如何使用深度学习破解验证码 keras 连续验证码
在实现网络爬虫的过程中,验证码的出现总是会阻碍爬虫的工作。本期介绍一种利用深度神经网络来实现的端到端的验证码识别方法。通过本方法,可以在不切割图片、不做模板匹配的情况下实现精度超过90%的识别结果。
本文分为两个部分,第一个部分介绍如何利用深度神经网络实现验证码的训练和识别,第二个部分介绍在实现过程中需要克服的工程问题。
一. 基于深度神经网络的验证码识别
验证码的识别是从图片到文字的过程。传统的算法如OCR正是为了解决此类问题而设计的。然而,在真实情形中,验证码通常并不以规则的文字出现,即文字通常会有不同程度的变形,图像本身也通常会被添加或多或少的噪声。这些干扰的出现,使得文字分割、模板匹配不再有效,进而OCR算法也很难解析出结果。
近年来,深度神经网络(DNN)在图像识别领域已经被证明了强大的识别能力。单个文字的识别是典型的分类问题。通常的做法为训练一个深度神经网络,网络的最后一层分为N种类别,代表字符的数目。比如对于英文字母,最后一层的分类器便是26个。比如经典的LeNet(http://yann.lecun.com/exdb/lenet/)即为解决单个文字识别的网络:
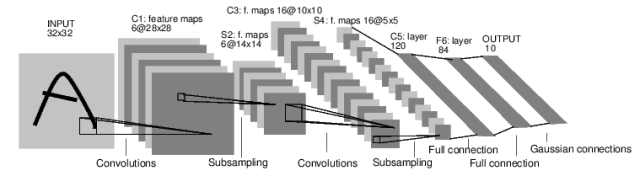
然而验证码通常包含多个字符,如何利用现有的网络实现这类分类问题呢?实际上这个问题再机器学习中被称为多标签训练问题。和上述每个图片输入只对应一个标签类别对比,这类分类的输出是多个标签。我们同样可以对传统的神经网络稍作改变以适应这种情况。
我们以最简单的英文字母为例介绍这个过程。如图一所示,此种验证码由5个字母组成;每个字母只取大写,共有26种类别;图片中有干扰线贯穿文字,使得文字分割比较困难。

图一. 验证码实例
接下来,我们设计如图二卷积神经网络:
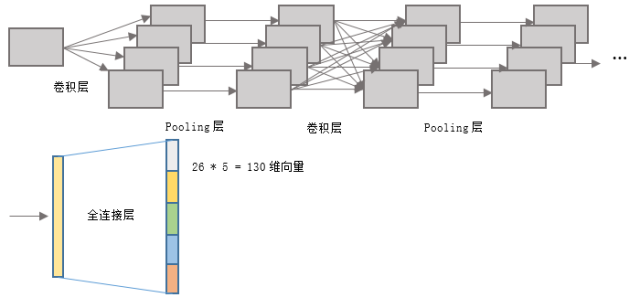
图二. 卷积神经网络
图二中的网络和一般的CNN网络没有什么特殊之处,前部均是卷积、Pooling层,只有最后在分类时,将26个类别扩增到26*5=130个类别。对于每幅图片的标签而言,在这130维的向量中,每26个维度中有一个1,其余为0,编码了五个字母。接着依然使用交叉熵作为代价函数进而优化此网络。就这样,只要对原先的分类网络做简单的改变即可解决验证码的识别问题。
再如对于数学表达式类型的验证码,我们的网络也只是在编码上把26分类问题变成了13分类问题。下例中(见图三)最后一层的分类器便设计为3*13=39个类别。
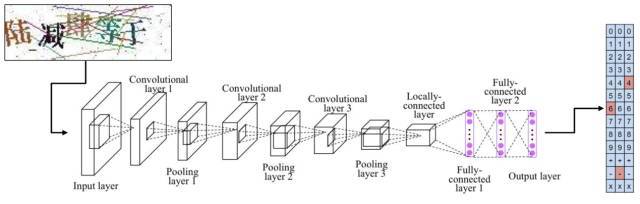
图三. 数学式类型验证码的识别
按照此种思路我们破解了很多风格的验证码,如图四所示:
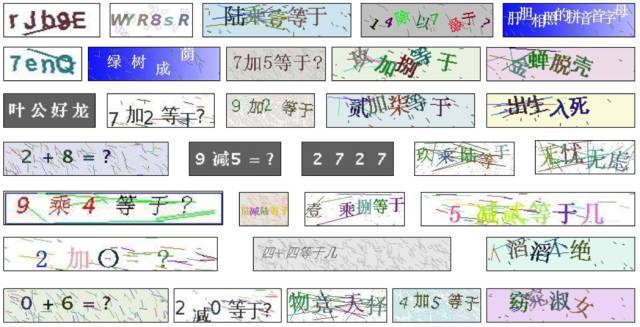
图四. 不同风格验证码破解实例
二. 一些需要解决的实际工程问题
(1) 合成训练数据
前文提到训练的前提是已经拥有了大量的训练数据,而实际在识别验证码时我们很难获取足够多的标注过的训练数据。所以,我们不得不人工合成训练数据。这一部分通常可以调用Java或者C#的文字渲染库来完成。
训练的数据并不是越多越好,主要的问题在于人工合成的数据未免和真实验证码在形态上有些差距,我们都很难合成出一模一样的结果。字体、字号及变形程度都或多或少与真实数据不同,而这种不同可能直接导致训练出的网络面对真实数据时无法发挥作用。
我们的经验是,针对真实数据的特点,在无法很相似地合成出训练数据的情况下,要增大样本的多样性,实际上也是遵循了深度学习中数据增强(Data Augmentation)的思想。如图五所示,左边为真实数据,我们在合成数据时特意增加了每个文字的旋转、平移,加大了噪声,使得训练出的网络能应对数据足够的变化,从而可以识别出左图中真实的例子。否则即便在合成数据上达到了很高的精度,在真实数据上也依然可能精度极低(即在合成数据上过拟合)。

图五. 合成数据实例
(2) 网络大小的选择
针对不同的任务,网络大小对结果的影响也是巨大的。并非所有的任务都得使用很深的网络来训练。理论上说,越深的网络自由度越大,同时也非常容易过拟合。虽然有weight_decay这样参数可以一定程度的对抗过拟合,但通常难度依然是很大的。所以一般来说,对于不太复杂的验证码应该选择较小的网络,只有遇到比较复杂的验证码如中文的成语等,我们的经验才是复杂的网络下效果才更好。
总之,验证码识别可以作为深度学习的一个练手项目来学习,在这个实际项目中可以更容易理解到深度学习理论中诸多概念。
转载于:http://www.saluzi.com/t/topic/16027
作者:EliteQing
出处:http://www.cnblogs.com/liinux/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
欢迎加入网络爬虫QQ群:322937592 ;数据分析&网络爬虫
网络爬虫模拟登录开源项目ghost-login:ghost-login
微信订阅号:网络爬虫AI数据分析【WebCrawlerAIDA】

 浙公网安备 33010602011771号
浙公网安备 33010602011771号