MySQL表连接及其优化
导读:
在做MySQL数据库的优化工作时,如果只涉及到单表查询,那么95%的慢SQL都只需从索引上入手优化即可,通过添加索引来消除全表扫描或者排序操作,大概率能实现SQL语句执行速度质的飞跃。对于单表的优化操作,相信大部分DBA甚至开发人员都可以完成。
然而,在实际生产中,除了单表操作,更多的是多个表联合起来查询,这样的查询通常是慢SQL的重灾区,查询速度慢,使用服务器资源较多,高CPU,高I/O。本文通过对表连接的表现形式以及内部理论进行探究,以及思考如何优化表连接操作。
本文基于MySQL 5.7版本进行探究,由于MySQL 8中引入了新的连接方式hash join,本文可能不适用MySQL8版本
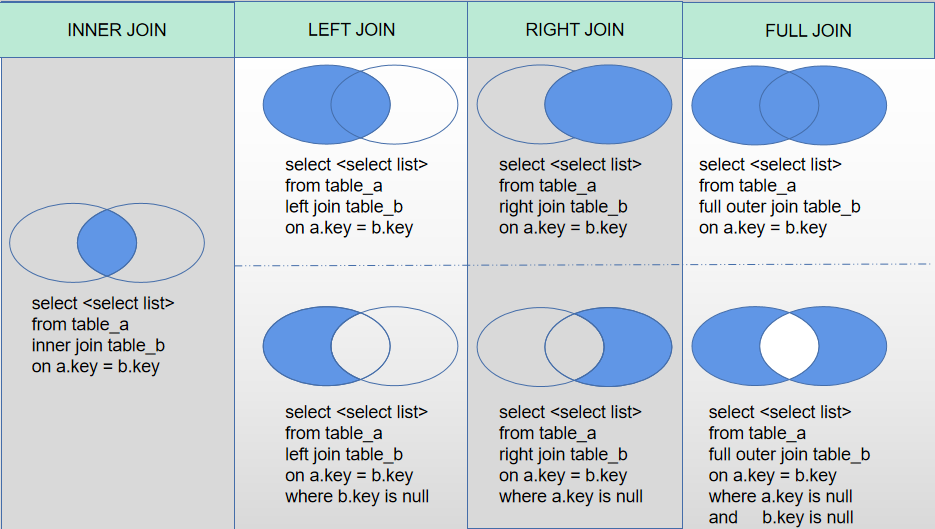
(一)MySQL的七种连接方式介绍
在MySQL中,常见的表连接方式有4类,共计7种方式:
- INNER JOIN:inner join是根据表连接条件,求取2个表的数据交集;
- LEFT JOIN :left join是根据表连接条件,求取2个表的数据交集再加上左表剩下的数据;此外,还可以使用where过滤条件求左表独有的数据。
- RIGHT JOIN:right join是根据表连接条件,求取2个表的数据交集再加上右表剩下的数据;此外,还可以使用where过滤条件求右表独有的数据。
- FULL JOIN:full join是左连接与右连接的并集,MySQL并未提供full join语法,如果要实现full join,需要left join与right join进行求并集,此外还可以使用where查看2个表各自独有的数据。
通过图形来表现,各种连接形式的求取集合部分如下,蓝色部分代表满足join条件的数据:
接下来,我们通过例子来理解各种JOIN的含义。
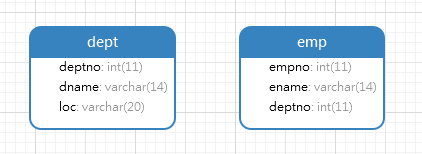
首先创建测试数据:
-- 1.创建部门表 -- 部门表记录部门信息,公司共有4个部门:财务(FINANCE)、人力(HR)、销售(SALES)、研发(RD)。
-- 不一定每个部门都有人,例如,公司虽然有研发部,但是没有在编人员 create table dept (deptno int,dname varchar(14),loc varchar(20)); insert into dept values(10,'FINANCE','BEIJING'); insert into dept values(20,'HR','BEIJING'); insert into dept values(30,'SALES','SHANGHAI'); insert into dept values(40,'RD','CHENGDU'); -- 2.创建员工表
-- 员工表记录了员工工号、姓名、部门编号。
-- 不一定每个员工都有部门。例如,外包人员dd就没有部门
create table emp (empno int,ename varchar(14),deptno int); insert into emp values(1,'aa',10); insert into emp values(2,'bb',20); insert into emp values(3,'cc',30); insert into emp values(4,'dd',null); insert into emp values(5,'ee',30); insert into emp values(6,'ff',20);
ER图如下:
(1.1)INNER JOIN
业务场景:查看公司正式员工的详细信息,包括工号、姓名、部门名称。
需求分析:正式员工都有对应部门,使用INNER JOIN,通过部门编号关联部门与员工求交集。
SQL语句:
mysql> select e.empno,e.ename,d.dname from emp e inner join dept d on e.deptno = d.deptno; +-------+-------+---------+ | empno | ename | dname | +-------+-------+---------+ | 1 | aa | FINANCE | | 2 | bb | HR | | 3 | cc | SALES | | 5 | ee | SALES | | 6 | ff | HR | +-------+-------+---------+
INNER JOIN就是求取2个表的共有数据(交集),我们可以这样来理解表INNER JOIN过程:
- 从驱动表按顺序数据,然后到被驱动表中逐行进行比较
- 如果条件满足,则取出该行数据(注意取出的是2个表连接之后的数据),如果条件不满足,则丢弃数据,然后继续向下比较,直到遍历完被驱动表的所有行
- 一致循环上面2步,知道步骤1的驱动表也遍历结束。
对于上面SQL,其执行过程我们可以使用伪代码来描述:
// 特别注意:2个for循环,哪个表用来做外部循环,哪个表用来做内部循环,是由执行计划决定的,可用explain来查看,通常使用结果集较小的表来做驱动表,
// 本例子中,SQL中顺序为emp,dept,但在执行计划中却是dept,emp。因此内外表顺序需要看MySQL的执行计划
for (i=1;i<=d.counts;i++) { for (j=1;j<=e.counts;j++>) { if (d[i].key = e[j].key) { return d[i].dname,e[j].empno,e[j].ename; } } }
(1.2)LEFT JOIN
业务场景:查看每一个部门的详细信息,包括工号、姓名、部门名称。
需求分析:既然包含每一个部门,那么可以使用部门表进行LEFT JOIN,通过部门编号关联部门与员工求交集。
SQL语句:
mysql> select d.dname,e.empno,e.ename from dept d left join emp e on e.deptno = d.deptno; +---------+-------+-------+ | dname | empno | ename | +---------+-------+-------+ | FINANCE | 1 | aa | | HR | 2 | bb | | SALES | 3 | cc | | SALES | 5 | ee | | HR | 6 | ff | | RD | NULL | NULL | +---------+-------+-------+
LEFT JOIN就是求取2个表的共有数据(交集)再加上左表剩下的数据,也就是左表的数据全部都要,左表的数据只要满足关联条件的。
我们可以这样来理解表LEFT JOIN过程:
- 从左表按顺序数据,然后到右表中逐行进行比较
- 如果条件满足,则取出该行数据(注意取出的是2个表连接之后的数据),如果条件不满足,则丢弃数据,然后继续向下比较,直到遍历完被驱动表的所有行,如果遍历完右表所有的行都没有与左表匹配的数据,则返回左表的行,右表的记录用NULL填充。
- 一致循环上面2步,知道步骤1的驱动表也遍历结束。
对于上面SQL,其执行过程我们可以使用伪代码来描述:
/*
关于外连接查询算法描述(https://dev.mysql.com/doc/refman/5.7/en/nested-join-optimization.html):
通常,对于外部联接操作中第一个内部表的任何嵌套循环,都会引入一个标志,该标志在循环之前关闭并在循环之后检查。当针对外部表中的当前行找到表示内部操作数的表中的匹配项时,将打开该标志。如果在循环周期结束时该标志仍处于关闭状态,则未找到外部表的当前行的匹配项。在这种情况下,该行由NULL内部表的列的值补充 。结果行将传递到输出的最终检查项或下一个嵌套循环,但前提是该行满足所有嵌入式外部联接的联接条件。
*/
for (i=1;i<=d.counts;i++) { var is_success=false; // 确认d.[i]是否匹配到至少1行数据,默认未匹配到 for (j=1;j<=e.counts;j++>) { if (d[i].key = e[j].key) { return d[i].dname,e[j].empno,e[j].ename; is_success = true; } } if (is_success=false) // 如果左边的表没有匹配到数据,也会将左边表返回,右边表用null代替 { return d[i].key,null,null; } }
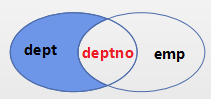
LEFT JOIN的补充:使用LEFT JOIN来获取左表独有的数据
业务场景:查看哪些部门没有员工
需求分析:要查看没有部门的员工,只需要先查出所有的部门与员工关系数据,然后过滤掉有员工的数据。
SQL语句:
mysql> select d.dname,e.empno,e.ename from dept d left join emp e on d.deptno = e.deptno where e.deptno is null; +-------+-------+-------+ | dname | empno | ename | +-------+-------+-------+ | RD | NULL | NULL | +-------+-------+-------+
使用LEFT JOIN获取2个表的共有数据(交集)再加上左表剩下的数据,然后又把交集去除。
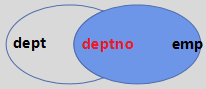
(1.3)RIGHT JOIN
业务场景:查看每一个员工的详细信息,包括工号、姓名、部门名称。
需求分析:既然包含每一个员工,那么可以使用部门表进行LEFT JOIN,通过部门编号关联部门与员工求交集。
SQL语句:
mysql> select d.dname,e.empno,e.ename from dept d right join emp e on e.deptno = d.deptno; +---------+-------+-------+ | dname | empno | ename | +---------+-------+-------+ | FINANCE | 1 | aa | | HR | 2 | bb | | HR | 6 | ff | | SALES | 3 | cc | | SALES | 5 | ee | | NULL | 4 | dd | +---------+-------+-------+
需要注意的是,右连接和左连接是可以相互转换的,即右连接的语句,通过调换表位置并修改连接关键字为左连接,即可实现等价转换。上面的SQL的等价左连接为:
mysql> select d.dname,e.empno,e.ename from emp e left join dept d on e.deptno = d.deptno; +---------+-------+-------+ | dname | empno | ename | +---------+-------+-------+ | FINANCE | 1 | aa | | HR | 2 | bb | | HR | 6 | ff | | SALES | 3 | cc | | SALES | 5 | ee | | NULL | 4 | dd | +---------+-------+-------+
实际上,MySQL在解析SQL阶段,会自动将右外连接转换等效的左外连接(文档:https://dev.mysql.com/doc/refman/5.7/en/outer-join-simplification.html),所以我们也无需深入的去了解右连接。
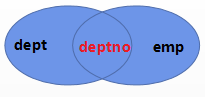
(1.4)FULL JOIN
业务场景:查看所有部门及其所有员工的详细信息,包括工号、姓名、部门名称。
需求分析:既然包含每一个部门及所有员工,那么可以使用全连接获取数据。然而,MySQL并没有关键字去获取全连接的数据,我们可以通过合并左连接
SQL语句:
mysql> select d.dname,e.empno,e.ename from dept d left join emp e on e.deptno = d.deptno union select d.dname,e.empno,e.ename from dept d right join emp e on e.deptno = d.deptno; +---------+-------+-------+ | dname | empno | ename | +---------+-------+-------+ | FINANCE | 1 | aa | | HR | 2 | bb | | SALES | 3 | cc | | SALES | 5 | ee | | HR | 6 | ff | | RD | NULL | NULL | | NULL | 4 | dd | +---------+-------+-------+
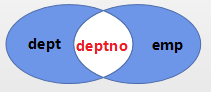
FULL JOIN的补充:
如果要查找没有员工的部门或者没有部门的员工,即求取两个表各自独有的数据
SQL语句:
mysql> select d.dname,e.empno,e.ename from dept d left join emp e on e.deptno = d.deptno where e.deptno is null union select d.dname,e.empno,e.ename from dept d right join emp e on e.deptno = d.deptno where d.deptno is null; +-------+-------+-------+ | dname | empno | ename | +-------+-------+-------+ | RD | NULL | NULL | | NULL | 4 | dd | +-------+-------+-------+
(二)MySQL Join算法
在MySQL 5.7中,MySQL仅支持Nested-Loop Join算法及其改进型Block-Nested-Loop Join算法,在8.0版本中,又新增了Hash Join算法,这里只讨论5.7版本的表连接方式。
(2.1)Nested-Loop Join算法
嵌套循环连接算法(NLJ)从第一个循环的表中读取1行数据,并将该行传递到下一个表进行连接运算,如果符合条件,则继续与下一个表的行数据进行连接,知道连接完所有的表,然后重复上面的过程。简单来讲Nested-Loop Join就是编程中的多层for循环。假设存在3个表进行连接,连接方式如下:
table join type
------ -------------
t1 range
t2 ref
t3 ALL
如果使用NLJ算法进行连接,伪代码如下:
for each row in t1 matching range { for each row in t2 matching reference key { for each row in t3 { if row satisfies join conditions, send to client } } }
(2.2)Block Nested-Loop Join算法
块嵌套循环(BLN)连接算法使用外部表的行缓冲来减少对内部表的读次数。例如,将外部表的10行数据读入缓冲区并将缓冲区传递到下一个内部循环,则可以将内部循环中的每一行与缓冲区的10行数据进行比较,此时,内部表读取的次数将减少为1/10。
如果使用BNL算法,上述连接的伪代码可以写为:
for each row in t1 matching range { for each row in t2 matching reference key { store used columns from t1, t2 in join buffer if buffer is full { for each row in t3 { for each t1, t2 combination in join buffer { if row satisfies join conditions, send to client } } empty join buffer } } } if buffer is not empty { for each row in t3 { for each t1, t2 combination in join buffer { if row satisfies join conditions, send to client } } }
MySQL Join Buffer有如下特点:
- join buffer可以被使用在表连接类型为ALL,index,range。换句话说,只有索引不可能被使用,或者索引全扫描,索引范围扫描等代价较大的查询才会使用Block Nested-Loop Join算法;
- 仅仅用于连接的列数据才会被存在连接缓存中,而不是整行数据
- join_buffer_size系统变量用来决定每一个join buffer的大小
- MySQL为每一个可以被缓存的join语句分配一个join buffer,以便每一个查询都可以使用join buffer。
- 在执行连接之前分配连接缓冲区,并在查询完成后释放连接缓冲区。
(三)表连接顺序
在关系型数据库中,对于多表连接,位于嵌套循环外部的表我们称为驱动表,位于嵌套循环内部的表我们称为被驱动表,驱动表与被驱动表的顺序对于Join性能影响非常大,接下来我们探索一下MySQL中表连接的顺序。因为RIGHT JOIN和FULL JOIN在MySQL中最终都会转换为LEFT JOIN,所以我们只需讨论INNER JOIN和LEFT JOIN即可。
这里为了确保测试准确,我们使用MySQL提供的测试数据库employees,下载地址为:https://github.com/datacharmer/test_db。其ER图如下:
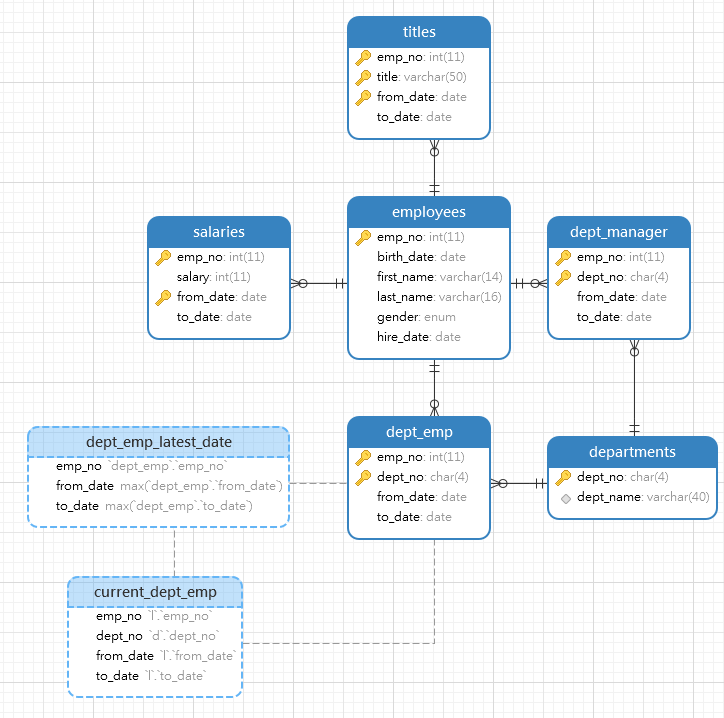
(3.1)INNER JOIN
对应INNER JOIN,MySQL永远选择结果集小的表作为驱动表。
例子1:查看员工部门对应信息
-- 将employees,dept_manager , departments 3个表进行内连接即可 select e.emp_no,e.first_name,e.last_name,d.dept_name from employees e inner join dept_manager dm on e.emp_no = dm.emp_no inner join departments d on dm.dept_no = d.dept_no;
我们来看一下3个表的大小,需要注意的是,这里仅仅是MySQL粗略统计行数,在这个例子中,实际行数与之有一定的差距:
+--------------+------------+ | table_name | table_rows | +--------------+------------+ | departments | 9 | | dept_manager | 24 | | employees | 299468 | +--------------+------------+
最终的执行计划为:
+----+-------------+-------+------------+--------+-----------------+-----------+---------+---------------------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+--------+-----------------+-----------+---------+---------------------+------+----------+-------------+ | 1 | SIMPLE | d | NULL | index | PRIMARY | dept_name | 42 | NULL | 9 | 100.00 | Using index | | 1 | SIMPLE | dm | NULL | ref | PRIMARY,dept_no | dept_no | 4 | employees.d.dept_no | 2 | 100.00 | Using index | | 1 | SIMPLE | e | NULL | eq_ref | PRIMARY | PRIMARY | 4 | employees.dm.emp_no | 1 | 100.00 | NULL | +----+-------------+-------+------------+--------+-----------------+-----------+---------+---------------------+------+----------+-------------+
可以看到,在INNER JOIN中,MySQL并不是按照语句中表的出现顺序来按顺序执行的,而是首先评估每个表结果集的大小,选择小的作为驱动表,大的作为被驱动表,不管我们如何调整SQL中的表顺序,MySQL优化器选择表的顺序与上面相同。
这里需要特别说明的是:通常我们所说的"小表驱动大表"是非常不严谨的,在INNER JOIN中,MySQL永远选择结果集小的表作为驱动表,而不是小表。这有什么区别呢?结果集是指表进行了数据过滤后形成的临时表,其数据量小于或等于原表。下面提及的"小表和大表"都是指结果集大小。
例子2:查看工号为110567的员工部门对应信息
select e.emp_no,e.first_name,e.last_name,d.dept_name from employees e inner join dept_manager dm on e.emp_no = dm.emp_no and e.emp_no = 110567 inner join departments d on dm.dept_no = d.dept_no;
最终的执行计划为:
+----+-------------+-------+------------+--------+-----------------+---------+---------+----------------------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+--------+-----------------+---------+---------+----------------------+------+----------+-------------+ | 1 | SIMPLE | e | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL | | 1 | SIMPLE | dm | NULL | ref | PRIMARY,dept_no | PRIMARY | 4 | const | 1 | 100.00 | Using index | | 1 | SIMPLE | d | NULL | eq_ref | PRIMARY | PRIMARY | 4 | employees.dm.dept_no | 1 | 100.00 | NULL | +----+-------------+-------+------------+--------+-----------------+---------+---------+----------------------+------+----------+-------------+
可以看到,这里驱动表是employees,这个表是数据量最大的表,但是为什么选择它作为驱动表呢?因为他的结果集最小,在执行查询时,MySQL会首先选择employees表中emp_no=110567的数据,而这样的数据只有1条,其结果集也就最小,所以优化器选择了employees作为驱动表。
(3.2)LEFT JOIN
对于LEFT JOIN,执行顺序永远是从左往右,我们可以通过例子来看一下。
例子2:LEFT JOIN表顺序的选择测试
-- 表顺序:e --> dm --> d mysql> explain select e.emp_no,e.first_name,e.last_name,d.dept_name from employees e left join dept_manager dm on e.emp_no = dm.emp_no left join departments d on dm.dept_no = d.dept_no; +----+-------------+-------+------------+--------+---------------+---------+---------+----------------------+--------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+--------+---------------+---------+---------+----------------------+--------+----------+-------------+ | 1 | SIMPLE | e | NULL | ALL | NULL | NULL | NULL | NULL | 299468 | 100.00 | NULL | | 1 | SIMPLE | dm | NULL | ref | PRIMARY | PRIMARY | 4 | employees.e.emp_no | 1 | 100.00 | Using index | | 1 | SIMPLE | d | NULL | eq_ref | PRIMARY | PRIMARY | 4 | employees.dm.dept_no | 1 | 100.00 | NULL | +----+-------------+-------+------------+--------+---------------+---------+---------+----------------------+--------+----------+-------------+ -- 表顺序:dm --> e --> d mysql> explain select e.emp_no,e.first_name,e.last_name,d.dept_name from dept_manager dm left join employees e on e.emp_no = dm.emp_no left join departments d on dm.dept_no = d.dept_no; +----+-------------+-------+------------+--------+---------------+---------+---------+----------------------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+--------+---------------+---------+---------+----------------------+------+----------+-------------+ | 1 | SIMPLE | dm | NULL | index | NULL | dept_no | 4 | NULL | 24 | 100.00 | Using index | | 1 | SIMPLE | e | NULL | eq_ref | PRIMARY | PRIMARY | 4 | employees.dm.emp_no | 1 | 100.00 | NULL | | 1 | SIMPLE | d | NULL | eq_ref | PRIMARY | PRIMARY | 4 | employees.dm.dept_no | 1 | 100.00 | NULL | +----+-------------+-------+------------+--------+---------------+---------+---------+----------------------+------+----------+-------------+ -- 表顺序:e --> dm --> d mysql> explain select e.emp_no,e.first_name,e.last_name,d.dept_name from employees e left join dept_manager dm on e.emp_no = dm.emp_no left join departments d on dm.dept_no = d.dept_no; +----+-------------+-------+------------+--------+---------------+---------+---------+----------------------+--------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+--------+---------------+---------+---------+----------------------+--------+----------+-------------+ | 1 | SIMPLE | e | NULL | ALL | NULL | NULL | NULL | NULL | 299468 | 100.00 | NULL | | 1 | SIMPLE | dm | NULL | ref | PRIMARY | PRIMARY | 4 | employees.e.emp_no | 1 | 100.00 | Using index | | 1 | SIMPLE | d | NULL | eq_ref | PRIMARY | PRIMARY | 4 | employees.dm.dept_no | 1 | 100.00 | NULL | +----+-------------+-------+------------+--------+---------------+---------+---------+----------------------+--------+----------+-------------+
如果右表存在谓词过滤条件,MySQL会将left join转换为inner join,详见本文:(5.3)left join优化
(四)ON和WHERE的思考
在表连接中,我们可以在2个地方写过滤条件,一个是在ON后面,另一个就是WHERE后面了。那么,这两个地方写谓词过滤条件有什么区别呢?我们还是通过INNER JOIN和LEFT JOIN分别看一下。
(4.1)INNER JOIN
使用INNER JOIN,不管谓词条件写在ON部分还是WHERE部分,其结果都是相同的。
-- 将过滤条件写在ON部分 mysql> select e.empno,e.ename,d.dname from emp e inner join dept d on e.deptno = d.deptno and d.dname = 'HR'; +-------+-------+-------+ | empno | ename | dname | +-------+-------+-------+ | 2 | bb | HR | | 6 | ff | HR | +-------+-------+-------+ -- 将过滤条件写在WHERE部分 mysql> select e.empno,e.ename,d.dname from emp e inner join dept d on e.deptno = d.deptno where d.dname = 'HR'; +-------+-------+-------+ | empno | ename | dname | +-------+-------+-------+ | 2 | bb | HR | | 6 | ff | HR | +-------+-------+-------+ -- 使用非标准写法,将表连接条件和过滤条件写在WHERE部分 mysql> select e.empno,e.ename,d.dname from emp e inner join dept d where e.deptno = d.deptno and d.dname = 'HR'; +-------+-------+-------+ | empno | ename | dname | +-------+-------+-------+ | 2 | bb | HR | | 6 | ff | HR | +-------+-------+-------+
实际上,通过trace报告可以看到,在inner join中,不管谓词条件写在ON部分还是WHERE部分,MySQL都会将SQL语句的谓词条件等价改写到where后面。
(4.2)LEFT JOIN
我们继续来看LEFT JOIN中ON与WHERE的区别。
使用ON作为谓词过滤条件:
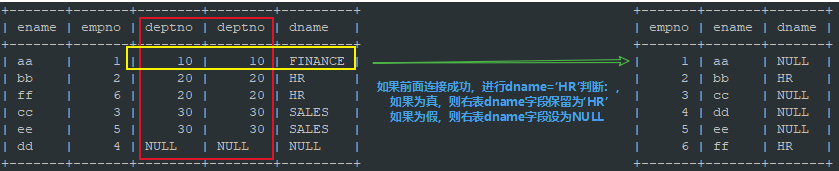
mysql> select e.empno,e.ename,d.dname from emp e left join dept d on e.deptno = d.deptno and d.dname = 'HR'; +-------+-------+-------+ | empno | ename | dname | +-------+-------+-------+ | 1 | aa | NULL | | 2 | bb | HR | | 3 | cc | NULL | | 4 | dd | NULL | | 5 | ee | NULL | | 6 | ff | HR | +-------+-------+-------+
我们可以把使用ON的情况用下图来描述,先使用ON条件进行关联,并在关联的时候进行数据过滤:
再看看使用where的结果:
mysql> select e.empno,e.ename,d.dname from emp e left join dept d on e.deptno = d.deptno where d.dname = 'HR'; +-------+-------+-------+ | empno | ename | dname | +-------+-------+-------+ | 2 | bb | HR | | 6 | ff | HR | +-------+-------+-------+
我们可以把使用where的情况用下图来描述,先使用ON条件进行关联,然后对关联的结果进行数据过滤:
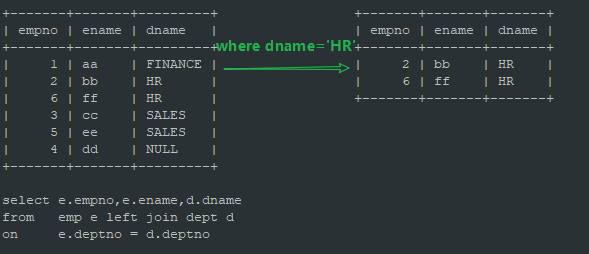
可以看到,在LEFT JOIN中,过滤条件放在ON和WHERE之后结果是不同的:
- 如果过滤条件在ON后面,那么将使用左表与右表每行数据进行连接,然后根据过滤条件判断,如果满足判断条件,则左表与右表数据进行连接,如果不满足判断条件,则返回左表数据,右表数据用NULL值代替;
- 如果过滤条件在WHERE后面,那么将使用左表与右表每行数据进行连接,然后将连接的结果集进行条件判断,满足条件的行信息保留。
(五)JOIN优化
JOIN语句相对而言比较复杂,我们根据SQL语句的结构考虑优化方法,JOIN相关的主要SQL结构如下:
- inner join
- inner join + 排序(group by 或者 order by)
- left join
(5.1)inner join优化
常规inner join的SQL语法如下:
SELECT <select_list> FROM <left_table> inner join <right_table> ON <join_condition> WHERE <where_condition>
优化方法:
1.对于inner join,通常是采用小表驱动大表的方式,即小标作为驱动表,大表作为被驱动表(相当于小表位于for循环的外层,大表位于for循环的内层)。这个过程MySQL数据局优化器以帮助我们完成,通常无需手动处理(特殊情况,表的统计信息不准确)。注意,这里的“小表”指的是结果集小的表。
2.对于inner join,需要对被驱动表的连接条件创建索引
3.对于inner join,考虑对连接条件和过滤条件(ON、WHERE)创建复合索引
例子1:对于inner join,需要对被驱动表的连接条件创建索引
-- ---------- 构造测试表 -------------------------- -- 创建新表employees_new mysql> create table employees_new like employees; Query OK, 0 rows affected (0.01 sec) mysql> insert into empployees_new select * from employees; Query OK, 300024 rows affected (2.69 sec) Records: 300024 Duplicates: 0 Warnings: 0 -- 创建新表salaries_new mysql> create table salaries_new like salaries; Query OK, 0 rows affected (0.01 sec) mysql> insert into salaries_new select * from salaries; Query OK, 2844047 rows affected (13.00 sec) Records: 2844047 Duplicates: 0 Warnings: 0 -- 删除主键 mysql> alter table employees_new drop primary key; Query OK, 300024 rows affected (1.84 sec) Records: 300024 Duplicates: 0 Warnings: 0 mysql> alter table salaries_new drop primary key; Query OK, 2844047 rows affected (9.58 sec) Records: 2844047 Duplicates: 0 Warnings: 0 -- 表大小 mysql> select table_name,table_rows from information_schema.tables a where a.table_schema = 'employees' and a.table_name in ('employees_new','salaries_new'); +---------------+------------+ | table_name | table_rows | +---------------+------------+ | employees_new | 299389 | | salaries_new | 2837194 | +---------------+------------+
此时测试表ER关系如下:
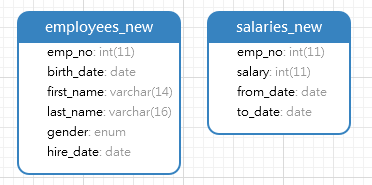
进行表连接查询,语句如下:
select e.emp_no,e.first_name,e.last_name,s.salary,s.from_date,s.to_date from employees_new e inner join salaries_new s on e.emp_no = s.emp_no ;
结果为:
-- 1. 被驱动表没有索引,执行时间:大于800s,(800s未执行完) -- 执行计划: +----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+----------------------------------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+----------------------------------------------------+ | 1 | SIMPLE | e | NULL | ALL | NULL | NULL | NULL | NULL | 299389 | 100.00 | NULL | | 1 | SIMPLE | s | NULL | ALL | NULL | NULL | NULL | NULL | 2837194 | 10.00 | Using where; Using join buffer (Block Nested Loop) | +----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+----------------------------------------------------+ -- 2. 在被驱动表连接条件上创建索引,执行时间: 37s -- 创建索引语句 create index idx_empno on salaries_new(emp_no); -- 执行计划: +----+-------------+-------+------------+------+---------------+-----------+---------+--------------------+--------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+-----------+---------+--------------------+--------+----------+-------+ | 1 | SIMPLE | e | NULL | ALL | NULL | NULL | NULL | NULL | 299389 | 100.00 | NULL | | 1 | SIMPLE | s | NULL | ref | idx_empno | idx_empno | 4 | employees.e.emp_no | 9 | 100.00 | NULL | +----+-------------+-------+------------+------+---------------+-----------+---------+--------------------+--------+----------+-------+ -- 3. 更进一步,在驱动表连接条件上也创建索引,执行时间: 40s -- 创建索引语句 create index idx_employees_new_empno on employees_new(emp_no); -- 执行计划: +----+-------------+-------+------------+------+-------------------------+-----------+---------+--------------------+--------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+-------------------------+-----------+---------+--------------------+--------+----------+-------+ | 1 | SIMPLE | e | NULL | ALL | idx_employees_new_empno | NULL | NULL | NULL | 299389 | 100.00 | NULL | | 1 | SIMPLE | s | NULL | ref | idx_empno | idx_empno | 4 | employees.e.emp_no | 9 | 100.00 | NULL | +----+-------------+-------+------------+------+-------------------------+-----------+---------+--------------------+--------+----------+-------+
通过以上测试可见,在被驱动表的连接条件上创建索引是非常有必要的,而在驱动表连接条件上创建索引则不会显著提高速度。
例子2:对于inner join,考虑对连接条件和过滤条件(ON、WHERE)创建复合索引
进行表连接查询,语句如下(以下2个SQL在MySQL优化器中解析为相同SQL):
select e.emp_no,e.first_name,e.last_name,s.salary,s.from_date,s.to_date from employees_new e inner join salaries_new s on e.emp_no = s.emp_no and e.first_name = 'Georgi' -- 或者 select e.emp_no,e.first_name,e.last_name,s.salary,s.from_date,s.to_date from employees_new e inner join salaries_new s on e.emp_no = s.emp_no where e.first_name = 'Georgi'
结果为:
-- 1. 未在连接条件和过滤条件上创建复合索引,执行时间: 0.162s -- 执行计划: +----+-------------+-------+------------+------+-------------------------+-----------+---------+--------------------+--------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+-------------------------+-----------+---------+--------------------+--------+----------+-------------+ | 1 | SIMPLE | e | NULL | ALL | idx_employees_new_empno | NULL | NULL | NULL | 299389 | 10.00 | Using where | | 1 | SIMPLE | s | NULL | ref | idx_empno | idx_empno | 4 | employees.e.emp_no | 9 | 100.00 | NULL | +----+-------------+-------+------------+------+-------------------------+-----------+---------+--------------------+--------+----------+-------------+ -- 2.在连接条件和过滤条件上创建复合索引,执行时间: 0.058s -- 创建索引语句 create index idx_employees_first_name_emp_no on employees_new(first_name,emp_no); create index idx_employees_emp_no_first_name on employees_new(emp_no,first_name); -- 执行计划: +----+-------------+-------+------------+------+-----------------------------------------------------------------------------------------+---------------------------------+---------+--------------------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+-----------------------------------------------------------------------------------------+---------------------------------+---------+--------------------+------+----------+-------+ | 1 | SIMPLE | e | NULL | ref | idx_employees_new_empno,idx_employees_first_name_emp_no,idx_employees_emp_no_first_name | idx_employees_first_name_emp_no | 16 | const | 253 | 100.00 | NULL | | 1 | SIMPLE | s | NULL | ref | idx_empno | idx_empno | 4 | employees.e.emp_no | 9 | 100.00 | NULL | +----+-------------+-------+------------+------+-----------------------------------------------------------------------------------------+---------------------------------+---------+--------------------+------+----------+-------+
通过以上测试可见,表的连接条件上和过滤条件上创建复合索引可以提高查询速度,从本例子看,速度没有较大提高,因为对employees_new表全表扫描速度很快,但是在非常大的表中,复合索引能够有效提高速度。
(5.2)inner join + 排序(group by 或者 order by)优化
常规inner join+排序的SQL语法如下:
SELECT <select_list> FROM <left_table> inner join <right_table> ON <join_condition> WHERE <where_condition>
GROUP BY <group_by_list>
ORDER BY <order_by_list>
优化方法:
1.与inner join一样,在被驱动表的连接条件上创建索引
2.inner join + 排序往往会在执行计划里面伴随着Using temporary Using filesort关键字出现,如果临时表或者排序的数据量很大,那么将会导致查询非常慢,需要特别重视;反之,临时表或者排序的数据量较小,例如只有几百条,那么即使执行计划有Using temporary Using filesort关键字,对查询速度影响也不大。如果说排序操作消耗了大部分的时间,那么可以考虑使用索引的有序性来消除排序,接下来对该优化方法进行讨论。
group by和order by都会对相关列进行排序,根据SQL是否存在GROUP BY或者ORDER BY关键字,分3种情况讨论:
|
SQL语句存在 group by |
SQL语句存在 order by |
优化操作考虑的排序列 | 解释 | |
| 情况1 | 是 | 否 | 只需考虑group by相关列排序问题即可 | 如果SQL语句中只含有group by,则只需考虑group by后面的列排序问题即可 |
| 情况2 | 否 | 是 | 只需考虑order by相关列排序问题即可 | 如果SQL语句中只含有order by,则只需考虑order by后面的列排序问题即可 |
| 情况3 | 是 | 是 | 只需考虑group by相关列排序问题即可 |
如果SQL语句中同时含有group by和order by,只需考虑group by后面的排序即可。 因为MySQL先执行group by,后执行order by,通常group by之后数据量已经较少了, 后续的order by直接在磁盘上排序即可 |
对于上面3种情况:
1.如果优化考虑的排序列全部来源于驱动表,则可以考虑:在等值谓词过滤条件上+排序列上创建复合索引,这样可以使用索引先过滤数据,再使用索引按顺序获取数据。
2.如果优化考虑的排序列全部来源于某个被驱动表,则可以考虑:使用表连接hint(Straight_JOIN)控制连接顺序,将排序相关表设置为驱动表,然后按照1创建复合索引;
3.如果优化考虑的排序列来源于多个表,貌似没有好的解决办法,有想法的同学也可以留言,一起进步。
例子1:如果优化考虑的排序列全部来源于驱动表,则可以考虑:在等值谓词过滤条件上+排序列上创建复合索引,这样可以使用索引先过滤数据,再使用索引按顺序获取数据。
-- 1.驱动表e上存在排序 mysql> explain select e.first_name,sum(salary) from employees_new e inner join salaries_new s on e.emp_no = s.emp_no where e.last_name = 'Aamodt' group by e.first_name; +----+-------------+-------+------------+------+------------------------------------------------------+------------------------------+---------+--------------------+------+----------+-----------------------------------------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+------------------------------------------------------+------------------------------+---------+--------------------+------+----------+-----------------------------------------------------------+ | 1 | SIMPLE | e | NULL | ref | idx_employees_new_empno,idx_lastname_empno_firstname | idx_lastname_empno_firstname | 18 | const | 205 | 100.00 | Using where; Using index; Using temporary; Using filesort | | 1 | SIMPLE | s | NULL | ref | idx_empno | idx_empno | 4 | employees.e.emp_no | 9 | 100.00 | NULL | +----+-------------+-------+------------+------+------------------------------------------------------+------------------------------+---------+--------------------+------+----------+-----------------------------------------------------------+ -- 2.在驱动表e上的等值谓词过滤条件last_name和排序列first_name上创建索引 mysql> create index idx_lastname_firstname on employees_new (last_name,first_name); -- 3.可以看到,排序消除 mysql> explain select e.first_name,sum(salary) from employees_new e inner join salaries_new s on e.emp_no = s.emp_no where e.last_name = 'Aamodt' group by e.first_name; +----+-------------+-------+------------+------+----------------------------------------------------------------------------------+------------------------+---------+--------------------+------+----------+-----------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+----------------------------------------------------------------------------------+------------------------+---------+--------------------+------+----------+-----------------------+ | 1 | SIMPLE | e | NULL | ref | idx_employees_new_empno,idx_employees_new_empno_firstname,idx_lastname_firstname | idx_lastname_firstname | 18 | const | 205 | 100.00 | Using index condition | | 1 | SIMPLE | s | NULL | ref | idx_empno | idx_empno | 4 | employees.e.emp_no | 9 | 100.00 | NULL | +----+-------------+-------+------------+------+----------------------------------------------------------------------------------+------------------------+---------+--------------------+------+----------+-----------------------+
需要说明的是,消除排序只是提供了一种数据优化的方式,消除排序后,其速度并不一定会比之前快,需要具体问题具体分析测试。
例子2:如果优化考虑的排序列全部来源于某个被驱动表,则可以考虑:使用表连接hint(Straight_JOIN)控制连接顺序,将排序相关表设置为驱动表,然后按照1创建复合索引;
-- 1. 被驱动表s上存在排序 mysql> explain select s.from_date,sum(salary) from employees_new e inner join salaries_new s on e.emp_no = s.emp_no where e.last_name = 'Aamodt' and s.salary = 40000 group by s.from_date; +----+-------------+-------+------------+------+------------------...-------+------------------------+---------+--------------------+------+----------+---------------------------------+ | id | select_type | table | partitions | type | possible_keys ... | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+------------------...-------+------------------------+---------+--------------------+------+----------+---------------------------------+ | 1 | SIMPLE | e | NULL | ref | idx_employees_new...stname | idx_lastname_firstname | 18 | const | 205 | 100.00 | Using temporary; Using filesort | | 1 | SIMPLE | s | NULL | ref | idx_empno ... | idx_empno | 4 | employees.e.emp_no | 9 | 10.00 | Using where | +----+-------------+-------+------------+------+------------------...-------+------------------------+---------+--------------------+------+----------+---------------------------------+ -- 2. 使用Straight_join改变表的连接顺序 mysql> explain select s.from_date,sum(salary) from salaries_new s STRAIGHT_JOIN employees_new e on e.emp_no = s.emp_no where e.last_name = 'Aamodt' and s.salary = 40000 group by s.from_date; +----+-------------+-------+------------+------+-----------------...----------+-------------------------+---------+--------------------+---------+----------+----------------------------------------------+ | id | select_type | table | partitions | type | possible_keys ... | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+-----------------...----------+-------------------------+---------+--------------------+---------+----------+----------------------------------------------+ | 1 | SIMPLE | s | NULL | ALL | idx_empno ... | NULL | NULL | NULL | 2837194 | 10.00 | Using where; Using temporary; Using filesort | | 1 | SIMPLE | e | NULL | ref | idx_employees_ne...firstname | idx_employees_new_empno | 4 | employees.s.emp_no | 1 | 5.00 | Using where | +----+-------------+-------+------------+------+-----------------...----------+-------------------------+---------+--------------------+---------+----------+----------------------------------------------+ -- 3. 在新的驱动表上创建等值谓词+排序列索引 mysql> create index idx_salary_fromdate on salaries_new(salary,from_date); Query OK, 0 rows affected (5.39 sec) Records: 0 Duplicates: 0 Warnings: 0 -- 4. 可以看到,消除排序 mysql> explain select s.from_date,sum(salary) from salaries_new s STRAIGHT_JOIN employees_new e on e.emp_no = s.emp_no where e.last_name = 'Aamodt' and s.salary = 40000 group by s.from_date; +----+-------------+-------+------------+------+---------------------------------...--+-------------------------+---------+--------------------+--------+----------+-----------------------+ | id | select_type | table | partitions | type | possible_keys ... | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------------------------...--+-------------------------+---------+--------------------+--------+----------+-----------------------+ | 1 | SIMPLE | s | NULL | ref | idx_empno,idx_salary_fromdate ... | idx_salary_fromdate | 4 | const | 199618 | 100.00 | Using index condition | | 1 | SIMPLE | e | NULL | ref | idx_employees_new_empno,idx_empl...e | idx_employees_new_empno | 4 | employees.s.emp_no | 1 | 5.00 | Using where | +----+-------------+-------+------------+------+---------------------------------...--+-------------------------+---------+--------------------+--------+----------+-----------------------+
需要说明的是,大部分情况下,MySQL优化器会自动选择最优的表连接方式,Straight_join的引入往往会造成大表做驱动表的情况出现,虽然消除了排序,但是又引入了新的麻烦。到底是排序带来的开销大,还是NLJ循环嵌套不合理带来的开销大,需要具体情况具体分析。
(5.3)left join优化
在MySQL中外连接(left join、right join 、full join)会被优化器转换为left join,因此,外连接只需讨论left join即可。常规left join的SQL语法如下:
SELECT <select_list> FROM <left_table> left join <right_table> ON <join_condition> WHERE <where_condition> GROUP BY <group_by_list> ORDER BY <order_by_list>
优化方法:
1.与inner join一样,在被驱动表的连接条件上创建索引
2.left join的表连接顺序都是从左像右的,我们无法改变表连接顺序。但是如果右表在where条件中存在谓词过滤,则MySQL会将left join自动转换为inner join,其原理图如下:

例子1:.如果右表在where条件中存在谓词过滤,则MySQL会将left join自动转换为inner join
创建测试表:
create table dept ( deptno int, dname varchar(20) ); insert into dept values (10, 'sales'),(20, 'hr'),(30, 'product'),(40, 'develop'); create table emp ( empno int, ename varchar(20), deptno varchar(20) ); insert into emp values (1,'aa',10),(2,'bb',10),(3,'cc',20),(4,'dd',30),(5,'ee',30);
执行left join,查看其执行计划,发现并不是左表作为驱动表
mysql> explain select d.dname,e.ename from dept d left join emp e on d.deptno = e.deptno where e.deptno = 30; +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+ | 1 | SIMPLE | e | NULL | ALL | NULL | NULL | NULL | NULL | 5 | 20.00 | Using where | | 1 | SIMPLE | d | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 25.00 | Using where; Using join buffer (Block Nested Loop) | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
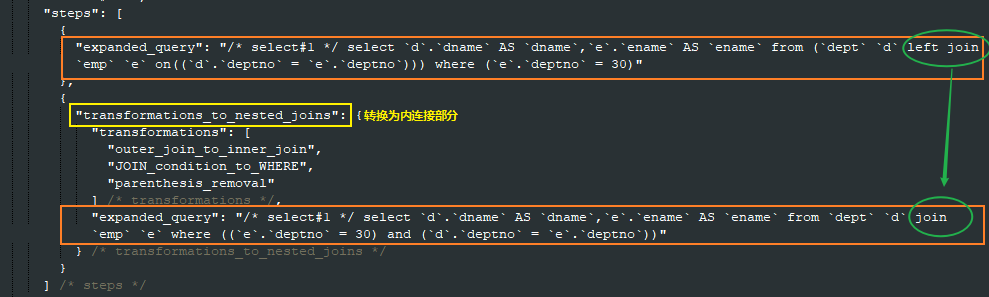
通过trace追踪,发现MySQL对其该语句进行了等价改写,将外连接改为了内连接。


mysql> set optimizer_trace="enabled=on",end_markers_in_JSON=on; Query OK, 0 rows affected (0.00 sec) mysql> select d.dname,e.ename from dept d left join emp e on d.deptno = e.deptno where e.deptno = 30; +---------+-------+ | dname | ename | +---------+-------+ | product | dd | | product | ee | +---------+-------+ 2 rows in set (0.03 sec) mysql> select * from information_schema.optimizer_trace; | MISSING_BYTES_BEYOND_MAX_MEM_SIZE | INSUFFICIENT_PRIVILEGES | select d.dname,e.ename from dept d left join emp e on d.deptno = e.deptno where e.deptno = 30 | { "steps": [ { "join_preparation": { "select#": 1, "steps": [ { "expanded_query": "/* select#1 */ select `d`.`dname` AS `dname`,`e`.`ename` AS `ename` from (`dept` `d` left join `emp` `e` on((`d`.`deptno` = `e`.`deptno`))) where (`e`.`deptno` = 30)" }, { "transformations_to_nested_joins": { "transformations": [ "outer_join_to_inner_join", "JOIN_condition_to_WHERE", "parenthesis_removal" ] /* transformations */, "expanded_query": "/* select#1 */ select `d`.`dname` AS `dname`,`e`.`ename` AS `ename` from `dept` `d` join `emp` `e` where ((`e`.`deptno` = 30) and (`d`.`deptno` = `e`.`deptno`))" } /* transformations_to_nested_joins */ } ] /* steps */ } /* join_preparation */ }, { "join_optimization": { "select#": 1, "steps": [ { "condition_processing": { "condition": "WHERE", "original_condition": "((`e`.`deptno` = 30) and (`d`.`deptno` = `e`.`deptno`))", "steps": [ { "transformation": "equality_propagation", "resulting_condition": "((`e`.`deptno` = 30) and (`d`.`deptno` = `e`.`deptno`))" }, { "transformation": "constant_propagation", "resulting_condition": "((`e`.`deptno` = 30) and (`d`.`deptno` = `e`.`deptno`))" }, { "transformation": "trivial_condition_removal", "resulting_condition": "((`e`.`deptno` = 30) and (`d`.`deptno` = `e`.`deptno`))" } ] /* steps */ } /* condition_processing */ }, { "substitute_generated_columns": { } /* substitute_generated_columns */ }, { "table_dependencies": [ { "table": "`dept` `d`", "row_may_be_null": false, "map_bit": 0, "depends_on_map_bits": [ ] /* depends_on_map_bits */ }, { "table": "`emp` `e`", "row_may_be_null": true, "map_bit": 1, "depends_on_map_bits": [ ] /* depends_on_map_bits */ } ] /* table_dependencies */ }, { "ref_optimizer_key_uses": [ ] /* ref_optimizer_key_uses */ }, { "rows_estimation": [ { "table": "`dept` `d`", "table_scan": { "rows": 4, "cost": 1 } /* table_scan */ }, { "table": "`emp` `e`", "table_scan": { "rows": 5, "cost": 1 } /* table_scan */ } ] /* rows_estimation */ }, { "considered_execution_plans": [ { "plan_prefix": [ ] /* plan_prefix */, "table": "`dept` `d`", "best_access_path": { "considered_access_paths": [ { "rows_to_scan": 4, "access_type": "scan", "resulting_rows": 4, "cost": 1.8, "chosen": true } ] /* considered_access_paths */ } /* best_access_path */, "condition_filtering_pct": 100, "rows_for_plan": 4, "cost_for_plan": 1.8, "rest_of_plan": [ { "plan_prefix": [ "`dept` `d`" ] /* plan_prefix */, "table": "`emp` `e`", "best_access_path": { "considered_access_paths": [ { "rows_to_scan": 5, "access_type": "scan", "using_join_cache": true, "buffers_needed": 1, "resulting_rows": 1, "cost": 2.6007, "chosen": true } ] /* considered_access_paths */ } /* best_access_path */, "condition_filtering_pct": 100, "rows_for_plan": 4, "cost_for_plan": 4.4007, "chosen": true } ] /* rest_of_plan */ }, { "plan_prefix": [ ] /* plan_prefix */, "table": "`emp` `e`", "best_access_path": { "considered_access_paths": [ { "rows_to_scan": 5, "access_type": "scan", "resulting_rows": 1, "cost": 2, "chosen": true } ] /* considered_access_paths */ } /* best_access_path */, "condition_filtering_pct": 100, "rows_for_plan": 1, "cost_for_plan": 2, "rest_of_plan": [ { "plan_prefix": [ "`emp` `e`" ] /* plan_prefix */, "table": "`dept` `d`", "best_access_path": { "considered_access_paths": [ { "rows_to_scan": 4, "access_type": "scan", "using_join_cache": true, "buffers_needed": 1, "resulting_rows": 4, "cost": 1.8002, "chosen": true } ] /* considered_access_paths */ } /* best_access_path */, "condition_filtering_pct": 100, "rows_for_plan": 4, "cost_for_plan": 3.8002, "chosen": true } ] /* rest_of_plan */ } ] /* considered_execution_plans */ }, { "attaching_conditions_to_tables": { "original_condition": "((`e`.`deptno` = 30) and (`d`.`deptno` = `e`.`deptno`))", "attached_conditions_computation": [ ] /* attached_conditions_computation */, "attached_conditions_summary": [ { "table": "`emp` `e`", "attached": "(`e`.`deptno` = 30)" }, { "table": "`dept` `d`", "attached": "(`d`.`deptno` = `e`.`deptno`)" } ] /* attached_conditions_summary */ } /* attaching_conditions_to_tables */ }, { "refine_plan": [ { "table": "`emp` `e`" }, { "table": "`dept` `d`" } ] /* refine_plan */ } ] /* steps */ } /* join_optimization */ }, { "join_execution": { "select#": 1, "steps": [ ] /* steps */ } /* join_execution */ } ] /* steps */ } | 0 | 0 | +---------------------------------------------------------------------------- mysql>
【完】
参考:
1.嵌套循环连接算法:https://dev.mysql.com/doc/refman/5.7/en/nested-loop-joins.html
2.外部连接优化:https://dev.mysql.com/doc/refman/5.7/en/outer-join-optimization.html
Note:MySQL菜鸟一枚,文章仅代表个人观点,如有不对,敬请指出,共同进步,谢谢。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号