redis的list是一个双向链表,既可以用作栈,也可以用作队列,幸好大学学过数据结构,还有印象。
栈:先进后出,队列:先进先出

redis链表操作:

应用场景学习list链表:要获取最新的10个登录用户信息, 如果用sql的话:select * from user order by logintime desc limit 10; 但是数据量大的话,这一条sql下去,这个表全部的数据都要收到影响,对数据库的负载比较高,必要情况还需要给关键字段(id或者logintime)设置索引,过多设置索引也是比较耗费系统资源的。
现在用redis的list来实现:只在list中保留5个数据,每次添加一个新的数据就删除一个旧的数据。每次都可以从链表中直接获取到需要的数据,极大的节省了各方面的资源。
1,启动redis的操作终端,切换到第二个数据库,该数据库为空:
 ,
,
2,lpush操作:执行命令lpush(l就是left的简写)命令向链表中添加5条数据,链表命名为 newlogin,表示新登录的用户,可以用type newlogin来查看newlogin的类型。

现在redis的第二个数据库里就有一个key 是 newlogin 的链表,里边依次保存了xiaoming、jack、jim、zhangsan、lisi 五条数据。

3,rpop操作:现在要再添加一条新数据,就从链表尾部删除一条数据,添加一个xiaoli,同时执行rpop(r是right的简写)从尾部删除第一个添加进去的数据(xiaoming):

4,llen、lrange操作:llen newlogin返回list的长度。lrange newlogin 0 4返回list对应范围的元素,如果最大下标超过了list的长度,也是返回所有的元素。

rpush是从尾部添加一个元素,lpop是从头部删除一个元素,rpush和lpop配合使用;lpush和rpop配合使用。
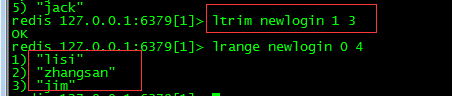
5,ltrim操作:截取list中的一部分元素: