
Windows集群安装(es版本7.10.1)
1.安装
1,解压elasticsearch-7.10.1-windows-x86_64.zip,复制出3个文件夹,重命名为node01、node02、node03
2,修改配置文件elasticsearch.yml
注意:7.10.1版本和之前集群配置不一样,在网上搜的可能是老版本配置会导致集群搭建失败
node01:
#集群名称,节点之间要保持一致
cluster.name: lhy-es
#节点名称,集群内要唯一
node.name: node-1
#http 端口
http.port: 9200
#ip 地址
network.host: 127.0.0.1
#tcp 监听端口
transport.tcp.port: 9300
#
#默认情况下,elasticsearch集群中每个节点都有成为主节点的资格,也都存储数据,还可以提供查询服务。
#这些功能是由两个属性控制的:node.master和node.data,默认情况下这两个属性的值都是true。
node.master: true
node.data: true
#
#主机发现,这里配置其他的节点主机名称或者IP,不需要配置自己这台主机的IP,只需要提供其他节点的IP或主机名
#例如: discovery.seed_hosts: ["192.168.0.128", "192.168.0.129", "192.168.0.130"]
discovery.seed_hosts: ["127.0.0.1:9301", "127.0.0.1:9302"]
#
# 可选选举为主节点的节点主机名
# 这里需要填入所有主机名称,这里填入了所有的节点
# 表示集群中任何一个节点都可以选举称为主节点
cluster.initial_master_nodes: ["127.0.0.1:9300", "127.0.0.1:9301", "127.0.0.1:9302"]
node02
#集群名称,节点之间要保持一致
cluster.name: lhy-es
#节点名称,集群内要唯一
node.name: node-2
#http 端口
http.port: 9201
#ip 地址
network.host: 127.0.0.1
#tcp 监听端口
transport.tcp.port: 9301
#
#默认情况下,elasticsearch集群中每个节点都有成为主节点的资格,也都存储数据,还可以提供查询服务。
#这些功能是由两个属性控制的:node.master和node.data,默认情况下这两个属性的值都是true。
node.master: true
node.data: true
#
#主机发现,这里配置其他的节点主机名称或者IP,不需要配置自己这台主机的IP,只需要提供其他节点的IP或主机名
#例如: discovery.seed_hosts: ["192.168.0.128", "192.168.0.129", "192.168.0.130"]
discovery.seed_hosts: ["127.0.0.1:9300", "127.0.0.1:9302"]
#
# 可选选举为主节点的节点主机名
# 这里需要填入所有主机名称,这里填入了所有的节点
# 表示集群中任何一个节点都可以选举称为主节点
cluster.initial_master_nodes: ["127.0.0.1:9300", "127.0.0.1:9301", "127.0.0.1:9302"]
node03
#集群名称,节点之间要保持一致
cluster.name: lhy-es
#节点名称,集群内要唯一
node.name: node-3
#http 端口
http.port: 9202
#ip 地址
network.host: 127.0.0.1
#tcp 监听端口
transport.tcp.port: 9302
#
#默认情况下,elasticsearch集群中每个节点都有成为主节点的资格,也都存储数据,还可以提供查询服务。
#这些功能是由两个属性控制的:node.master和node.data,默认情况下这两个属性的值都是true。
node.master: true
node.data: true
#
#主机发现,这里配置其他的节点主机名称或者IP,不需要配置自己这台主机的IP,只需要提供其他节点的IP或主机名
#例如: discovery.seed_hosts: ["192.168.0.128", "192.168.0.129", "192.168.0.130"]
discovery.seed_hosts: ["127.0.0.1:9300", "127.0.0.1:9301"]
#
# 可选选举为主节点的节点主机名
# 这里需要填入所有主机名称,这里填入了所有的节点
# 表示集群中任何一个节点都可以选举称为主节点
cluster.initial_master_nodes: ["127.0.0.1:9300", "127.0.0.1:9301", "127.0.0.1:9302"]
写一个启动脚本 start.bat
start D:\Z_lhy\ES\es-cluster\node01\bin\elasticsearch.bat
start D:\Z_lhy\ES\es-cluster\node02\bin\elasticsearch.bat
start D:\Z_lhy\ES\es-cluster\node03\bin\elasticsearch.bat
配置文件注意事项
**1. 集群名称cluster.name 和 节点名称node.name **
集群名称默认情况下集群名为elasticsearch,为了区分不同集群,在生产环境需要进行修改。每个节点需要配置相同的集群名才能加入同一个集群中,
节点名称默认情况下节点名称是操作系统的主机名,在Linux下使用hostname -f可查看主机名。也可通过elasticsearch.yml 配置文件显示的配置,使可读性更好。
2. 在单台windows上安装集群,http.port 和 transport.tcp.port 要修改的不一样。
3. node.master、node.data是elasticsearch节点的角色信息
默认情况下,elasticsearch集群中每个节点都有成为主节点的资格,也都存储数据,还可以提供查询服务。这些功能是由两个属性控制的。node.master和node.data默认情况下这两个属性的值都是true。
下面详细介绍一下这两个属性的含义以及不同组合可以达到的效果。
node.master:这个属性表示节点是否具有成为主节点的资格,注意:此属性的值为true,并不意味着这个节点就是主节点。因为真正的主节点,是由多个具有主节点资格的节点进行选举产生的。所以,这个属性只是代表这个节点是不是具有主节点选举资格。
node.data:这个属性表示节点是否存储数据。
这两个属性可以有四种组合:
● 第一种:主节点和数据节点的角色混合
■ node.master: true
■ node.data: true
这种组合表示这个节点即有成为主节点的资格,又存储数据,
这个时候如果某个节点被选举成为了真正的主节点,那么他还要存储数据,这样对于这个节点的压力就比较大了。
elasticsearch默认每个节点都是这样的配置,在测试环境下这样做没问题。实际工作中建议不要这样设置,
这样相当于主节点和数据节点的角色混合到一块了。
● 第二种:data(数据)节点
○ node.master: false
○ node.data: true
这种组合表示这个节点没有成为主节点的资格,也就不参与选举,只会存储数据。
这个节点我们称为data(数据)节点。在集群中需要单独设置几个这样的节点负责存储数据。后期提供存储和查询服务。
● 第三种:master节点
○ node.master: true
○ node.data: false
这种组合表示这个节点不会存储数据,有成为主节点的资格,可以参与选举,有可能成为真正的主节点。
这个节点我们称为master节点
● 第四种:client(客户端)节点
○ node.master: false
○ node.data: false
这种组合表示这个节点即不会成为主节点,也不会存储数据,
这个节点的意义是作为一个client(客户端)节点,主要是针对海量请求的时候可以进行负载均衡。
默认情况下,每个节点都有成为主节点的资格,也会存储数据,还会处理客户端的请求。
在一个生产集群中我们可以对这些节点的职责进行划分。
建议集群中设置3台以上的节点作为master节点【node.master: true node.data: false】
这些节点只负责成为主节点,维护整个集群的状态。
再根据数据量设置一批data节点【node.master: false node.data: true】
这些节点只负责存储数据,后期提供建立索引和查询索引的服务,这样的话如果用户请求比较频繁,这些节点的压力也会比较大
所以在集群中建议再设置一批client节点【node.master: false node.data: true】
这些节点只负责处理用户请求,实现请求转发,负载均衡等功能。
● master节点:普通服务器即可(CPU 内存 消耗一般) data节点:主要消耗磁盘,内存 client节点:普通服务器即可(如果要进行分组聚合操作的话,建议这个节点内存也分配多一点)
4.discovery.seed_hosts
主机发现,这里只配置其他的节点主机名称或者IP,不需要配置自己这台主机的IP,只需要提供其他节点的IP或主机名,配置方式有几种:
discovery.seed_hosts:
- 192.168.1.10:9300 ①
- 192.168.1.11 ②
- seeds.mydomain.com ③
- [2001:0db8:85a3:0000:0000:8a2e:0370:7334]:9300 ④
其中①直接指定主机ip和端口;
②指定了主机ip,使用默认的端口。默认端口的设置由transport.profiles.default.port和transport.port端口设置,前者优先级高于后者;
③指定了主机hostname,需要使用dns解析成ip地址,并使用默认端口;
④ip v6地址形式
本次安装是用一台机器,所以用带有端口好的配置方式。
5.cluster.initial_master_nodes:初始主节点是哪些
可选选举为主节点的节点主机名,这里需要填入所有主机名称,这里填入了所有的节点,表示集群中任何一个节点都可以选举称为主节点
当开启一个全新的集群时,会有一个集群的引导步骤,这步骤用来确定哪些节点参与第一次的主节点选举。在开发模式下,这个步骤由节点自动完成,这种模式本质上是不安全的,因为不是所有节点都适合做主节点,主节点关系到集群的稳定性。因此在生产模式下,集群第一次启动时,需要有一个适合作为主节点的节点列表,这个列表就是通过cluster.initial_master_nodes来配置,在配置中需要写出具体的节点名称,对应node.name配置项。配置示例如下
cluster.initial_master_nodes:
- master-node-a
- master-node-b
- master-node-c
6.本地实验,先不配置data和log目录。这两个配置的目录分别用来存放索引数据和日志,它们的默认路径位于$_ES_HOME的子文件夹内。这样有很大风险,特别是在升级Elasticsearch版本时,这些数据很可能被删除,在生产环境中可参考下面的配置
path: logs: /var/log/elasticsearch data: /var/data/elasticsearch
另外path.data支持配置多个目录,每个目录都会用来存放数据,但是单个分片会存放在同一个目录内,多目录配置参考
path: data:
- /mnt/elasticsearch_1
- /mnt/elasticsearch_2
- /mnt/elasticsearch_3
7.网络地址 network.host
启动验证
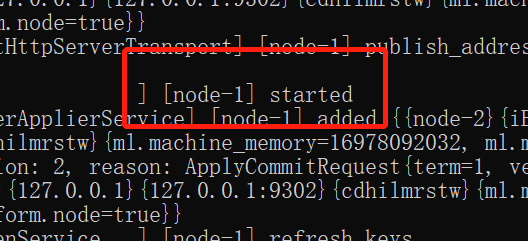
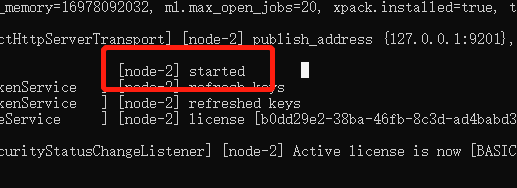
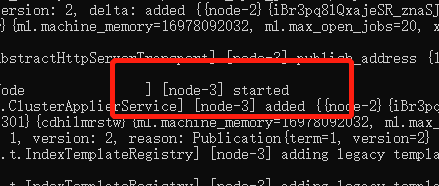
运行批处理文件 startup.bat,启动集群,看到nodeX started 启动成功
用Header插件看
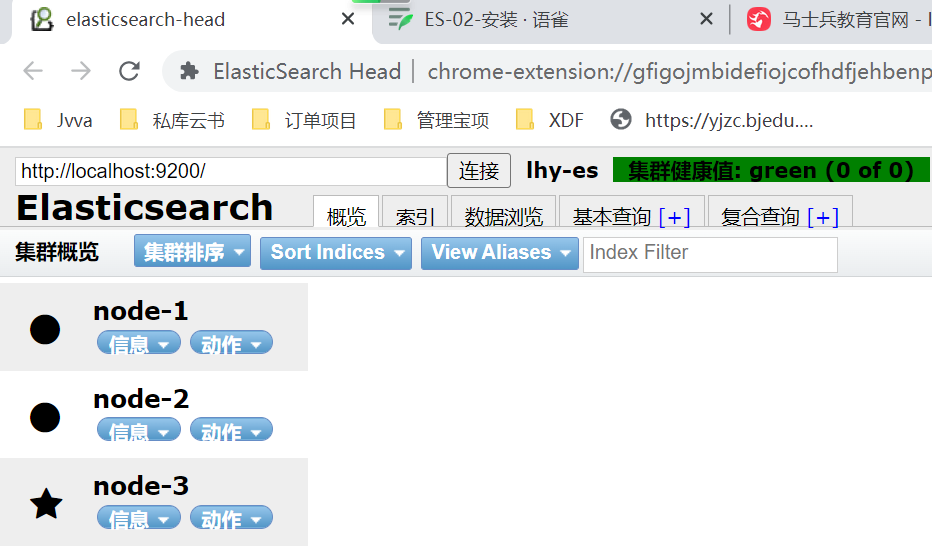
由于此时节点中一个索引都还没有,所以它的健康值是green (0 of 0).
2.Elasticsearch集群架构介绍
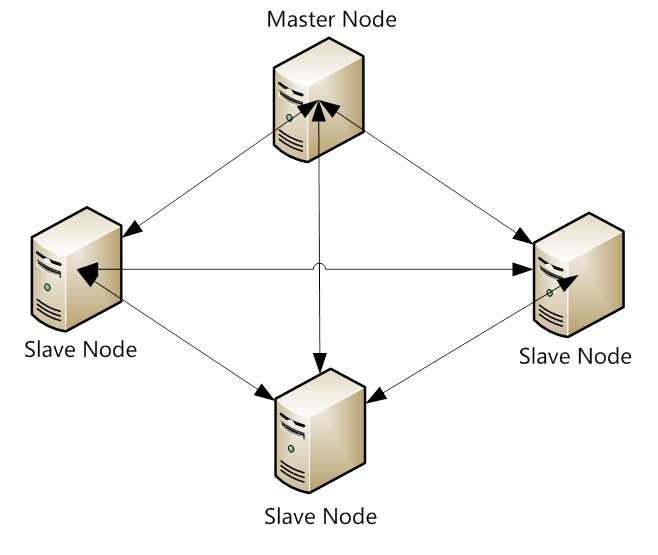
对于用户来说, ES是一个无中心化的集群,ES集群内部运行原理是对外面来说是透明的。你操作一个节点跟操作一个集群是一样的。也就是说,ES集群没有中心节点,任何一个节点出现故障都不会影响其它节点。这是由ES本身特性所决定的。这是它的典型特征。但是通过集群内部来看ES是有节点的。
在ElasticSearch的架构中,有三类角色,分别是Client Node、Data Node和Master Node,搜索查询的请求一般是经过Client Node来向Data Node获取数据,而索引查询首先请求Master Node节点,然后Master Node将请求分配到多个Data Node节点完成一次索引查询。
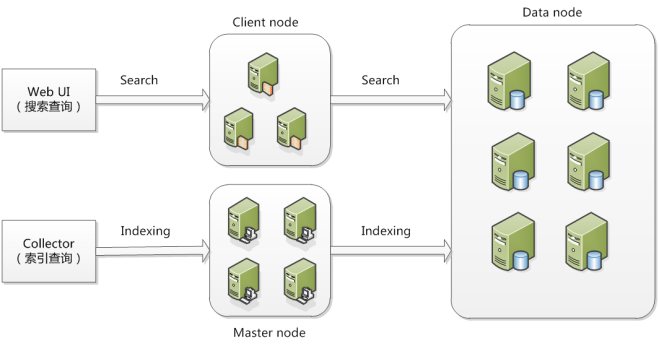
Master Node:可以理解为主节点,用于元数据(metadata)的处理,比如索引的新增、删除、分片分配等,以及管理集群各个节点的状态包括集群节点的协调、调度。elasticsearch集群中可以定义多个主节点,但是,在同一时刻,只有一个主节点起作用,其它定义的主节点,是作为主节点的候选节点存在。当一个主节点故障后,集群会从候选主节点中选举出新的主节点。也就是说,主节点的产生都是由选举产生的。Master节点它仅仅是对索引的管理、集群状态的管理。像其它的对数据的存储、查询都不需要经过这个Master节点。因此在ES集群中。它的压力是比较小的。所以,我们在构建ES的集群当中,Master节点可以不用选择太好的配置,但是我们一定要保证服务器的安全性。因此,必须要保证主节点的稳定性。
Data Node: 存储数据的节点,数据的读取、写入最终的作用都会落到这个上面。数据的分片、搜索、整合等 这些操作都会在数据节点来完成。因此,数据节点的操作都是比较消耗CPU、内存、I/O资源。所以,我们在选择data Node数据节点的时候,硬件配置一定要高一些。高的硬件配置可以获得高效的存储和分析能力。因为最终的结果都是需要到这个节点上来。
Client Node:可选节点。作任务分发使用。它也会存储一些元数据信息,但是不会对数据做任何修改,仅仅用来存储。它的好处是可以分担datanode的一部分压力。因为ES查询是两层汇聚的结果,第一层是在datanode上做查询结果的汇聚。然后把结果发送到client Node 上来。Cllient Node收到结果后会再做第二次的结果汇聚。然后client会把最终的结果返回给用户。
那么从上面的结构图我们可以看到ES集群的工作流程:
1,搜索查询,比如Kibana去查询ES的时候,默认走的是Client Node。然后由Client Node将请求转发到datanode上。datanode上的结构返回给client Node.然后再返回给客户端。
2,索引查询,比如我们调用API去查询的时候,走的是MasterNode,然后由master 将请求转发到相应的数据节点上,然后再由Master将结果返回。
3,最终我们都知道,所有的服务请求都到了datanode上。所以,它的压力是最大的。
集群节点角色
每个节点就是一个Elasticsearch的实例,一个节点≠一台服务器
● master:候选节点
● data:数据节点
● data_content:数据内容节点
● data_hot:热节点
● data_warm:索引不再定期更新,但仍可查询
● data_code:冷节点,只读索引
● Ingest:预处理节点,作用类似于Logstash中的Filter
● ml:机器学习节点
● remote_cluster_client:候选客户端节点
● transform:转换节点
● voting_only:仅投票节点
主节点(Master node)
● 负责集群层面的相关操作,管理集群变更,如创建或删除索引,跟踪哪些节点是群集的一部分,并决定哪些分片分配给相关的节点。
● 主节点也可以作为数据节点
● 主节点是全局唯一的,将从有资格成为Master的节点中选举,通过配置node.master:true(默认)使节点具有被选举为Master的资格。
○ node.master:true
○ node.data:false
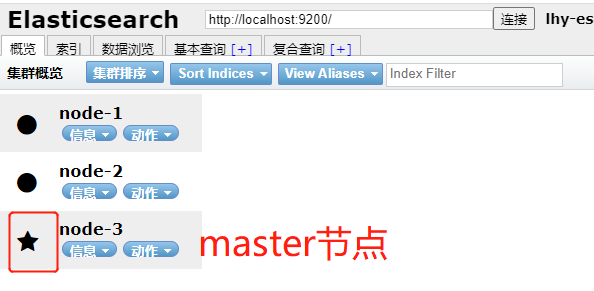
数据节点
● 数据节点主要是存储索引数据的节点,执行数据相关操作:CRUD、搜索,聚合操作等。数据节点对cpu,内存,I/O要求较高, 在优化的时候需要监控数据节点的状态,当资源不够的时候,需要在集群中添加新的节点。
● 通过配置node.data:true(默认)
○ node.master:false
○ node.data:true
○ node.ingest:false
预处理节点
预处理操作运行在索引文档之前,即写入数据之前,通过事先定义好的一系列processors(处理器)和pipeline(管道),对数据进行某种转换、富化。processors和pipeline拦截bulk和index请求,在应用相关操作后将文档传回给index或bulk API。
默认情况下,在所有的节点启用ingest。如果想在某个节点上禁用ingest,则可以田间配置node.ingest:false,也可以通过下面的配置创建一个仅用于预处理的节点:
○ node.master:false
○ node.data:false
○ node.ingest:true
数据分片
● 一个索引包含一个或多个分片,在7.0之前默认五个主分片,每个主分片一个副本;在7.0之后默认一个主分片。副本可以在索引创建之后修改数量,但是主分片的数量一旦确定不可修改,只能创建索引
● 每个分片都是一个Lucene实例,有完整的创建索引和处理请求的能力
● ES会自动再nodes上做分片均衡
● 一个doc不可能同时存在于多个主分片中,但是当每个主分片的副本数量不为一时,可以同时存在于多个副本中。
● 每个主分片和其副本分片不能同时存在于同一个节点上,所以最低的可用配置是两个节点互为主备。
实验
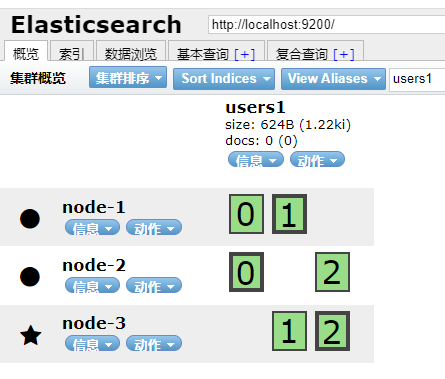
1,新建一个3个分片,每个分片有1个副本的索引
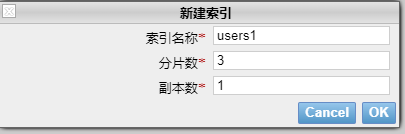
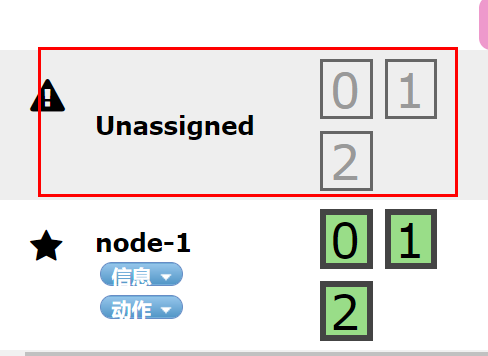
五角星代表是Master节点,数字外粗边框【1】代表是主分片,细边框代表是副本分片
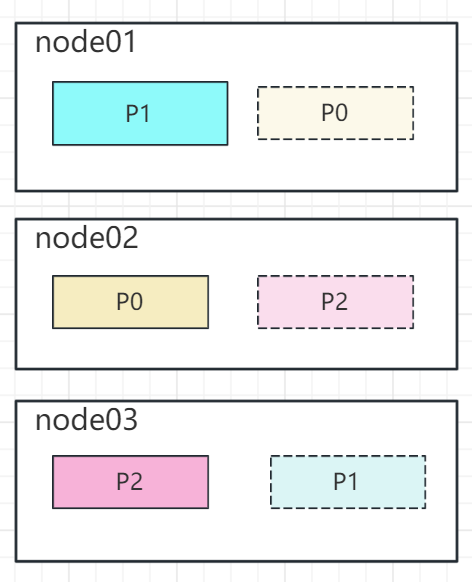
每个节点内数据分布如下:
2,新建一个2个分片,每个分片2个副本的索引
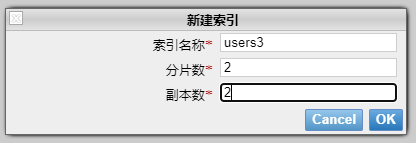
node03是Master节点,两个分片【0】【1】,每个分片除了自己,有两个副本,分散在其他节点。

集群的健康值检查
shopping有 3 个主分片,0个副本,都被分配在 node-1 ,绿色表示主分片和副本分片都健康。
集群健康状况:

(1) 健康值状态
① Green:所有Primary和Replica均为active,集群健康
② Yellow:至少一个Replica不可用,但是所有Primary均为active,数据仍然是可以保证完整性的。
③ Red:至少有一个Primary为不可用状态,数据不完整,集群不可用。
(2) 健康值检查
① _cat/health?v
② _cluster/health
primary shard:主分片,每个文档都存储在一个分片中,当你存储一个文档的时候,系统会首先存储在主分片中,然后会复制到不同的副本中。你可以在事先制定分片的数量,当分片一旦建立,分片的数量则不能修改。
replica shard:副本分片,每一个分片有零个或多个副本。副本主要是主分片的复制,可以 增加高可用性,提高性能。
默认情况下,一个主分配有一个副本,但副本的数量可以在后面动态的配置增加。
副本必须部署在不同的节点上,不能部署在和主分片相同的节点上。
实践
http://localhost:9200/_cat/health?v

含义如下:
前两个是时间戳,不过多介绍。其余如下:
cluster ,集群名称
status,集群状态 green代表健康;yellow代表分配了所有主分片,但至少缺少一个副本,此时集群数据仍旧完整;red代表部分主分片不可用,可能已经丢失数据。
node.total,代表在线的节点总数量
node.data,代表在线的数据节点的数量
shards, active_shards 存活的分片数量
pri,active_primary_shards 存活的主分片数量 正常情况下 shards的数量是pri的两倍。
relo, relocating_shards 迁移中的分片数量,正常情况为 0
init, initializing_shards 初始化中的分片数量 正常情况为 0
unassign, unassigned_shards 未分配的分片 正常情况为 0
pending_tasks,准备中的任务,任务指迁移分片等 正常情况为 0
max_task_wait_time,任务最长等待时间
active_shards_percent,正常分片百分比 正常情况为 100%
集群状态查询GET _cluster/health

{
"cluster_name" : "lhy-es",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 3,
"number_of_data_nodes" : 3,
"active_primary_shards" : 6, #集群中的主分片数量
"active_shards" : 12,#所有索引的所有分片的汇总值,即包括副本分片。
"relocating_shards" : 0,#当前正在从一个节点迁往其他节点的分片的数量
"initializing_shards" : 0,#刚刚创建的分片的个数
"unassigned_shards" : 0,#是已经在集群状态中存在的分片,但是实际在集群里又找不着
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
