
爬虫大作业
Python抓取NBA现役球员的基本信息数据
一、要求
选择一个热点或者你感兴趣的主题、爬取的对象与范围,爬取相应的内容并做数据分析与文本分析,形成一篇有说明、技术要点、有数据、有数据分析图形化展示与说明、文本分析图形化展示与说明的文章。
数据来源:NBA中国官网
库:
requests 用于解析页面文本数据
pandas 用于处理数据
import requests
import pandas as pd
user_agent = 'User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)'
headers = {'User-Agent':user_agent}
url='http://china.nba.com/static/data/league/playerlist.json'
#解析网页
r=requests.get(url,headers=headers).json()
num=int(len(r['payload']['players']))-1 #得到列表r['payload']['players']的长度
p1_cols=[] #用来存放p1数组的列
p2_cols=[] #用来存放p2数组的列
#遍历其中一个['playerProfile'],['teamProfile'] 得到各自列名,添加到p1_cols和p2_cols列表中
for x in r['payload']['players'][0]['playerProfile']:
p1_cols.append(x)
for y in r['payload']['players'][0]['teamProfile']:
p2_cols.append(y)
p1=pd.DataFrame(columns=p1_cols) #初始化一个DataFrame p1 用来存放playerProfile下的数据
p2=pd.DataFrame(columns=p2_cols) #初始化一个DataFrame p1 用来存放playerProfile下的数据
#遍历一次得到一个球员的信息,分别添加到DataFrame数组中
for z in range(num):
player=pd.DataFrame([r['payload']['players'][z]['playerProfile']])
team=pd.DataFrame([r['payload']['players'][z]['teamProfile']])
p1=p1.append(player,ignore_index=True)
p2=p2.append(team,ignore_index=True)
p3=pd.merge(p1,p2,left_index=True,right_index=True)
p3.to_csv('f://nba_player.csv',index=False)
数据:
了解下基本的数据情况

截止全明星赛前有498名现役球员
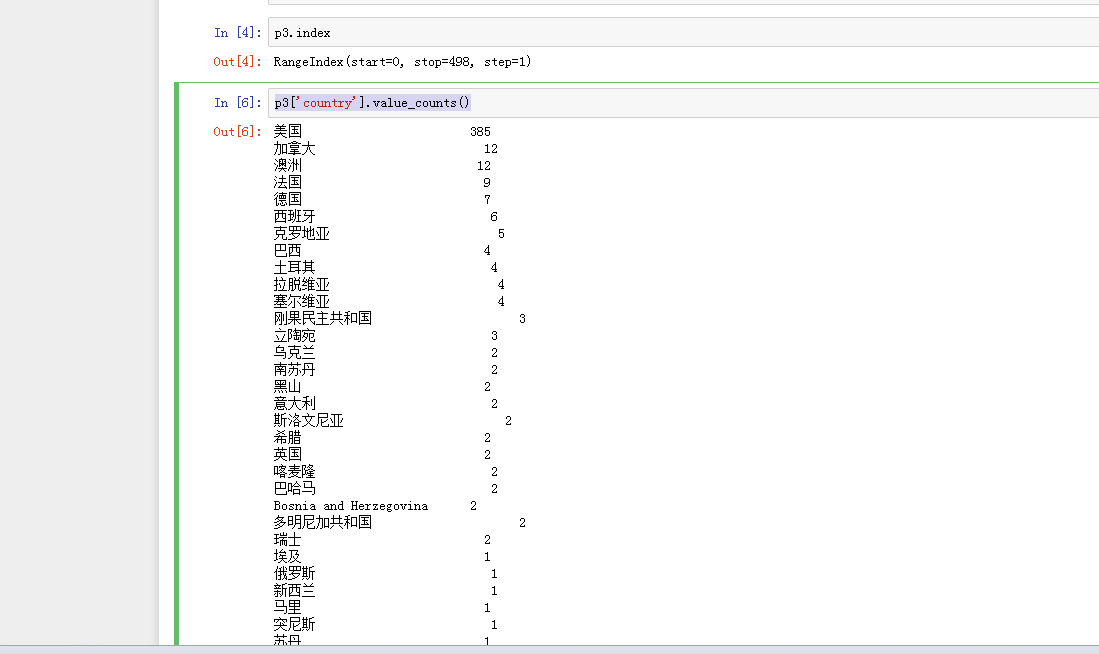
那么城市球员数量具体是多少呢?
p3['country'].value_counts()
球队的球员数:
p3['displayAbbr'].value_counts()
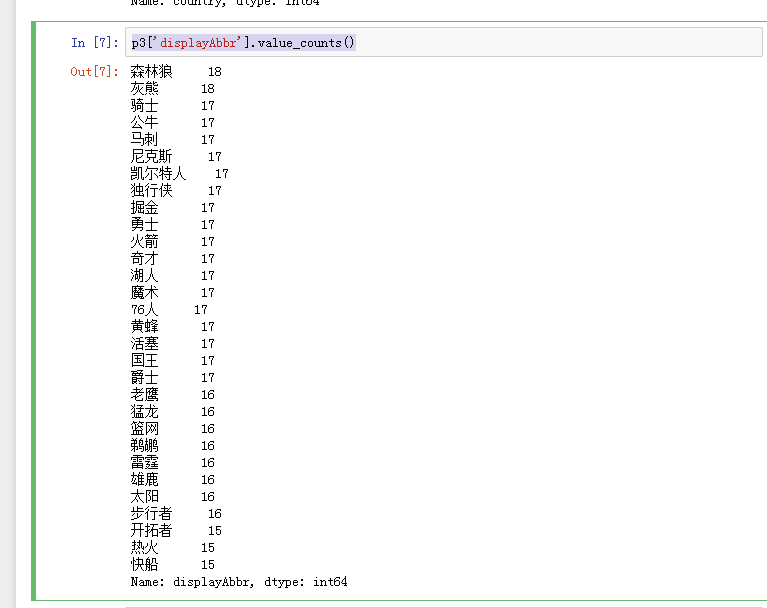
也就是说498名现役大名单球员里,有385名美国人
每一届球员的情况
p3['draftYear'].value_counts()


2019年4月29日火箭VS勇士赛前分析页面 https://sports.qq.com/a/20190428/006551.htm
import requests
from bs4 import BeautifulSoup
url='https://sports.qq.com/a/20190428/006551.htm'
res=requests.get(url)
res.encoding='gb2312'
res.text
生成词云:
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import jieba
txt=open(r'123.txt','r',encoding='utf-8').read()
wcdict1=[line.strip() for line in open('123.txt',encoding='utf-8').readlines()]
jieba.load_userdict(wcdict1)
# wcdict2=[line.strip() for line in open('stop_chinese2.txt',encoding='utf-8').readlines()]
# jieba.load_userdict(wcdict2)
wordsls = jieba.lcut(txt)
wcdict = {}
for word in wordsls:
if word not in wcdict1:
if len(word)==1:
continue
else:
wcdict[word]=wcdict.get(word,0)+1
wails=list(wcdict.items())
wails.sort(key=lambda x:x[1], reverse=True)
cut_text = " ".join(wordsls)
'print(cut_text)'
mywc = WordCloud(font_path = 'msyh.ttf').generate(cut_text)
plt.imshow(mywc)
plt.axis("off")
plt.show()
for i in range(25):
print(wails[i])


