Hive客户端基本操作
一:DDL
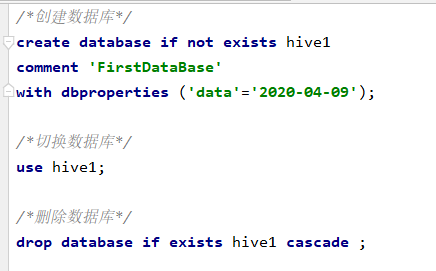
1:创建数据库
CREATE DATABASE [IF NOT EXISTS] database_name
[COMMENT database_comment] //对数据库的描述
[LOCATION hdfs_path] //手动设置数据库存储路径
[WITH DBPROPERTIES (property_name=property_value, ...)]; //增加数据库的属性(键值对)
2:创建表
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)]
[AS select_statement]
字段说明:
(1)CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用 IF NOT EXISTS 选项来忽略这个异常。
(2)EXTERNAL 关键字可以让用户创建一个外部表,在建表的同时可以指定一个指向实际数据的路径(LOCATION),在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。
(3)COMMENT:为表和列添加注释。
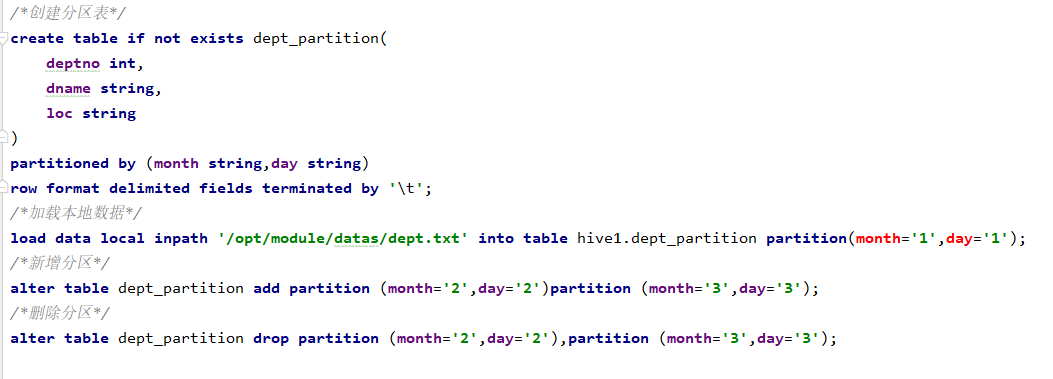
(4)PARTITIONED BY 创建分区表
(5)CLUSTERED BY 创建分桶表
(6)SORTED BY 不常用,对桶中的一个或多个列另外排序
(8)STORED AS 指定存储文件类型常用的存储文件类型:SEQUENCEFILE(二进制序列文件)、TEXTFILE(文本)、RCFILE(列式存储格式文件)如果文件数据是纯文本,可以使用 STORED AS TEXTFILE。如果数据需要压缩,使
用 STORED AS SEQUENCEFILE。
(9)LOCATION :指定表在 HDFS 上的存储位置。
(10)AS:后跟查询语句,根据查询结果创建表。
(11)LIKE 允许用户复制现有的表结构,但是不复制数据。
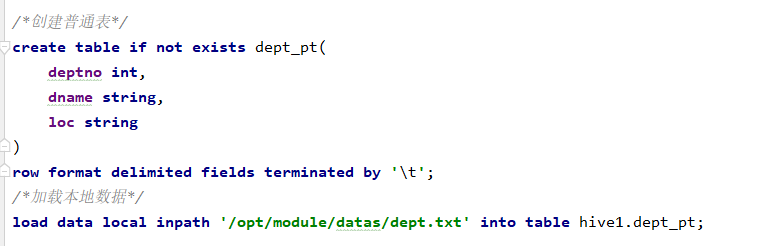
(1)创建普通表
(2)创建分区表
(3)创建分桶表

二:DML
1:数据导入
(1)
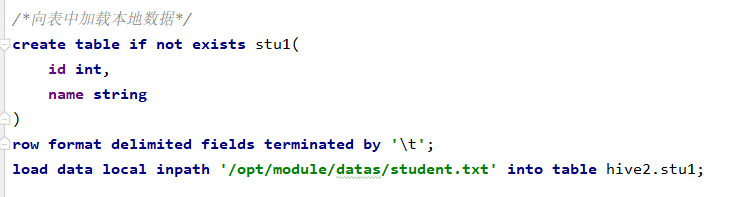
(2)
···· 
(3)

2:数据导出
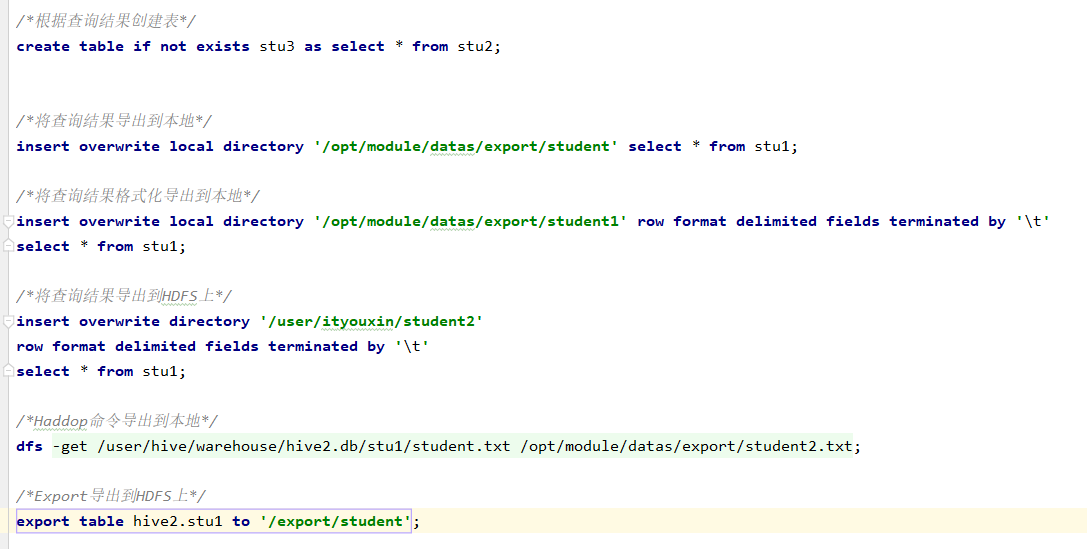
3:清除表中数据
truncate table student; //只能清除管理表数据
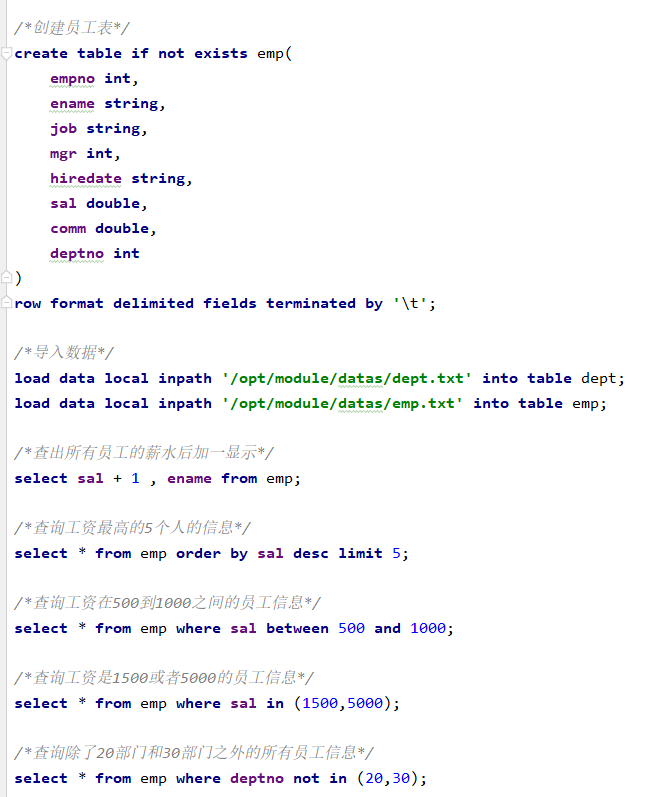
三:DQL
练习


四:其他常用查询函数
1:
NVL:给值为 NULL 的数据赋值,它的格式是 NVL( value,default_value)。它的功能是
如果 value 为 NULL,则 NVL 函数返回 default_value 的值,否则返回 value 的值,如果两个
参数都为 NULL ,则返回 NULL。
2:
CASE WHEN
3:
行转列:CONCAT
4:
列转行:EXPLODE
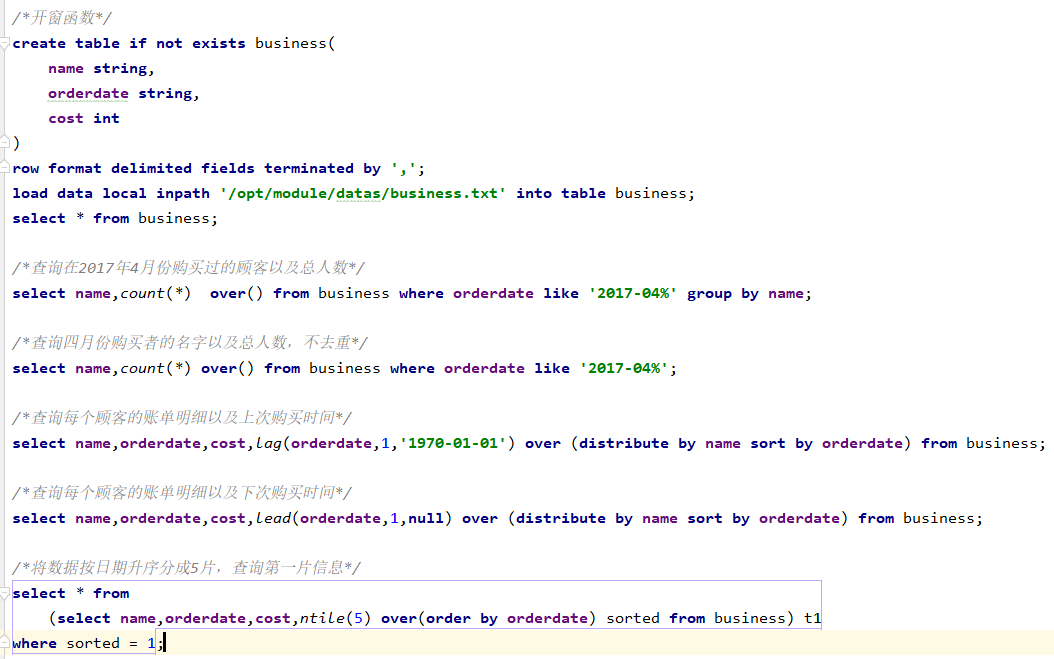
5:开窗函数
OVER():指定分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变而变化。
CURRENT ROW:当前行
n PRECEDING:往前 n 行数据
n FOLLOWING:往后 n 行数据
UNBOUNDED:起点,UNBOUNDED PRECEDING 表示从前面的起点,
UNBOUNDED
FOLLOWING 表示到后面的终点
LAG(col,n,default_val):往前第 n 行数据
LEAD(col,n, default_val):往后第 n 行数据