_port=3306 --new_master_user='mhaadmin' --new_master_password=xxx 111 112 113 IN SCRIPT TEST====/sbin/ifconfig ens34:1 down==/sbin/ifconfig ens34:1 192.168.10.10/24=== 114 115 Enabling the VIP - 192.168.10.10/24 on the new master - 192.168.10.13 116 Tue Mar 30 17:07:57 2021 - [info] OK. 117 Tue Mar 30 17:07:57 2021 - [info] Setting read_only=0 on 192.168.10.13(192.168.10.13:3306).. 118 Tue Mar 30 17:07:57 2021 - [info] ok. 119 Tue Mar 30 17:07:57 2021 - [info] ** Finished master recovery successfully. 120 Tue Mar 30 17:07:57 2021 - [info] * Phase 3: Master Recovery Phase completed. 121 Tue Mar 30 17:07:57 2021 - [info] 122 Tue Mar 30 17:07:57 2021 - [info] * Phase 4: Slaves Recovery Phase.. 123 Tue Mar 30 17:07:57 2021 - [info] 124 Tue Mar 30 17:07:57 2021 - [info] 125 Tue Mar 30 17:07:57 2021 - [info] * Phase 4.1: Starting Slaves in parallel.. 126 Tue Mar 30 17:07:57 2021 - [info] 127 Tue Mar 30 17:07:57 2021 - [info] -- Slave recovery on host 192.168.10.12(192.168.10.12:3306) started, pid: 25496. Check tmp log /mha/mha4mysql-manager-master/app1/192.168.10.12_3306_20210330170751.log if it takes time.. 128 Tue Mar 30 17:07:59 2021 - [info] 129 Tue Mar 30 17:07:59 2021 - [info] Log messages from 192.168.10.12 ... 130 Tue Mar 30 17:07:59 2021 - [info] 131 Tue Mar 30 17:07:57 2021 - [info] Resetting slave 192.168.10.12(192.168.10.12:3306) and starting replication from the new master 192.168.10.13(192.168.10.13:3306).. 132 Tue Mar 30 17:07:57 2021 - [info] Executed CHANGE MASTER. 133 Tue Mar 30 17:07:58 2021 - [info] Slave started. 134 Tue Mar 30 17:07:58 2021 - [info] gtid_wait(2db1f74f-8790-11eb-b668-000c29d1545c:1-94186, 135 30753d6b-8790-11eb-864f-000c2999ad6c:1-2, 136 32a16250-8790-11eb-b587-000c2925bdbb:1-2) completed on 192.168.10.12(192.168.10.12:3306). Executed 0 events. 137 Tue Mar 30 17:07:59 2021 - [info] End of log messages from 192.168.10.12. 138 Tue Mar 30 17:07:59 2021 - [info] -- Slave on host 192.168.10.12(192.168.10.12:3306) started. 139 Tue Mar 30 17:07:59 2021 - [info] All new slave servers recovered successfully. 140 Tue Mar 30 17:07:59 2021 - [info] 141 Tue Mar 30 17:07:59 2021 - [info] * Phase 5: New master cleanup phase.. 142 Tue Mar 30 17:07:59 2021 - [info] 143 Tue Mar 30 17:07:59 2021 - [info] Resetting slave info on the new master.. 144 Tue Mar 30 17:07:59 2021 - [info] 192.168.10.13: Resetting slave info succeeded. 145 Tue Mar 30 17:07:59 2021 - [info] Master failover to 192.168.10.13(192.168.10.13:3306) completed successfully. 146 Tue Mar 30 17:07:59 2021 - [info] 147 148 ----- Failover Report ----- 149 150 app1: MySQL Master failover 192.168.10.11(192.168.10.11:3306) to 192.168.10.13(192.168.10.13:3306) succeeded 151 152 Master 192.168.10.11(192.168.10.11:3306) is down! 153 154 Check MHA Manager logs at monitor for details. 155 156 Started manual(interactive) failover. 157 Invalidated master IP address on 192.168.10.11(192.168.10.11:3306) 158 Selected 192.168.10.13(192.168.10.13:3306) as a new master. 159 192.168.10.13(192.168.10.13:3306): OK: Applying all logs succeeded. 160 192.168.10.13(192.168.10.13:3306): OK: Activated master IP address. 161 192.168.10.12(192.168.10.12:3306): OK: Slave started, replicating from 192.168.10.13(192.168.10.13:3306) 162 192.168.10.13(192.168.10.13:3306): Resetting slave info succeeded. 163 Master failover to 192.168.10.13(192.168.10.13:3306) completed successfully. 164 165
(5.4)MHA手动在线主从切换测试
测试环境:
主节点 :192.168.10.11
从节点1:192.168.10.12
从节点2:192.168.10.13
STEP1:手动故障切换操作需要在mha manager停止的情况下操作
[root@monitor ~]# masterha_check_status --conf=/etc/mha/app1.cnf app1 is stopped(2:NOT_RUNNING).
STEP2:手动执行在线主从切换,这里我们将主节点强制切到192.168.10.13,并将之前的主节点192.168.10.11转换为备节点
masterha_master_switch --master_state=alive --conf=/etc/mha/app1.cnf --new_master_host=192.168.10.13 --orig_master_is_new_slave
STEP3:查看节点1,发现其主节点信息已自动变更为节点3
[root@node1 ~]# mysql -uroot -p123456 mysql> show slave status \G *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 192.168.10.13 Master_User: replica Master_Port: 3306 Connect_Retry: 60 Master_Log_File: node3-bin.000007 Read_Master_Log_Pos: 194 Relay_Log_File: node1-relay-bin.000002 Relay_Log_Pos: 367 Relay_Master_Log_File: node3-bin.000007 Slave_IO_Running: Yes Slave_SQL_Running: Yes
虚拟IP也漂移到了节点3
[root@node3 ~]# ifconfig ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 10.1.45.85 netmask 255.255.255.0 broadcast 10.1.45.255 inet6 fe80::953b:2262:6137:ad20 prefixlen 64 scopeid 0x20<link> ether 00:0c:29:25:bd:bb txqueuelen 1000 (Ethernet) RX packets 32135 bytes 2922975 (2.7 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 79 bytes 5526 (5.3 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 ens34: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.10.13 netmask 255.255.255.0 broadcast 192.168.10.255 inet6 fe80::20c:29ff:fe25:bdc5 prefixlen 64 scopeid 0x20<link> ether 00:0c:29:25:bd:c5 txqueuelen 1000 (Ethernet) RX packets 1851 bytes 181301 (177.0 KiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 1496 bytes 575947 (562.4 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 ens34:1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.10.10 netmask 255.255.255.0 broadcast 192.168.10.255 ether 00:0c:29:25:bd:c5 txqueuelen 1000 (Ethernet)
手动在线切换操作日志:
1 [root@monitor ~]# masterha_master_switch --master_state=alive --conf=/etc/mha/app1.cnf --new_master_host=192.168.10.13 --orig_master_is_new_slave 2 Wed Mar 31 10:10:42 2021 - [info] MHA::MasterRotate version 0.58. 3 Wed Mar 31 10:10:42 2021 - [info] Starting online master switch.. 4 Wed Mar 31 10:10:42 2021 - [info] 5 Wed Mar 31 10:10:42 2021 - [info] * Phase 1: Configuration Check Phase.. 6 Wed Mar 31 10:10:42 2021 - [info] 7 Wed Mar 31 10:10:42 2021 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. 8 Wed Mar 31 10:10:42 2021 - [info] Reading application default configuration from /etc/mha/app1.cnf.. 9 Wed Mar 31 10:10:42 2021 - [info] Reading server configuration from /etc/mha/app1.cnf.. 10 Wed Mar 31 10:10:43 2021 - [info] GTID failover mode = 1 11 Wed Mar 31 10:10:43 2021 - [info] Current Alive Master: 192.168.10.11(192.168.10.11:3306) 12 Wed Mar 31 10:10:43 2021 - [info] Alive Slaves: 13 Wed Mar 31 10:10:43 2021 - [info] 192.168.10.12(192.168.10.12:3306) Version=5.7.27-log (oldest major version between slaves) log-bin:enabled 14 Wed Mar 31 10:10:43 2021 - [info] GTID ON 15 Wed Mar 31 10:10:43 2021 - [info] Replicating from 192.168.10.11(192.168.10.11:3306) 16 Wed Mar 31 10:10:43 2021 - [info] Primary candidate for the new Master (candidate_master is set) 17 Wed Mar 31 10:10:43 2021 - [info] 192.168.10.13(192.168.10.13:3306) Version=5.7.27-log (oldest major version between slaves) log-bin:enabled 18 Wed Mar 31 10:10:43 2021 - [info] GTID ON 19 Wed Mar 31 10:10:43 2021 - [info] Replicating from 192.168.10.11(192.168.10.11:3306) 20 21 It is better to execute FLUSH NO_WRITE_TO_BINLOG TABLES on the master before switching. Is it ok to execute on 192.168.10.11(192.168.10.11:3306)? (Y 22 Wed Mar 31 10:10:44 2021 - [info] Executing FLUSH NO_WRITE_TO_BINLOG TABLES. This may take long time.. 23 Wed Mar 31 10:10:44 2021 - [info] ok. 24 Wed Mar 31 10:10:44 2021 - [info] Checking MHA is not monitoring or doing failover.. 25 Wed Mar 31 10:10:44 2021 - [info] Checking replication health on 192.168.10.12.. 26 Wed Mar 31 10:10:44 2021 - [info] ok. 27 Wed Mar 31 10:10:44 2021 - [info] Checking replication health on 192.168.10.13.. 28 Wed Mar 31 10:10:44 2021 - [info] ok. 29 Wed Mar 31 10:10:44 2021 - [info] 192.168.10.13 can be new master. 30 Wed Mar 31 10:10:44 2021 - [info] 31 From: 32 192.168.10.11(192.168.10.11:3306) (current master) 33 +--192.168.10.12(192.168.10.12:3306) 34 +--192.168.10.13(192.168.10.13:3306) 35 36 To: 37 192.168.10.13(192.168.10.13:3306) (new master) 38 +--192.168.10.12(192.168.10.12:3306) 39 +--192.168.10.11(192.168.10.11:3306) 40 41 Starting master switch from 192.168.10.11(192.168.10.11:3306) to 192.168.10.13(192.168.10.13:3306)? (yes/NO): yes 42 Wed Mar 31 10:10:46 2021 - [info] Checking whether 192.168.10.13(192.168.10.13:3306) is ok for the new master.. 43 Wed Mar 31 10:10:46 2021 - [info] ok. 44 Wed Mar 31 10:10:46 2021 - [info] 192.168.10.11(192.168.10.11:3306): SHOW SLAVE STATUS returned empty result. To check replication filtering rules, 45 Wed Mar 31 10:10:46 2021 - [info] 192.168.10.11(192.168.10.11:3306): Resetting slave pointing to the dummy host. 46 Wed Mar 31 10:10:46 2021 - [info] ** Phase 1: Configuration Check Phase completed. 47 Wed Mar 31 10:10:46 2021 - [info] 48 Wed Mar 31 10:10:46 2021 - [info] * Phase 2: Rejecting updates Phase.. 49 Wed Mar 31 10:10:46 2021 - [info] 50 Wed Mar 31 10:10:46 2021 - [info] Executing master ip online change script to disable write on the current master: 51 Wed Mar 31 10:10:46 2021 - [info] /mha/mha4mysql-manager-master/bin/master_ip_online_change --command=stop --orig_master_host=192.168.10.11 --origr_ip=192.168.10.13 --new_master_port=3306 --new_master_user='mhaadmin' --orig_master_ssh_user=root --new_master_ssh_user=root --orig_master_is_new 52 Wed Mar 31 10:10:46 2021 346151 Set read_only on the new master.. ok. 53 Wed Mar 31 10:10:46 2021 351134 Drpping app user on the orig master.. 54 Wed Mar 31 10:10:46 2021 351874 Waiting all running 2 threads are disconnected.. (max 1500 milliseconds) 55 {'Time' => '114','db' => undef,'Id' => '48','User' => 'replica','State' => 'Master has sent all binlog to slave; waiting for more updates','Command' 56 {'Time' => '112','db' => undef,'Id' => '49','User' => 'replica','State' => 'Master has sent all binlog to slave; waiting for more updates','Command' 57 Wed Mar 31 10:10:46 2021 854267 Waiting all running 2 threads are disconnected.. (max 1000 milliseconds) 58 {'Time' => '114','db' => undef,'Id' => '48','User' => 'replica','State' => 'Master has sent all binlog to slave; waiting for more updates','Command' 59 {'Time' => '112','db' => undef,'Id' => '49','User' => 'replica','State' => 'Master has sent all binlog to slave; waiting for more updates','Command' 60 Wed Mar 31 10:10:47 2021 358649 Waiting all running 2 threads are disconnected.. (max 500 milliseconds) 61 {'Time' => '115','db' => undef,'Id' => '48','User' => 'replica','State' => 'Master has sent all binlog to slave; waiting for more updates','Command' 62 {'Time' => '113','db' => undef,'Id' => '49','User' => 'replica','State' => 'Master has sent all binlog to slave; waiting for more updates','Command' 63 Wed Mar 31 10:10:47 2021 860488 Set read_only=1 on the orig master.. ok. 64 Wed Mar 31 10:10:47 2021 862857 Waiting all running 2 queries are disconnected.. (max 500 milliseconds) 65 {'Time' => '115','db' => undef,'Id' => '48','User' => 'replica','State' => 'Master has sent all binlog to slave; waiting for more updates','Command' 66 {'Time' => '113','db' => undef,'Id' => '49','User' => 'replica','State' => 'Master has sent all binlog to slave; waiting for more updates','Command' 67 Wed Mar 31 10:10:48 2021 364167 Killing all application threads.. 68 Wed Mar 31 10:10:48 2021 365951 done. 69 Disabling the VIP on old master: 192.168.10.11 70 Wed Mar 31 10:10:48 2021 - [info] ok. 71 Wed Mar 31 10:10:48 2021 - [info] Locking all tables on the orig master to reject updates from everybody (including root): 72 Wed Mar 31 10:10:48 2021 - [info] Executing FLUSH TABLES WITH READ LOCK.. 73 Wed Mar 31 10:10:48 2021 - [info] ok. 74 Wed Mar 31 10:10:48 2021 - [info] Orig master binlog:pos is node1-bin.000006:154. 75 Wed Mar 31 10:10:48 2021 - [info] Waiting to execute all relay logs on 192.168.10.13(192.168.10.13:3306).. 76 Wed Mar 31 10:10:48 2021 - [info] master_pos_wait(node1-bin.000006:154) completed on 192.168.10.13(192.168.10.13:3306). Executed 0 events. 77 Wed Mar 31 10:10:48 2021 - [info] done. 78 Wed Mar 31 10:10:48 2021 - [info] Getting new master's binlog name and position.. 79 Wed Mar 31 10:10:48 2021 - [info] node3-bin.000007:194 80 Wed Mar 31 10:10:48 2021 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='192.168.1 81 Wed Mar 31 10:10:48 2021 - [info] Executing master ip online change script to allow write on the new master: 82 Wed Mar 31 10:10:48 2021 - [info] /mha/mha4mysql-manager-master/bin/master_ip_online_change --command=start --orig_master_host=192.168.10.11 --orier_ip=192.168.10.13 --new_master_port=3306 --new_master_user='mhaadmin' --orig_master_ssh_user=root --new_master_ssh_user=root --orig_master_is_ne 83 Wed Mar 31 10:10:48 2021 741504 Set read_only=0 on the new master. 84 Enabling the VIP - 192.168.10.10/24 on the new master - 192.168.10.13 85 Wed Mar 31 10:10:49 2021 - [info] ok. 86 Wed Mar 31 10:10:49 2021 - [info] 87 Wed Mar 31 10:10:49 2021 - [info] * Switching slaves in parallel.. 88 Wed Mar 31 10:10:49 2021 - [info] 89 Wed Mar 31 10:10:49 2021 - [info] -- Slave switch on host 192.168.10.12(192.168.10.12:3306) started, pid: 4943 90 Wed Mar 31 10:10:49 2021 - [info] 91 Wed Mar 31 10:10:51 2021 - [info] Log messages from 192.168.10.12 ... 92 Wed Mar 31 10:10:51 2021 - [info] 93 Wed Mar 31 10:10:49 2021 - [info] Waiting to execute all relay logs on 192.168.10.12(192.168.10.12:3306).. 94 Wed Mar 31 10:10:49 2021 - [info] master_pos_wait(node1-bin.000006:154) completed on 192.168.10.12(192.168.10.12:3306). Executed 0 events. 95 Wed Mar 31 10:10:49 2021 - [info] done. 96 Wed Mar 31 10:10:49 2021 - [info] Resetting slave 192.168.10.12(192.168.10.12:3306) and starting replication from the new master 192.168.10.13(192. 97 Wed Mar 31 10:10:49 2021 - [info] Executed CHANGE MASTER. 98 Wed Mar 31 10:10:50 2021 - [info] Slave started. 99 Wed Mar 31 10:10:51 2021 - [info] End of log messages from 192.168.10.12 ... 100 Wed Mar 31 10:10:51 2021 - [info] 101 Wed Mar 31 10:10:51 2021 - [info] -- Slave switch on host 192.168.10.12(192.168.10.12:3306) succeeded. 102 Wed Mar 31 10:10:51 2021 - [info] Unlocking all tables on the orig master: 103 Wed Mar 31 10:10:51 2021 - [info] Executing UNLOCK TABLES.. 104 Wed Mar 31 10:10:51 2021 - [info] ok. 105 Wed Mar 31 10:10:51 2021 - [info] Starting orig master as a new slave.. 106 Wed Mar 31 10:10:51 2021 - [info] Resetting slave 192.168.10.11(192.168.10.11:3306) and starting replication from the new master 192.168.10.13(192. 107 Wed Mar 31 10:10:51 2021 - [info] Executed CHANGE MASTER. 108 Wed Mar 31 10:10:52 2021 - [info] Slave started. 109 Wed Mar 31 10:10:52 2021 - [info] All new slave servers switched successfully. 110 Wed Mar 31 10:10:52 2021 - [info] 111 Wed Mar 31 10:10:52 2021 - [info] * Phase 5: New master cleanup phase.. 112 Wed Mar 31 10:10:52 2021 - [info] 113 Wed Mar 31 10:10:52 2021 - [info] 192.168.10.13: Resetting slave info succeeded. 114 Wed Mar 31 10:10:52 2021 - [info] Switching master to 192.168.10.13(192.168.10.13:3306) completed successfully. 115 [root@monitor ~]#
(六)故障节点恢复
在执行自动或者手动故障转移之后,原主节点已经被踢出了主从复制集群。那么如何将原主机重新添加到集群中呢?有2种方案可以考虑:
利用新的主节点备份,对原先的master数据库进行重新还原,然后作为slave加入到集群中;
原master数据库理论上只是落后于现在的master数据库,只要新主节点binlog完整,可以将原先的master作为slave加入到集群中
这里对第二种方法进行演示。
测试环境:
主节点 :192.168.10.11
从节点1:192.168.10.12
从节点2:192.168.10.13
STEP1:开启mha manager监控
[root@monitor ~]# nohup masterha_manager --conf=/etc/mha/app1.cnf & [1] 5622 [root@monitor ~]# nohup: ignoring input and appending output to ‘nohup.out’ [root@monitor ~]# [root@monitor ~]# [root@monitor ~]# [root@monitor ~]# masterha_check_status --conf=/etc/mha/app1.cnf app1 (pid:5622) is running(0:PING_OK), master:192.168.10.11
STEP2:模拟自动故障转移,关闭主节点,使得主节点切换到node2上
# 重启节点1 服务器 [root@node1 ~]# reboot # 此时发生了主节点切换,通过查看,可以看到已经切换到了节点2上 [root@node3 ~]# mysql -uroot -p123456 Oracle is a registered trademark of Oracle Corporation and/or its mysql> show slave status \G *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 192.168.10.12 Master_User: replica
STEP3:node1节点重启之后,该服务器上的MySQL已经是独立存在的,与其它2个节点不是主从关系。
[root@node1 ~]# service mysqld start Starting MySQL. SUCCESS! [root@node1 ~]# mysql -uroot -p123456 mysql> show master status \G *************************** 1. row *************************** File: node1-bin.000008 Position: 154 Binlog_Do_DB: Binlog_Ignore_DB: Executed_Gtid_Set: 2db1f74f-8790-11eb-b668-000c29d1545c:1-94186, 30753d6b-8790-11eb-864f-000c2999ad6c:1-2, 32a16250-8790-11eb-b587-000c2925bdbb:1-2 1 row in set (0.00 sec) mysql> show slave status \G Empty set (0.00 sec)
STEP4:将node1节点转换为从节点
首先到mha manager日志中查找从节点开启语句,只要发生切换,不管是故障转移还是手动在线切换,在日志中均会生成从节点开启复制日志:
[root@monitor bin]# tail -500f /mha/mha4mysql-manager-master/app1/log/manager.log |grep "CHANGE MASTER" Wed Mar 31 13:24:26 2021 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='192.168.10.12', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='replica', MASTER_PASSWORD='xxx'; Wed Mar 31 13:24:26 2021 - [info] Executed CHANGE MASTER.
在node1执行开启复制语句:
[root@node1 ~]# mysql -uroot -p123456 mysql> CHANGE MASTER TO MASTER_HOST='192.168.10.12', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='replica', MASTER_PASSWORD='replica'; Query OK, 0 rows affected, 2 warnings (0.01 sec) mysql> start slave; Query OK, 0 rows affected (0.01 sec) mysql> show slave status \G *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 192.168.10.12 Master_User: replica Master_Port: 3306 Connect_Retry: 60 Master_Log_File: node2-bin.000002 Read_Master_Log_Pos: 154 Relay_Log_File: node1-relay-bin.000002 Relay_Log_Pos: 367 Relay_Master_Log_File: node2-bin.000002 Slave_IO_Running: Yes Slave_SQL_Running: Yes
STEP5:将node1节点转换为主节点,可选
在step4结束之后,node1已经加入到主从复制环境中,此时主从关系为:
主节点 :192.168.10.12
从节点1:192.168.10.11
从节点2:192.168.10.13
如果还要考虑将192.168.10.11转换为主节点,则还需执行在线主从切换:
[root@monitor ~]# masterha_master_switch --master_state=alive --conf=/etc/mha/app1.cnf --new_master_host=192.168.10.11 --orig_master_is_new_slave
新的关系为:
[root@monitor ~]# masterha_check_repl --conf=/etc/mha/app1.cnf Wed Mar 31 13:41:03 2021 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. Wed Mar 31 13:41:03 2021 - [info] Reading application default configuration from /etc/mha/app1.cnf.. Wed Mar 31 13:41:03 2021 - [info] Reading server configuration from /etc/mha/app1.cnf.. Wed Mar 31 13:41:03 2021 - [info] MHA::MasterMonitor version 0.58. Wed Mar 31 13:41:04 2021 - [info] GTID failover mode = 1 Wed Mar 31 13:41:04 2021 - [info] Dead Servers: Wed Mar 31 13:41:04 2021 - [info] Alive Servers: Wed Mar 31 13:41:04 2021 - [info] 192.168.10.11(192.168.10.11:3306) Wed Mar 31 13:41:04 2021 - [info] 192.168.10.12(192.168.10.12:3306) Wed Mar 31 13:41:04 2021 - [info] 192.168.10.13(192.168.10.13:3306) Wed Mar 31 13:41:04 2021 - [info] Alive Slaves: Wed Mar 31 13:41:04 2021 - [info] 192.168.10.12(192.168.10.12:3306) Version=5.7.27-log (oldest major version between slaves) log-bin:enabled Wed Mar 31 13:41:04 2021 - [info] GTID ON Wed Mar 31 13:41:04 2021 - [info] Replicating from 192.168.10.11(192.168.10.11:3306) Wed Mar 31 13:41:04 2021 - [info] Primary candidate for the new Master (candidate_master is set) Wed Mar 31 13:41:04 2021 - [info] 192.168.10.13(192.168.10.13:3306) Version=5.7.27-log (oldest major version between slaves) log-bin:enabled Wed Mar 31 13:41:04 2021 - [info] GTID ON Wed Mar 31 13:41:04 2021 - [info] Replicating from 192.168.10.11(192.168.10.11:3306) Wed Mar 31 13:41:04 2021 - [info] Current Alive Master: 192.168.10.11(192.168.10.11:3306) Wed Mar 31 13:41:04 2021 - [info] Checking slave configurations.. Wed Mar 31 13:41:04 2021 - [info] Checking replication filtering settings.. Wed Mar 31 13:41:04 2021 - [info] binlog_do_db= , binlog_ignore_db= Wed Mar 31 13:41:04 2021 - [info] Replication filtering check ok. Wed Mar 31 13:41:04 2021 - [info] GTID (with auto-pos) is supported. Skipping all SSH and Node package checking. Wed Mar 31 13:41:04 2021 - [info] Checking SSH publickey authentication settings on the current master.. Wed Mar 31 13:41:04 2021 - [info] HealthCheck: SSH to 192.168.10.11 is reachable. Wed Mar 31 13:41:04 2021 - [info] 192.168.10.11(192.168.10.11:3306) (current master) +--192.168.10.12(192.168.10.12:3306) +--192.168.10.13(192.168.10.13:3306) Wed Mar 31 13:41:04 2021 - [info] Checking replication health on 192.168.10.12.. Wed Mar 31 13:41:04 2021 - [info] ok. Wed Mar 31 13:41:04 2021 - [info] Checking replication health on 192.168.10.13.. Wed Mar 31 13:41:04 2021 - [info] ok. Wed Mar 31 13:41:04 2021 - [info] Checking master_ip_failover_script status: Wed Mar 31 13:41:04 2021 - [info] /mha/mha4mysql-manager-master/bin/master_ip_failover --command=status --ssh_user=root --orig_master_host=192.168.10.11 --orig_master_ip=192.168.10.11 --orig_master_port=3306 IN SCRIPT TEST====/sbin/ifconfig ens34:1 down==/sbin/ifconfig ens34:1 192.168.10.10/24=== Checking the Status of the script.. OK Wed Mar 31 13:41:04 2021 - [info] OK. Wed Mar 31 13:41:04 2021 - [warning] shutdown_script is not defined. Wed Mar 31 13:41:04 2021 - [info] Got exit code 0 (Not master dead). MySQL Replication Health is OK.
(七)其它
(7.1)定期清理日志relaylog
在搭建MHA集群时,要求将所有MySQL节点的自动清除relay log功能关闭,因为在故障切换时,进行数据恢复的时候,可能会需要从节点的relaylog日志。
mysql> show variables like 'relay_log_purge'; +-----------------+-------+ | Variable_name | Value | +-----------------+-------+ | relay_log_purge | OFF | +-----------------+-------+
那么从节点的relaylog如何删除呢?mha node提供了一个purge_relay_logs脚本,专用于清理relaylog。
[root@node3 bin]# which purge_relay_logs /usr/local/bin/purge_relay_logs
工作原理如下:
1.purge_relay_logs的功能
2.为relay日志创建硬链接(最小化批量删除大文件导致的性能问题)
3.SET GLOBAL relay_log_purge=1; FLUSH LOGS; SET GLOBAL relay_log_purge=0;
4.删除relay log(rm –f /path/to/archive_dir/*)
使用方法如下:
[root@node3 bin]# purge_relay_logs --help Usage: purge_relay_logs --user=root --password=rootpass --host=127.0.0.1 See online reference (http://code.google.com/p/mysql-master-ha/wiki/Requirements#purge_relay_ logs_script) for details.
核心参数描述:
--user mysql :用户名,缺省为root
--password :mysql 密码
--port :端口号
--host :主机名,缺省为127.0.0.1
--workdir :指定创建relay log的硬链接的位置,默认是/var/tmp,成功执行脚本后,硬链接的中继日志文件被删除,由于系统不同分区创建硬链接文件会失败,故需要执行硬链接具体位置,建议指定为relay log相同的分区
--disable_relay_log_purge :默认情况下,参数relay_log_purge=1,脚本不做任何处理,自动退出,设定该参数,脚本会将relay_log_purge设置为0,当清理relay log之后,最后将参数设置为OFF(0)
在从节点上手动执行relaylog清理:
[root@node2 data]# /usr/local/bin/purge_relay_logs --user=root --password=123456 --disable_relay_log_purge 2021-03-31 14:16:29: purge_relay_logs script started. Found relay_log.info: /mysql/data/relay-log.info Opening /mysql/data/node2-relay-bin.000001 .. Opening /mysql/data/node2-relay-bin.000002 .. Executing SET GLOBAL relay_log_purge=1; FLUSH LOGS; sleeping a few seconds so that SQL thread can delete older relay log files (if it keeps up); SET GLOBAL relay_log_purge=0; .. ok. 2021-03-31 14:16:32: All relay log purging operations succeeded.
在生产环境中需要设置crontab定时执行
$ crontab -l # purge relay logs at 5am 0 5 * * * /usr/local/bin/purge_relay_logs --user=root --password=123456 --disable_relay_log_purge >> /tmp/mha_purge_relay_logs.log 2>&1
(7.2)选择哪个主机作为主节点
如果主机满足上述条件,则根据以下规则确定新的主服务器:
*如果在某些主机上candicate_master = 1,则将优先考虑它们
*如果其中一些是最新的(接收到最新二进制日志事件的从站),则该主机将被选作新的主站
*如果最新是多个主机,则主主机将由“配置文件中按节名称的顺序”确定。如果您具有server1,server2和server3部分,并且server1和server3均为候选人主控者和最新者,则将选择server1作为新的主控者。
*如果没有任何服务器设置candicate_master = 1参数,
*则最新的从属服务器将成为新的主服务器。如果最新是多个从站,则将应用“按节命名”规则。
*如果最新的从站都不是新的主站,则非最新的从站之一将是新的主站。按节命名规则也将在此处应用。
【完】


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?