字符串、文件操作,英文词频统计预处理
解析身份证号:
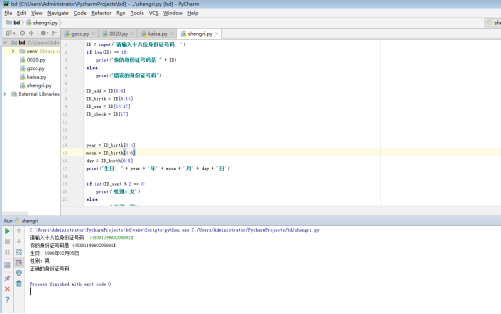
代码:ID = input('请输入十八位身份证号码: ')
if len(ID) == 18:
print("你的身份证号码是 " + ID)
else:
print("错误的身份证号码")
ID_add = ID[0:6]
ID_birth = ID[6:14]
ID_sex = ID[14:17]
ID_check = ID[17]
year = ID_birth[0:4]
moon = ID_birth[4:6]
day = ID_birth[6:8]
print("生日: " + year + '年' + moon + '月' + day + '日')
if int(ID_sex) % 2 == 0:
print('性别:女')
else:
print('性别:男')
W = [7, 9, 10, 5, 8, 4, 2, 1, 6, 3, 7, 9, 10, 5, 8, 4, 2]
ID_num = [18, 17, 16, 15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2]
ID_CHECK = ['1', '0', 'X', '9', '8', '7', '6', '5', '4', '3', '2']
ID_aXw = 0
for i in range(len(W)):
ID_aXw = ID_aXw + int(ID[i]) * W[i]
ID_Check = ID_aXw % 11
if ID_check == ID_CHECK[ID_Check]:
print('正确的身份证号码')
else:
print('错误的身份证号码')
凯撒密码编码与解码:
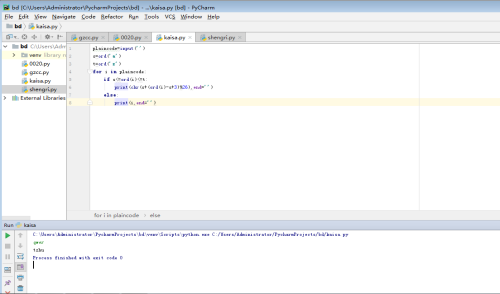
代码:plaincode=input('')
s=ord('a')
t=ord('z')
for i in plaincode:
if s<=ord(i)<=t:
print(chr(s+(ord(i)-s+3)%26),end='')
else:
print(i,end='')
网址观察与批量生成:
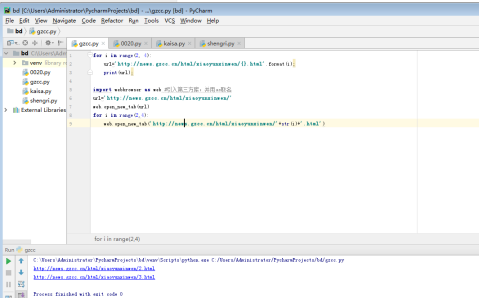
代码:for i in range(2, 4):
url='http://news.gzcc.cn/html/xiaoyunxinwen/{}.html'.format(i);
print(url);
import webbrowser as web #引入第三方库,并用as取名
url='http://news.gzcc.cn/html/xiaoyunxinwen/'
web.open_new_tab(url)
for i in range(2,4):
web.open_new_tab('http://news.gzcc.cn/html/xiaoyunxinwen/'+str(i)+'.html')
2.英文词频统计预处理
- 下载一首英文的歌词或文章或小说
- 将所有大写转换为小写
- 将所有其他做分隔符(,.?!)替换为空格
- 分隔出一个一个的单词
- 并统计单词出现的次数。
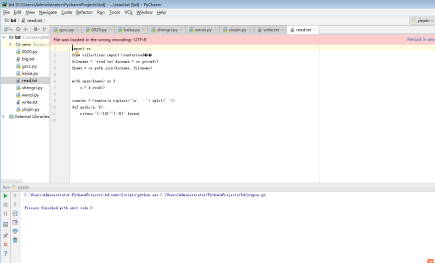
代码:import os
from collections import Counter
# 假设要读取文件名为read,位于当前路径
filename = 'read.txt'
# 当前进程工作目录
dirname = os.getcwd()
fname = os.path.join(dirname, filename)
with open(fname) as f:
s = f.read()
counter = Counter(s.replace('\n', ' ').split(' '))
# 格式化要输出的每行数据,尾占8位,首占18位
def geshi(a, b):
return "{:<18}""{:>8}".format(a,b) + '\n'
title = geshi('词', '频率')
results = []
# 要输出的数据,每一行由:词、频率+'\n'构成,序号=List.index(element)+1
for w, c in counter.most_common():
results.append(geshi(w, c))
# 将统计结果写入文件write.txt中
writefile = 'write.txt'
wpath = os.path.join(dirname, writefile)
with open(wpath, 'w') as f:
f.write(''.join([title] + sorted(results)))
