google的pagerank算法原理
首先说说搜索引擎的原理
1 搜索引擎实际上是一个大规模的资料库,一个匹配算法,一个排序算法
2 大规模的资料库是通过全网爬虫抓取的,记录网页的url和网页的内容
3 匹配算法是把搜索的内容与网页的内容进行比较,返回符合匹配的内容
4 排序算法是把匹配的内容进行排序,把最符合的页面放在前面
pagerank算法和其它的算法一起决定了搜索页面的展示顺序。pagerank算法就是一种排序算法,用来计算每个页面的重要性,一般来说,指向它的页面越多,重要性越强,当然这不是决定因素。
假如,有四个页面要进行排序,把它们抽象成为一个个节点,连接的线代表当前页面存在链接指向目标页面。
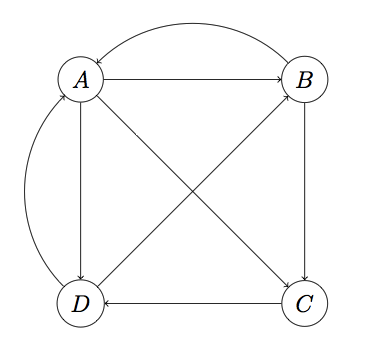
对于A页面来说它有3个链接,分别指向B,C,D,假定指向每个页面的概率是相同的,那么就是1/3,因此我们可以形成一个矩阵,用来反映页面i指向页面j的概率,M称为转移矩阵,第一行数据表示B,C,D页面指向A页面的概率
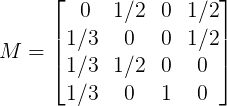
然后,对每个页面的初始概率进行设置,我们假定是随机访问的,因此每个页面的概率相同,因此页面rank为v
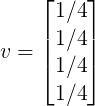
因此,用M乘以v就是页面A的最新rank的估计值
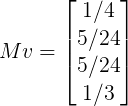
每一行代表最新的rank值,再把当前的rank值乘以转移矩阵,那么就会不断的迭代更新rank值,直到收敛,最终结果为(1/4,1/4,1/5,1/4)这就是最终的pagerank值。
基本的原理就是这样,但是会存在问题,比如,出现一个页面没有向外指向的链接,就是M矩阵的某一列全为0,那么随着迭代的进行,最终会出现这个页面的rank值为0,这种问题被称为dead ends
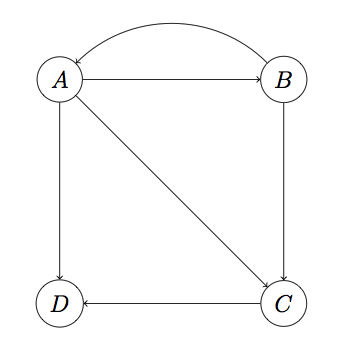
解决这种问题的方法是,迭代的拿掉一些没有向外指向的点,在例子中,首先拿掉D,然后C也是dead ends,再把C拿掉,剩下A和B没有dead ends计算各自的pagerank分别为1/2,然后再计算C的pagerank,1/3*1/2+1/2*1/2,因此C的pagerank为5/12,同理计算D的pagerank为1/2*1/3+5/12*1,D的pagerank为7/12,因此最终的pagerank为(1/2,1/2,5/12,7/12)
Spider Traps
在真实的世界中也存在一种状况就是页面只存在指向自己本身的链接,这种随着慢慢的迭代,会把其他的页面的值都变为0,而自己会逐渐增大变为1,这种问题称为spider Traps,如下图所示

D有外链所以不是Dead Ends,但是它只链向自己(注意链向自己也算外链,当然同时也是个内链)。这种节点叫做Spider Trap,如果对这个图进行计算,会发现D的rank越来越大趋近于1,而其它节点rank值几乎归零。
为了克服这种由于矩阵稀疏性和Spider Traps带来的问题,需要对PageRank计算方法进行一个平滑处理,具体做法是加入“心灵转移(teleporting)”。所谓心灵转移,就是我们认为在任何一个页面浏览的用户都有可能以一个极小的概率瞬间转移到另外一个随机页面。当然,这两个页面可能不存在超链接,因此不可能真的直接转移过去,心灵转移只是为了算法需要而强加的一种纯数学意义的概率数字。
加入心灵转移后,向量迭代公式变为:
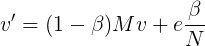
其中β往往被设置为一个比较小的参数(0.2或更小),e为N维单位向量,加入e的原因是这个公式的前半部分是向量,因此必须将β/N转为向量才能相加。这样,整个计算就变得平滑,因为每次迭代的结果除了依赖转移矩阵外,还依赖一个小概率的心灵转移。
以上图为例,转移矩阵M为:
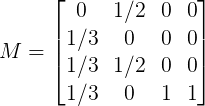
设β为0.2,则加权后的M为:
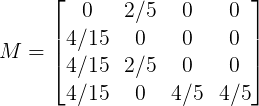
因此:
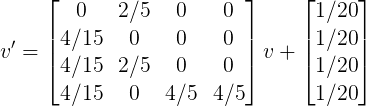
如果按这个公式迭代算下去,会发现Spider Traps的效应被抑制了,从而每个页面都拥有一个合理的pagerank。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号