爬取全部的校园新闻
import requests
from bs4 import BeautifulSoup
from datetime import datetime
import re
def click(url):
id =re.findall('(\d{1,5})',url)[-1]
clickUrl='http://oa.gzcc.cn/api.php?op=count&id={}&modelid=80'.format(id)
resClick=requests.get(clickUrl)
newsClick=int(resClick.text.split('.html')[-1].lstrip("('").rstrip("');"))
return newsClick
def newsdt(showinfo):
newsDate=showinfo.split()[0].split(':')[1]
newsTime=showinfo.split()[1]
newsDT=newsDate+' '+newsTime
dt=datetime.strptime(newsDT,'%Y-%m-%d %H:%M:%S')
return dt
def anews(url):
newsDetail={}
res=requests.get(url)
res.encoding='utf-8'
soup=BeautifulSoup(res.text,'html.parser')
newsDetail['nenewsTitle']=soup.select('.show-title')[0].text
showinfo=soup.select('.show-info')[0].text
newsDetail['newsDT']=newsdt(showinfo)
newsDetail['newsClick']=click(newsUrl)
return newsDetail
newsUrl='http://news.gzcc.cn/html/2005/xiaoyuanxinwen_0710/4.html'
anews(newsUrl)
res=requests.get('http://news.gzcc.cn/html/xiaoyuanxinwen/')
res.encoding='utf-8'
soup=BeautifulSoup(res.text,'html.parser')
for news in soup.select('li'):
if len(news.select('.news-list-title'))>0:
newsUrl=news.select('a')[0]['href']
print (anews(newsUrl))
listUrl='http://news.gzcc.cn/html/xiaoyuanxinwen/'
res=requests.get(listUrl)
res.encoding='utf-8'
soup=BeautifulSoup(res.text,'html.parser')
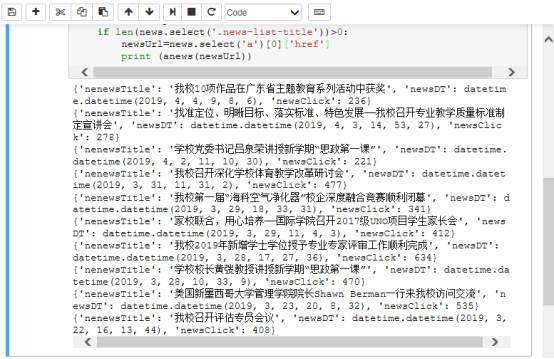
for n in soup.select('li'):
if n.select('.news-list-title'):
print(n)
listUrl='http://news.gzcc.cn/html/xiaoyuanxinwen/'
res=requests.get(listUrl)
res.encoding='utf-8'
soup=BeautifulSoup(res.text,'html.parser')
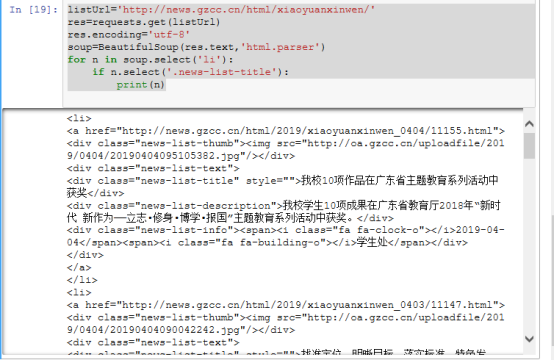
for n in soup.select('li'):
if n.select('.news-list-title'):
print(n.select('a')[0]['href'])
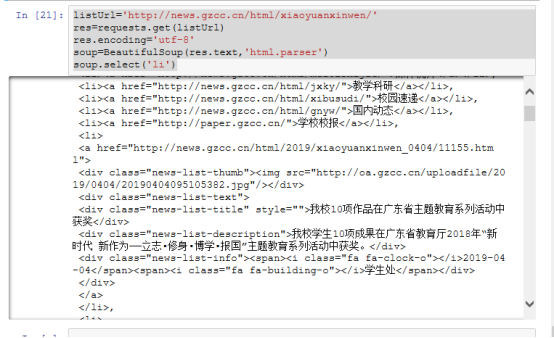
listUrl='http://news.gzcc.cn/html/xiaoyuanxinwen/'
res=requests.get(listUrl)
res.encoding='utf-8'
soup=BeautifulSoup(res.text,'html.parser')
soup.select('li')
listUrl='http://news.gzcc.cn/html/xiaoyuanxinwen/'
res=requests.get(listUrl)
res.encoding='utf-8'
soup=BeautifulSoup(res.text,'html.parser')
newsList=[]
for news in soup.select('li'):
if len(news.select('.news-list-title'))>0:
newsUrl=news.select('a')[0]['href']
newsDesc=news.select('.news-list-description')[0].text
newsDict=anews(newsUrl)
newsDict['description']=newsDesc
newsList.append(newsDict)
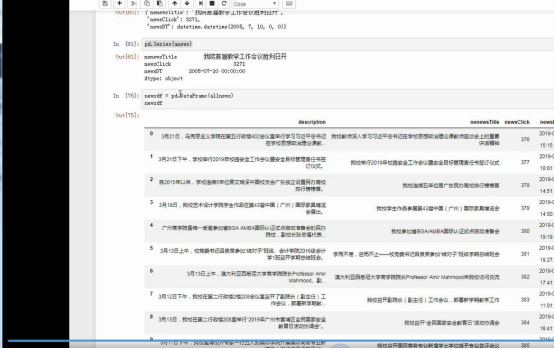
newsList

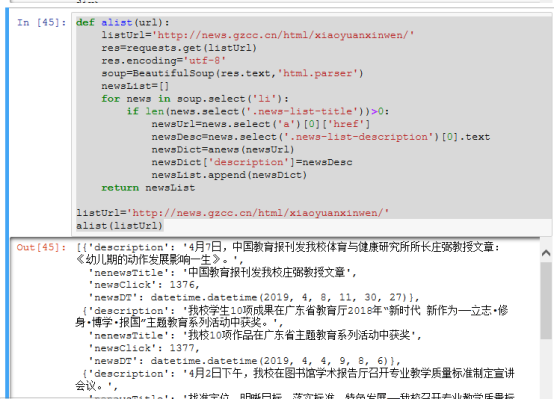
def alist(url):
listUrl='http://news.gzcc.cn/html/xiaoyuanxinwen/'
res=requests.get(listUrl)
res.encoding='utf-8'
soup=BeautifulSoup(res.text,'html.parser')
newsList=[]
for news in soup.select('li'):
if len(news.select('.news-list-title'))>0:
newsUrl=news.select('a')[0]['href']
newsDesc=news.select('.news-list-description')[0].text
newsDict=anews(newsUrl)
newsDict['description']=newsDesc
newsList.append(newsDict)
return newsList
listUrl='http://news.gzcc.cn/html/xiaoyuanxinwen/'
alist(listUrl)
allnews=[]
for i in range(2,73):
listUrl='http://news.gzcc.cn/html/xiaoyuanxinwen/{}.html'.format(i)
allnews.extend(alist(listUrl))
len(allnews)