

redis cluster介绍
讲解分布式数据存储的核心算法,数据分布的算法
hash算法 -> 一致性hash算法(memcached) -> redis cluster,hash slot算法
一、概述
1、我们的memcache客户端(这里我看的spymemcache的源码),使用了一致性hash算法ketama进行数据存储节点的选择。与常规的hash算法思路不同,只是对我们要存储数据的key进行hash计算,分配到不同节点存储。一致性hash算法是对我们要存储数据的服务器进行hash计算,进而确认每个key的存储位置。
2、常规hash算法的应用以及其弊端
最常规的方式莫过于hash取模的方式。比如集群中可用机器适量为N,那么key值为K的的数据请求很简单的应该路由到hash(K) mod N对应的机器。的确,这种结构是简单的,也是实用的。但是在一些高速发展的web系统中,这样的解决方案仍有些缺陷。随着系统访问压力的增长,缓存系统不得不通过增加机器节点的方式提高集群的相应速度和数据承载量。增加机器意味着按照hash取模的方式,在增加机器节点的这一时刻,大量的缓存命不中,缓存数据需要重新建立,甚至是进行整体的缓存数据迁移,瞬间会给DB带来极高的系统负载,设置导致DB服务器宕机。
3、设计分布式cache系统时,一致性hash算法可以帮我们解决哪些问题?
分布式缓存设计核心点:在设计分布式cache系统的时候,我们需要让key的分布均衡,并且在增加cache server后,cache的迁移做到最少。
这里提到的一致性hash算法ketama的做法是:选择具体的机器节点不在只依赖需要缓存数据的key的hash本身了,而是机器节点本身也进行了hash运算。
二、一致性哈希算法情景描述(转载)
如假设某哈希函数H的值空间为0-2^32-1(即哈希值是一个32位无符号整形),整个哈希空间环如下:

下一步将各个服务器使用Hash进行一个哈希,具体可以选择服务器的ip或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置,这里假设将上文中四台服务器使用ip地址哈希后在环空间的位置如下:

接下来使用如下算法定位数据访问到相应服务器:将数据key使用相同的函数Hash计算出哈希值,并确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器。
例如我们有Object A、Object B、Object C、Object D四个数据对象,经过哈希计算后,在环空间上的位置如下:

根据一致性哈希算法,数据A会被定为到Node A上,B被定为到Node B上,C被定为到Node C上,D被定为到Node D上。
下面分析一致性哈希算法的容错性和可扩展性。现假设Node C不幸宕机,可以看到此时对象A、B、D不会受到影响,只有C对象被重定位到Node D。一般的,在一致性哈希算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响。
下面考虑另外一种情况,如果在系统中增加一台服务器Node X,如下图所示:

此时对象Object A、B、D不受影响,只有对象C需要重定位到新的Node X 。一般的,在一致性哈希算法中,如果增加一台服务器,则受影响的数据仅仅是新服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它数据也不会受到影响。
综上所述,一致性哈希算法对于节点的增减都只需重定位环空间中的一小部分数据,具有较好的容错性和可扩展性。
Consistent Hashing最大限度地抑制了hash键的重新分布。另外要取得比较好的负载均衡的效果,往往在服务器数量比较少的时候需要增加虚拟节点来保证服务器能均匀的分布在圆环上。因为使用一般的hash方法,服务器的映射地点的分布非常不均匀。使用虚拟节点的思想,为每个物理节点(服务器)在圆上分配100~200个点。这样就能抑制分布不均匀,最大限度地减小服务器增减时的缓存重新分布。用户数据映射在虚拟节点上,就表示用户数据真正存储位置是在该虚拟节点代表的实际物理服务器上。
下面有一个图描述了需要为每台物理服务器增加的虚拟节点。
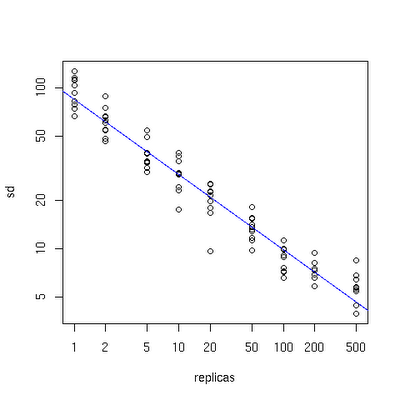
图三
x轴表示的是需要为每台物理服务器扩展的虚拟节点倍数(scale),y轴是实际物理服务器数,可以看出,当物理服务器的数量很小时,需要更大的虚拟节点,反之则需要更少的节点,从图上可以看出,在物理服务器有10台时,差不多需要为每台服务器增加100~200个虚拟节点才能达到真正的负载均衡。
三、以spymemcache源码来演示虚拟节点应用
1、上边描述的一致性Hash算法有个潜在的问题是:
(1)、将节点hash后会不均匀地分布在环上,这样大量key在寻找节点时,会存在key命中各个节点的概率差别较大,无法实现有效的负载均衡。
(2)、如有三个节点Node1,Node2,Node3,分布在环上时三个节点挨的很近,落在环上的key寻找节点时,大量key顺时针总是分配给Node2,而其它两个节点被找到的概率都会很小。
2、这种问题的解决方案可以有:
改善Hash算法,均匀分配各节点到环上;[引文]使用虚拟节点的思想,为每个物理节点(服务器)在圆上分配100~200个点。这样就能抑制分布不均匀,最大限度地减小服务器增减时的缓存重新分布。用户数据映射在虚拟节点上,就表示用户数据真正存储位置是在该虚拟节点代表的实际物理服务器上。
在查看Spy Memcached client时,发现它采用一种称为Ketama的Hash算法,以虚拟节点的思想,解决Memcached的分布式问题。
3、源码说明
该client采用TreeMap存储所有节点,模拟一个环形的逻辑关系。在这个环中,节点之前是存在顺序关系的,所以TreeMap的key必须实现Comparator接口。
那节点是怎样放入这个环中的呢?
protected void setKetamaNodes(List<MemcachedNode> nodes) { TreeMap<Long, MemcachedNode> newNodeMap = new TreeMap<Long, MemcachedNode>(); int numReps= config.getNodeRepetitions(); for(MemcachedNode node : nodes) { // Ketama does some special work with md5 where it reuses chunks. if(hashAlg == HashAlgorithm.KETAMA_HASH) { for(int i=0; i<numReps / 4; i++) { byte[] digest=HashAlgorithm.computeMd5(config.getKeyForNode(node, i)); for(int h=0;h<4;h++) { Long k = ((long)(digest[3+h*4]&0xFF) << 24) | ((long)(digest[2+h*4]&0xFF) << 16) | ((long)(digest[1+h*4]&0xFF) << 8) | (digest[h*4]&0xFF); newNodeMap.put(k, node); getLogger().debug("Adding node %s in position %d", node, k); } } } else { for(int i=0; i<numReps; i++) { newNodeMap.put(hashAlg.hash(config.getKeyForNode(node, i)), node); } } } assert newNodeMap.size() == numReps * nodes.size(); ketamaNodes = newNodeMap;
上面的流程大概可以这样归纳:四个虚拟结点为一组,以getKeyForNode方法得到这组虚拟节点的name,Md5编码后,每个虚拟结点对应Md5码16个字节中的4个,组成一个long型数值,做为这个虚拟结点在环中的惟一key。第10行k为什么是Long型的呢?就是因为Long型实现了Comparator接口。
处理完正式结点在环上的分布后,可以开始key在环上寻找节点的游戏了。
对于每个key还是得完成上面的步骤:计算出Md5,根据Md5的字节数组,通过Kemata Hash算法得到key在这个环中的位置。
MemcachedNode getNodeForKey(long hash) { final MemcachedNode rv; if(!ketamaNodes.containsKey(hash)) { // Java 1.6 adds a ceilingKey method, but I'm still stuck in 1.5 // in a lot of places, so I'm doing this myself. SortedMap<Long, MemcachedNode> tailMap=getKetamaNodes().tailMap(hash); if(tailMap.isEmpty()) { hash=getKetamaNodes().firstKey(); } else { hash=tailMap.firstKey(); } } rv=getKetamaNodes().get(hash); return rv; }
上边代码的实现就是在环上顺时针查找,没找到就去的第一个,然后就知道对应的物理节点了。
四、应用场景分析
1、memcache的add方法:通过一致性hash算法确认当前客户端对应的cacheserver的hash值以及要存储数据key的hash进行对应,确认cacheserver,获取connection进行数据存储
2、memcache的get方法:通过一致性hash算法确认当前客户端对应的cacheserver的hash值以及要提取数据的hash值,进而确认存储的cacheserver,获取connection进行数据提取
五、总结
1、一致性hash算法只是帮我们减少cache集群中的机器数量增减的时候,cache的数据能进行最少重建。只要cache集群的server数量有变化,必然产生数据命中的问题
2、对于数据的分布均衡问题,通过虚拟节点的思想来达到均衡分配。当然,我们cache server节点越少就越需要虚拟节点这个方式来均衡负载。
3、我们的cache客户端根本不会维护一个map来记录每个key存储在哪里,都是通过key的hash和cacheserver(也许ip可以作为参数)的hash计算当前的key应该存储在哪个节点上。
4、当我们的cache节点崩溃了。我们必定丢失部分cache数据,并且要根据活着的cache server和key进行新的一致性匹配计算。有可能对部分没有丢失的数据也要做重建...
5、至于正常到达数据存储节点,如何找到key对应的数据,那就是cache server本身的内部算法实现了,此处不做描述。
前言
对于之前所讲的master+slave进行读写分离同时通过sentinel集群保障高可用的架构,对于一般的数据量系统已经足够。但是对于数据量庞大的T级别的数据,单master可能就无法满足横向扩展的场景。
所以redis cluster支持多master+slave架构,支持读写分离和主备切换,多个master支持分片hash slot分布式存储数据
1、redis cluster介绍
redis cluster
(1)自动将数据进行分片,每个master上放一部分数据
(2)提供内置的高可用支持,部分master不可用时,还是可以继续工作的
在redis cluster架构下,每个redis要放开两个端口号,比如一个是6379,另外一个就是加10000的端口号,比如16379
16379端口号是用来进行节点间通信的,也就是cluster bus的东西,集群总线。cluster bus的通信,用来进行故障检测,配置更新,故障转移授权
cluster bus用了另外一种二进制的协议,主要用于节点间进行高效的数据交换,占用更少的网络带宽和处理时间
2、最老土的hash算法和弊端(大量缓存重建)
3、一致性hash算法(自动缓存迁移)+虚拟节点(自动负载均衡)
4、redis cluster的hash slot算法
redis cluster有固定的16384个hash slot,对每个key计算CRC16值,然后对16384取模,可以获取key对应的hash slot
redis cluster中每个master都会持有部分slot,比如有3个master,那么可能每个master持有5000多个hash slot
hash slot让node的增加和移除很简单,增加一个master,就将其他master的hash slot移动部分过去,减少一个master,就将它的hash slot移动到其他master上去
移动hash slot的成本是非常低的
客户端的api,可以对指定的数据,让他们走同一个hash slot,通过hash tag来实现
redis cluster的重要配置
1 cluster-enabled <yes/no> 2 3 cluster-config-file <filename>:指定一个文件,供cluster模式下的redis实例将集群状态保存在起来,包括集群中其他机器的信息,比如节点的上线和下线,故障转移,这些不是我们去维护,提供一个文件地址,让redis自己去维护 4 5 cluster-node-timeout <milliseconds>:节点存活超时时长,超过一定时长,认为节点宕机,master宕机的话就会触发主备切换,slave宕机就不会提供服务
在3台机器上启动6个redis实例
对于redis cluster集群,要求至少3个master,从而能够组成一个健壮的分布式的集群,每个master都建议至少给一个slave,3个master,3个slave,所以建议在正式环境下,能够部署6台机器去搭建redis cluster集群,最少的情况是有3台机器,此时需要master和对应的slave不再同一台机器
我们模拟7001-7006端口号来部署6个redis节点,每台机器部署两个节点:
1 mkdir -p /etc/redis-cluster 存放cluster-config-file信息 2 mkdir -p /var/log/redis 存放redis的日志信息 3 mkdir -p /var/redis/7001 存放redis的持久化文件 4 5 配置文件中的改动: 6 7 port 7001 8 cluster-enabled yes -- 启用 cluster 集群 9 cluster-config-file /etc/redis-cluster/node-7001.conf 10 cluster-node-timeout 15000 11 daemonize yes 12 pidfile /var/run/redis_7001.pid 13 dir /var/redis/7001 14 logfile /var/log/redis/7001.log 15 bind 192.168.1.199 16 appendonly yes
17 #必须要关掉 slaveof 配置
在对应的每台机器下的/etc/init.d中,放2个对应端口号的启动脚本,分别为: redis_7001, redis_7002…需要注意的是每个启动脚本内,都一定要修改对应的端口号
我们需要安装官方提供的redis-trib.rb来完成集群的管理:
1 yum install -y ruby 2 yum install -y rubygems 3 gem install redis
第三步你的ruby版本太低会报错

请跳转 https://www.cnblogs.com/PatrickLiu/p/8454579.html
或者 https://www.cnblogs.com/carryping/p/7447823.html
将redis-trib.rb配置到环境变量:
cp /usr/local/redis-3.2.8/src/redis-trib.rb /usr/local/bin
执行如下命令:
redis-trib.rb create --replicas 1 192.168.1.199:7001 192.168.1.107:7002 192.168.1.104:7003 192.168.1.104:7004 192.168.1.105:7005 192.168.1.105:7006
replicas表示每个master对应的slave节点数量,后续为所有节点服务地址。成功执行后会自动将所有节点配置成集群架构模式,会自动有以下特点:
读写分离、master-slave高可用主备切换、横向master数据分片
可以通过以下命令来核查:
redis-trib.rb check 192.168.1.199:7001
之前我们所搭建的一主多从架构模式,是为来水平扩展,但是基于redis cluster本身的master就可以进行横向扩展,所以我们使用redis cluster架构模式,读写都在master即可,对应的slave节点主要是进行热备切换。并且,redis cluster默认是没有开启在slave节点上的读操作,需要执行readonly命令来开启,此外,jedis也会将请求都发送至master,需要重新封装或者修改源码来达到基于redis cluster的读写分离实现,所以也没有必要在redis cluster进行读写分离。

