
1,字典表Or枚举类?
项目里有很多标识状态的字段,比如订单状态:0-未支付,1-已支付,2-已取消。或者性别sex: 0-未知,1-男,2-女 。等等。一般这种我们都会建相应的枚举类,比如性别枚举:
public enum SexEnum {
UNKNOWN(0,"未知"),
MAN(1,"男"),
WOMAN(2,"女");
private final int code;
private final String text;
SexEnum(int code, String text) {
this.code = code;
this.text = text;
}
//省略getter方法
}
项目里一般都有字典表,我们写了枚举类,还需要把他们存在字典表么?
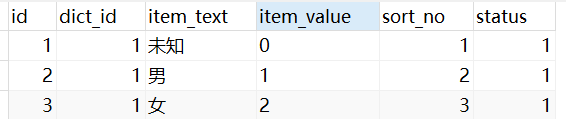
以前我也没搞清楚,现在清楚了。存字典表里,可以用AOP进行统一字典翻译。比如你返回给前端一个分页列表,列表有sex字段,你就需要在接口文档写上:sex(0-未知,1-男,2-女)。像性别这种还好,一般不会再新增状态。但是其他类型字段,以后再增加一种类型,接口文档就要改,前端代码也要改。但是如果后端返回列表时,把这些字段都给前端翻译好,即使以后再增加类型,前端直接展示,就不用改代码了。比如返回的列表里,遇到这种类型值的,比如以前返回sex=1,现在返回俩字段:sex=1, sex_text=男,前端直接拿到sex_text做展示即可。
有了字典,还需要枚举类或者常量类么?需要的。因为你的代码里,常常是需要关于sex类型的判断的,比如:
if(SexEnum.MAN.getCode() == user.getSex()){
//do something
}
这就需要在代码里再维护一份和字典一样的常量或枚举。至于用枚举还是常量类,无所谓。
2.AOP翻译字典表
一个注解:
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
/**
* 字典
* create by lihaoyang on 2020/10/28
*/
@Target(ElementType.FIELD)
@Retention(RetentionPolicy.RUNTIME)
public @interface Dict {
/**
* 数据字典code
* @return
*/
String dictCode();
}
注解标在实体类属性上:
/**
* 性别(0-默认未知,1-男,2-女)
*/
@Dict(dictCode = "sex")
private Integer sex;
一个切面类:
import com.alibaba.fastjson.JSONObject;
import com.baomidou.mybatisplus.core.metadata.IPage;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.nb.nbbase2.beans.Result;
import com.nb.nbbase2.constant.SysConstant;
import com.nb.nbbase2.service.SysDictService;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.ArrayUtils;
import org.apache.commons.lang3.StringUtils;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Pointcut;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.AnnotationConfigUtils;
import org.springframework.core.annotation.AnnotationUtils;
import org.springframework.stereotype.Component;
import java.lang.annotation.Annotation;
import java.lang.reflect.Field;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
/**
* 字典aop类
* create by lihaoyang on 2020/10/28
*/
@Slf4j
@Aspect //标识该类是一个切面
@Component
public class DictAspect {
@Autowired
private SysDictService sysDictService;
@Autowired
private ObjectMapper objectMapper;
//切入点
@Pointcut("execution(public * com.nb.nbbase2.*.*Controller.*(..))")
public void dictPointCut() {
}
@Around("dictPointCut()")
public Object around(ProceedingJoinPoint point) throws Throwable {
Object result = point.proceed();
long start=System.currentTimeMillis();
//解析字典
this.parseDictText(result);
long end=System.currentTimeMillis();
log.debug("AOP解析字典耗时{}ms",(end-start));
return result;
}
/**
* 解析字典
* @param result
*/
private void parseDictText(Object result) {
//如果control返回的是Result对象
if(result instanceof Result){
//如果是分页, TODO:是不是也可以处理不分页的list??或者单个对象?道理一样,这里就不写了
if(((Result) result).getResult() instanceof IPage){
//存放字典转换加工处理后的结果列表
List<JSONObject> items = new ArrayList<>();
IPage iPage = (IPage) ((Result) result).getResult();
//遍历分页列表,
for(Object record : iPage.getRecords()){
//解决@JsonFormat注解解析不了的问题,这个我没实验,先这样吧!
//一行数据的json:如{"sex":1,"id":9,"userType":3,"email":"ttrrr@qq.com","username":"admin后台","status":0}
String json = null;
try {
json = objectMapper.writeValueAsString(record);
} catch (JsonProcessingException e) {
log.error("翻译字典json解析失败:"+e.getMessage(),e);
}
//存放加工处理后的一行数据,准备往里头加字段text用
JSONObject itemObj = JSONObject.parseObject(json);
System.err.println("对象==========> "+itemObj.toJSONString());
//反射获取到所有属性
for(Field field : getAllFields(record)){
Dict dict = field.getAnnotation(Dict.class);
if(dict != null){
//获取实体类成员变量上的@Dict注解的dictCode值 比如@Dict(dictCode = "sex")
String dictCode = dict.dictCode();
//获取属性的值,比如sex=1
String filedValue = String.valueOf(itemObj.get(field.getName()));
//翻译字典,加_text
String itemText = convertDictValue2Text(dictCode,filedValue);
itemObj.put(field.getName()+ SysConstant.DICT_LABEL_SUFFIX,itemText);
//date类型默认转换string格式化日期
//if (field.getType().getName().equals("java.util.Date")&&field.getAnnotation(JsonFormat.class)==null&&item.get(field.getName())!=null){
// SimpleDateFormat aDate=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
// item.put(field.getName(), aDate.format(new Date((Long) item.get(field.getName()))));
//}
}
}
items.add(itemObj);
}
//////set给分页////
iPage.setRecords(items);
}
}
}
/**
* 根据字典code和字典值,转换为字典text文本
* @param dictCode 字典表code 比如sex
* @param dictValue 字典项value 比如男=1
* @return
*/
private String convertDictValue2Text(String dictCode,String dictValue){
if(StringUtils.isEmpty(dictValue)){
return null;
}
StringBuilder dictText = new StringBuilder();
//可能一个字段存多个字典值,比如:允许性别字段(1,2)男女都允许,逗号分隔的,这里需要分隔一下,循环处理。
//如果没有一个字典存多个字典的需求,直接用一次查询翻译就好了??
String[] dictValueArr = dictValue.split(",");
if(ArrayUtils.isNotEmpty(dictValueArr)){
for(String dictVal : dictValueArr){
String text = null;
if(dictVal.trim().length() != 0){
text = sysDictService.findTextByCodeAndDictItemValue(dictCode,dictVal);
}
if(text != null){
if(!"".equals(dictText.toString())){
dictText.append(",");
}
dictText.append(text);
}
}
}
return dictText.toString();
}
/**
* 获取类的所有属性,包括父类
*
* @param object
* @return
*/
public static Field[] getAllFields(Object object) {
Class<?> clazz = object.getClass();
List<Field> fieldList = new ArrayList<>();
while (clazz != null) {
fieldList.addAll(new ArrayList<>(Arrays.asList(clazz.getDeclaredFields())));
//对于继承的对象,父类的属性也得获取一下
clazz = clazz.getSuperclass();
}
Field[] fields = new Field[fieldList.size()];
fieldList.toArray(fields);
return fields;
}
}
查询用户列表,返回json效果:
{
"message":"成功",
"code":200,
"result":{
"records":[
{
"userType_text":"学生",
"sex_text":"未知",
"sex":0,
"allowSex_text":"男,女",
"id":6,
"userType":2,
"status_text":"启用",
"allowSex":"1,2",
"email":"asd@qq.com",
"username":"张三",
"status":1
},
{
"userType_text":"学生",
"sex_text":"男",
"sex":1,
"allowSex_text":"男",
"id":7,
"userType":2,
"status_text":"启用",
"allowSex":"1,",
"email":"dsasd@qq.com",
"username":"李四",
"status":1
},
{
"userType_text":"老师",
"sex_text":"未知",
"sex":0,
"allowSex_text":"男",
"id":8,
"userType":1,
"status_text":"启用",
"allowSex":"1",
"email":"gfdsa@qq.com",
"username":"张老师",
"status":1
},
{
"userType_text":"管理员",
"sex_text":"男",
"sex":1,
"allowSex_text":"男,女",
"id":9,
"userType":3,
"status_text":"禁用",
"allowSex":"1,2",
"email":"ttrrr@qq.com",
"username":"admin后台",
"status":0
}
],
"total":4,
"size":10,
"current":1,
"orders":[
],
"optimizeCountSql":true,
"hitCount":false,
"searchCount":true,
"pages":1
},
"timestamp":1605668907169
}
可以看到,性别sex、用户状态status、用户类型userType 都对应多了一个_text结尾的翻译字段。
对于字典表,可以存到redis缓存起来:
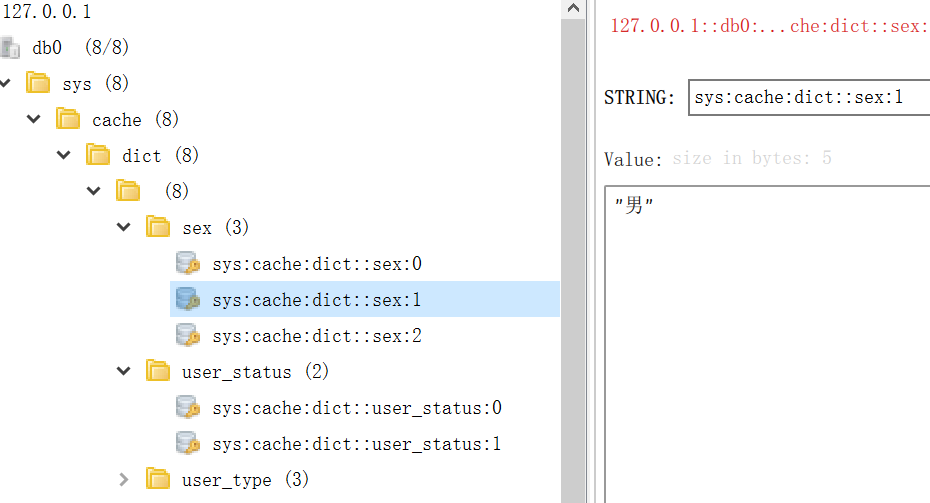
字典表Service,会自动缓存到redis
@Cacheable(value = SysConstant.SYS_DICT_CACHE,key = "#dictCode+':'+#dictItemValue")
@Override
public String findTextByCodeAndDictItemValue(String dictCode, String dictItemValue) {
log.info("字典查库,dictCode {} ,dictValue:{}",dictCode,dictItemValue);
return sysDictMapper.findTextByCodeAndDictItemValue(dictCode,dictItemValue);
}
当新增或修改字典的时候用
@CacheEvict(value=SysConstant.SYS_DICT_CACHE, allEntries=true)//也可以夹在service方法
注解会删除缓存数据
@RequestMapping(value = "/edit", method = RequestMethod.POST)
@CacheEvict(value=SysConstant.SYS_DICT_CACHE, allEntries=true)//也可以夹在service方法
public Result<SysDictItem> edit(@RequestBody SysDictItem sysDictItem) {
Result<SysDictItem> result = new Result<SysDictItem>();
SysDictItem sysDict = sysDictItemService.getById(sysDictItem.getId());
if(sysDict==null) {
result.error500("未找到对应实体");
}else {
boolean ok = sysDictItemService.updateById(sysDictItem);
if(ok) {
result.success("编辑成功!");
}
}
return result;
}
public class SysConstant {
//字典后后缀
public static final String DICT_LABEL_SUFFIX ="_text";
/**
* 字典信息缓存
*/
public static final String SYS_DICT_CACHE = "sys:cache:dict";
/**
* 测试缓存key
*/
public static final String TEST_DEMO_CACHE = "test:demo";
}
mybatis-plus的通用枚举:听同事说他们以前用mybatis-plus的枚举,多么多么好用,看了一下,这么搞得:
实体类属性类型直接是你的枚举类:教师职称
/**
* 职称(引用字典表)
* 原生枚举(带{@link com.baomidou.mybatisplus.annotation.EnumValue}):
*/
private TeacherTitleEnum title;
教师职称枚举类:
import com.baomidou.mybatisplus.annotation.EnumValue;
import com.fasterxml.jackson.annotation.JsonValue;
/**
* 教师职称
* @author lihaoyang
* @date 2020/11/12
*/
public enum TeacherTitleEnum {
ZHUJIAO(1, "助教"),
JIANGSHI(2, "讲师"),
FUJIAOSHOU(3, "副教授"),
JIAOSHOU(4,"教授");
@EnumValue//标记数据库存的值是code
private final int code;
private final String desc;
TeacherTitleEnum(int code, String desc) {
this.code = code;
this.desc = desc;
}
public int getCode() {
return code;
}
@JsonValue //标记响应json值
public String getDesc() {
return desc;
}
}
测试:
@Test
public void insert(){
// SysTeacher teacher = new SysTeacher();
// teacher.setTeacherName("小羊");
// teacher.setTitle(TeacherTitleEnum.FUJIAOSHOU);
// teacherMapper.insert(teacher);
List<SysTeacher> list = teacherMapper.selectList(null);
for (SysTeacher tea : list) {
System.err.println(JSONObject.toJSONString(tea));
}
}
////打印:
//
// {"id":1,"teacherName":"牛贝","title":"JIANGSHI"}
// {"id":2,"teacherName":"西决","title":"ZHUJIAO"}
// {"id":3,"teacherName":"石竹","title":"FUJIAOSHOU"}
// {"id":4,"teacherName":"樟树鱼","title":"JIAOSHOU"}
// {"id":5,"teacherName":"小羊","title":"FUJIAOSHOU"}
// {"id":6,"teacherName":"小羊","title":"FUJIAOSHOU"}
// {"id":7,"teacherName":"小羊","title":"FUJIAOSHOU"}
// {"id":8,"teacherName":"小羊","title":"FUJIAOSHOU"}
// {"id":9,"teacherName":"小羊","title":"FUJIAOSHOU"}
他并没有把枚举的汉字描述翻译出来,而是把枚举的变量值翻译出来了。前端拿到怎么处理??
完整代码:https://github.com/lhy1234/Project-Practice/tree/master/aop_dict
欢迎关注个人公众号交流学习:


