

20200917-2 词频统计
此作业要求参见[https://edu.cnblogs.com/campus/nenu/2020Fall/homework/11206]
项目地址[https://github.com/talm966/wf]
本次作业coding地址[https://e.coding.net/talm/wf1/wf.git]
词频统计 SPEC
老五在寝室吹牛他熟读过《鲁滨逊漂流记》,在女生面前吹牛热爱《呼啸山庄》《简爱》和《飘》,在你面前说通读了《战争与和平》。但是,他的四级至今没过。你们几个私下商量,这几本大作的单词量怎么可能低于四级,大家听说你学习《构建之法》,一致推举你写个程序名字叫wf,统计英文作品的单词量并给出每个单词出现的次数,准备用于打脸老五。
希望实现以下效果。以下效果中数字纯属编造。
功能1 小文件输入。 为表明程序能跑,结果真实而不是迫害老五,请他亲自键
盘在控制台下输入命令。
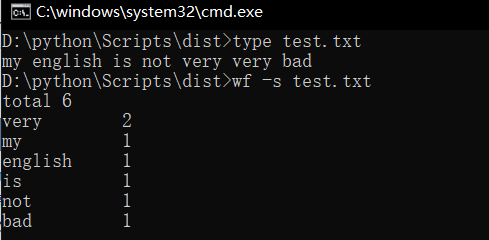
1 def function(name): 2 # 判断传入的命令行参数是否含有.txt,如果没有,要加上,再作为打开路径 3 a = '.txt' 4 if a in name: 5 path = name 6 else: 7 path = name + a 8 f = open(path, 'r', encoding='utf-8') # 用open()函数打开文件,并返回文件对象 9 # 通过正则表达式和findall()函数生成文件内容的列表 10 lists = findall(r'[a-z0-9^-]+', f.read().lower()) 11 12 words = Counter(lists) 13 # 遍历字典,统计键值对数 14 num = 0 15 for key, value in words.items(): 16 num += 1 17 # 判断功能1或者2选择输出words 18 if sys.argv[1] == '-s': 19 print('total' + ' ' + str(num)) 20 else: 21 print('total' + ' ' + str(num) + ' words') 22 # most_common(n)返回计数值最大的n个元素的元素列表 23 #most_common进行排序,选择位数5或者6的输出 24 if sys.argv[1] == '5': 25 maxwords = words.most_common() 26 count = 0 27 for i in maxwords: 28 if len(i[0]) == 5: 29 count += 1 30 print('%-8s%5d' % (i[0], i[1])) 31 if count == 10: 32 break 33 elif sys.argv[1] == '6': 34 maxwords = words.most_common() 35 count = 0 36 for i in maxwords: 37 if len(i[0]) == 6: 38 count += 1 39 print('%-8s%5d' % (i[0], i[1])) 40 if count == 15: 41 break 42 else: 43 maxwords = words.most_common(10) 44 for i in maxwords: 45 print('%-8s%5d' % (i[0], i[1]))
功能2 支持命令行输入英文作品的文件名,请老五亲自录入。
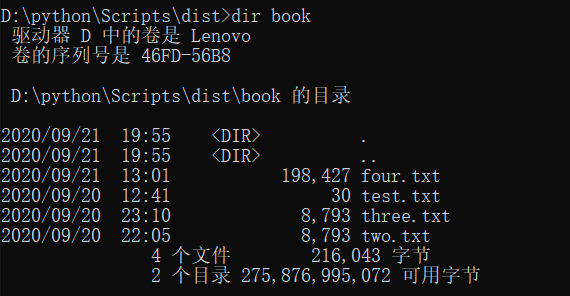
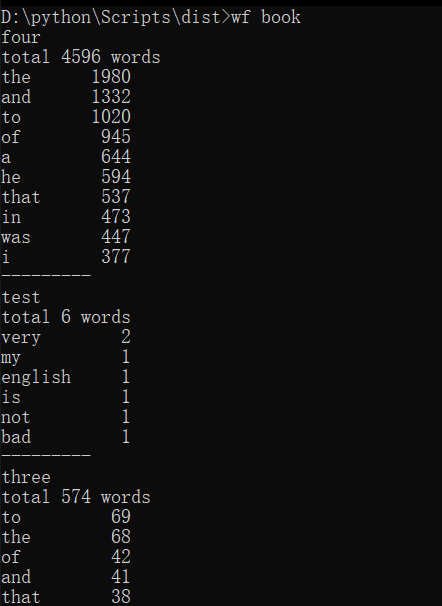
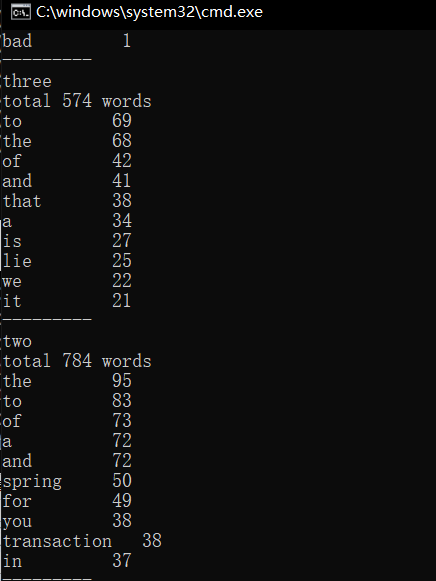
功能3 支持命令行输入存储有英文作品文件的目录名,批量统计。
关键代码:这里主要是现实文件夹中的txt,再逐个将列表里的txt输出。
1 # 传入文件夹 2 def listfunction(path): 3 files = os.listdir(path) # 将文件夹中的文件列表化 4 for file in files: 5 filename = os.path.splitext(file)[0] 6 print(filename) 7 function(file) 8 print('---------')
功能4 从控制台读入英文单篇作品,这不是为了打脸老五,而是为了向你女朋
友炫酷,表明你能提供更适合嵌入脚本中的作品(或者如她所说,不过是更灵活
的接口)。如果读不懂需求,请教师兄师姐,或者 bing: linux 重定向,尽管
这个功能在windows下也有,搜索关键词中加入linux有利于迅速找到。
功能还没有完善,只能实现向文件里重新输入文字。后期会慢慢改进。
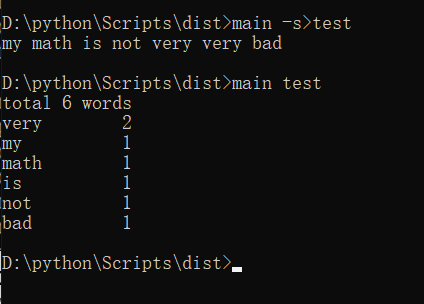
难点:没有完整的实现整个要求,只实现了一部分,就是重新写入txt.但是也只能在固定路径上输入。
1 def function_four(): 2 str=input() 3 4 filename = "D://python//Scripts//dist//test.txt" 5 with open(filename,"w") as f: 6 f.write(str) 7 file = 'test.txt' 8 function(file)
功能5 此功能为选做题,如果完成正确得30经验值,如果不做得0经验值,不会倒扣分数。
你完成了所有功能,后面的博客、PSP等也都精心准备了,去食堂的路上心情大悦。坐下挠了挠手机访问cnblogs上的班级,却发现大家的作业也都非常优秀,自己并不突出,心下黯然。怎么才能更加杰出呢?一抬头,看到老杨老师和和邹欣老师正坐桌对面吃饭,你说出了自己的困惑。
老杨说,“精益求精,一步步榨出自己的潜力来,正是走向杰出的开始啊。”
你说,“老师你具体点呗。”
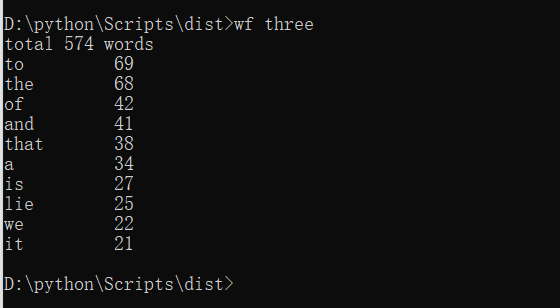
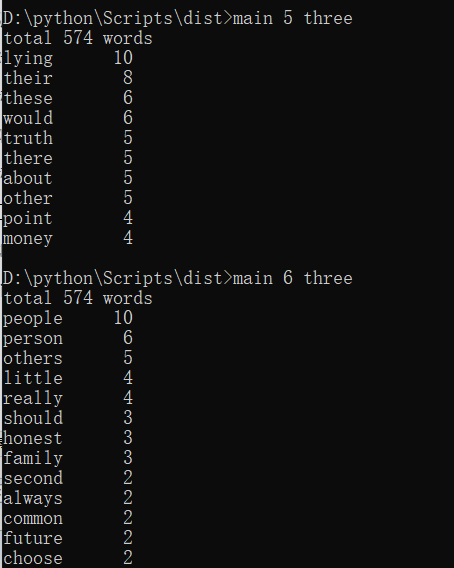
邹欣老师说,“这样,我想知道5个字母的单词中最频繁出现的是哪10个单词,top10,你怎么办呢?”
你一下就想到了,说了思路,应该blablabla。邹欣老师又问,“6个字母的单词中最频繁出现的是哪10个单词呢,top10?”
老杨追问,“6个字母的字母的单词中最频繁出现的是哪100个单词呢,top100?”
你问,“算法我想好了,性能估计也没问题,命令行参数老师怎么规定呢?”
老杨说,"你来规定,写个简单的文档,包括如何运行,给出运行实例的截图。"
"可变的参数就是(1)几个字母和(2)排行前多少是吧?没有问题。"
此时,你想起自己一直做作业还没有吃饭。肚子咕咕叫得声音如此之大,把你吵醒了。是赶紧去吃饭呢,还是做完这题再说?
功能实现
代码已经整合在功能一的函数里了。
难点:一开始思路有点问题,本来说只要查找五位数的单词,所以我想的是在正则化的时候加入长度匹配,但是一直不成功,后来干脆就在
most_common函数输出的排序里选择位数是5的来输出。这里6位是100太多了就没截取完整。
1 #most_common进行排序,选择位数5或者6的输出 2 if sys.argv[1] == '5': 3 maxwords = words.most_common() 4 count = 0 5 for i in maxwords: 6 if len(i[0]) == 5: 7 count += 1 8 print('%-8s%5d' % (i[0], i[1])) 9 if count == 10: 10 break 11 elif sys.argv[1] == '6': 12 maxwords = words.most_common() 13 count = 0 14 for i in maxwords: 15 if len(i[0]) == 6: 16 count += 1 17 print('%-8s%5d' % (i[0], i[1])) 18 if count == 15: 19 break
PSP
| 预计花费时间 | 实际花费时间 | 时间差距 | 原因 | |
| 功能1 | 60min | 120min | 60min | 一开始对于调用函数很不熟练 |
| 功能2 | 30min | 50min | 20min | 在功能1的基础上改进就快很多了,但是判断语句很不熟练 |
| 功能3 | 60min | 80min | 20min | 使用os模块的时候也不熟悉,慢慢摸索 |
| 功能4 | 50min | 120min | 70min | 在一块在看了很多重定向还是没有完整的实现,只能实现一小部分 |
| 功能5 | 30min | 56min | 26min | 本来以为挺简单的,但是在思路上出现了点错误 |
| 测试 | 30min | 67min | 37min | 在将py文件转化成exe文件时花费了很多时间 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号