《机器学习十讲》第四讲
源地址(相关案例在视频下方):http://cookdata.cn/auditorium/course_room/10015/
《机器学习十讲》——第四讲(模型提升)
本讲主要讲了三个算法:决策树,随机森林,AdaBoost
模型误差的来源

非线性模型
线性回归:多项式回归
支持向量机:给定的核函数组合,基本属于“猜测”
决策树:空间划分的思想来处理非线性数据
深度学习
感知机:线性回归+简单的非线性映射
多层感知机:多层神经元的组合,多个简单非线性函数的复合
深度学习:层数很大
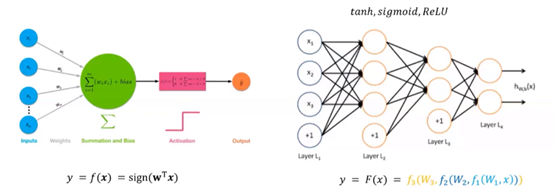
sign:神经元
结合上面估计误差那张图来看,深度学习可以“拓宽”估计误差范围,更容易找到适合的f。
模型集成
思路:训练多个弱模型,组合成一个“强”模型。
为什么可以提高效果:增强模型的表达能力;降低误差(概率角度)。
模型介绍
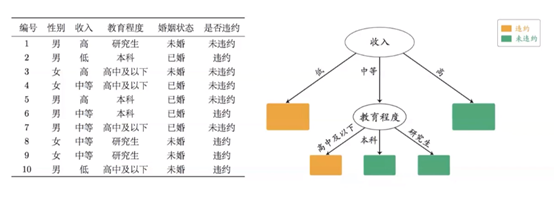
决策树:
把问题问到点子上。(如银行放贷决策)
空间的方块划分(优化目标:每个空间的不纯度越低越好):
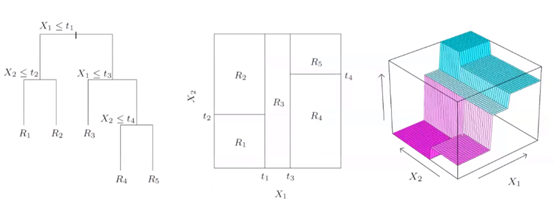
决策树生成:从根节点开始选择节点对应特征(如年龄…);选择节点特征分割点,根据分割点分裂节点(如年龄50)。
核心问题:如何选择节点属性和属性分割点。
概念引入——不纯度:
定义:表示落在当前节点的样本类别分布的均衡程度。
说明:节点分裂后,节点不纯度应该更低(类分布更不均衡);选择特征及对应的分割点,使得分裂前后的不纯度下降最大。
不纯度度量方法:
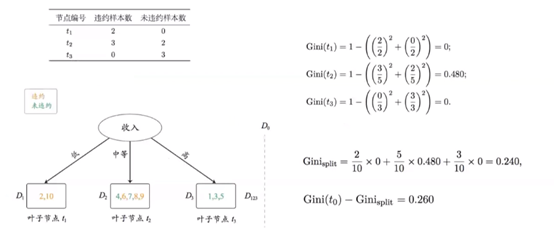
Gini指数:

计算示例:
信息熵:

误分率:
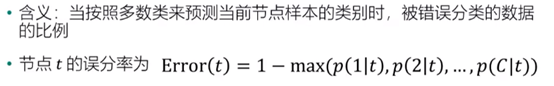
三种度量方法的图示比较:
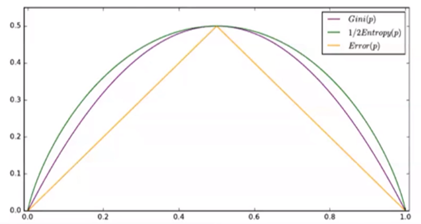
可以看到Gini指数和信息熵更平滑一些。
决策树中可以使用叶子节点来做预测。
随机森林:
Bagging算法(典型):“随机”是核心,“森林”指组合多组决策树来构建模型。
主要特点:对样本进行有放回抽样;对特征进行随机抽样。
算法流程:

算法分析:
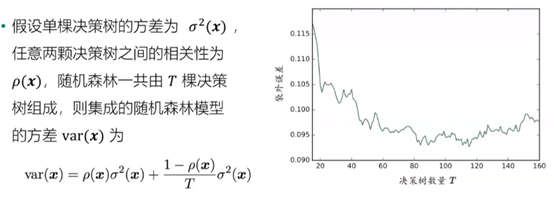
可以理解为随机抽取样本减少数据集的相关性。
在随机森林中每组数据集都是独立的,可变形的,更加灵活(如可使用多台电脑进行不同的数据集分析)
AdaBoost:
基本思想:通过改变样本权重串行地训练多个基分类器,每个基分类器带权重样本集下进行训练,根据其在训练样本中的加权误差来确定基分类器模型的权重,后一个分类器更加关注前一个分类器分错的样本。
算法流程:

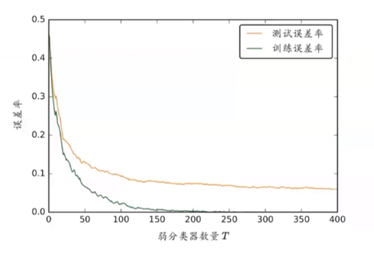
算法优点:不容易过度拟合。因为理论上随着弱分类器数目T的增大,泛化误差上界会增大。如图所示:
实例:三种模型的实现

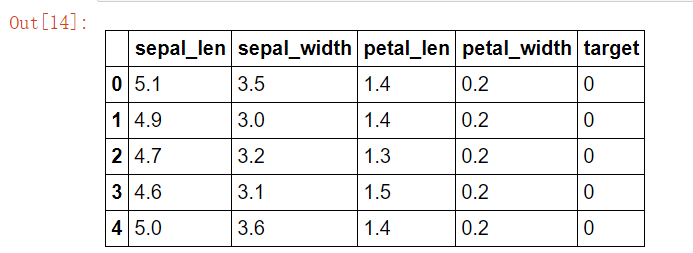
#使用python实现分类决策树 ##使用鸢尾花数据实现,该数据从sklearn.datasets中导入 from sklearn.datasets import load_iris import pandas as pd iris = load_iris() iris_df = pd.DataFrame(data=iris.data,columns=iris.feature_names) iris_df["target"] = iris.target iris_df.head() iris_df.columns = ["sepal_len","sepal_width","petal_len","petal_width","target"] X_iris = iris_df.iloc[:,:-1] y_iris = iris_df["target"] #打印前五行 iris_df.head()
#创建决策树节点
class TreeNode:
def __init__(self,x_pos,y_pos,layer,class_labels=[0,1,2]):
self.f = None #当前节点的切分特征
self.v = None #当前节点的切分点
self.left = None #左儿子节点
self.right = None #右儿子节点
self.pos = (x_pos,y_pos) # 节点坐标,可视化用
self.label_dist = None #当前节点样本的类分布
self.layer = layer #用于限制树的高度
self.class_labels = class_labels
def __str__(self): #打印节点信息,可视化时的节点标签
if self.f != None:
return self.f + "\n<=" + str(round(self.v,2))
else:
return str(self.label_dist) + "\n(" + str(np.sum(self.label_dist)) + ")"
决策树的不纯度度量已经介绍了三种方法,本次使用Gini指数:

#定义一个函数计算基尼系数
import numpy as np
def gini(y):
return 1 - np.square(y.value_counts()/len(y)).sum()
#测试写好的基尼系数函数 import pandas as pd gini(pd.Series([1,1,-1,-1,1])) #正确输出结果应为0.48

编写好后开始生成分类决策树
#生成分类决策树
##根据上述步骤进行递归生成左右节点。
def generate(X,y,x_pos,y_pos,nodes,min_leaf_samples,max_depth,layer,class_labels):
current_node = TreeNode(x_pos,y_pos,layer,class_labels)#创建节点对象
current_node.label_dist = [len(y[y==v]) for v in class_labels] #当前节点类样本分布
nodes.append(current_node)
if(len(X) < min_leaf_samples or gini(y) < 0.1 or layer > max_depth): #判断是否需要生成子节点
return current_node
max_gini,best_f,best_v = 0,None,None
for f in X.columns: #特征遍历
for v in X[f].unique(): #取值遍历
y1,y2 = y[X[f] <= v],y[X[f] > v]
if (len(y1) >= min_leaf_samples and len(y2) >= min_leaf_samples):
imp_descent = gini(y) - gini(y1)*len(y1)/len(y) - gini(y2)*len(y2)/len(y) # 计算不纯度变化
if imp_descent > max_gini:
max_gini,best_f,best_v = imp_descent,f,v
current_node.f,current_node.v = best_f,best_v
if(current_node.f != None):
current_node.left = generate(X[X[best_f] <= best_v],y[X[best_f] <= best_v],x_pos-(2**(max_depth-layer)),y_pos -1,nodes,min_leaf_samples,max_depth,layer + 1,class_labels)
current_node.right = generate(X[X[best_f] > best_v],y[X[best_f] > best_v],x_pos+ (2**(max_depth-layer)),y_pos -1,nodes,min_leaf_samples,max_depth,layer + 1,class_labels)
return current_node
#封装一个函数,用于输入训练数据,叶子节点的最小样本数和树的最大深度。返回为树的根,节点的集合。
def decision_tree_classifier(X,y,min_leaf_samples,max_depth):
nodes = []
root = generate(X,y,0,0,nodes,min_leaf_samples=min_leaf_samples,max_depth=max_depth,layer=1,class_labels=y.unique())
return root,nodes
为了方便查看我们需要对决策树进行可视化,这里使用Networkx进行可视化。
#使用Networkx将决策树可视化
##编写函数,将训练得到的决策树转换成Networkx中的网络对象 G。
def get_networkx_graph(G, root):
if root.left != None:
G.add_edge(root, root.left) #在当前节点和左儿子节点之间建立一条边,加入G
get_networkx_graph(G, root.left) #对左儿子执行同样操作
if root.right != None:
G.add_edge(root, root.right) #在当前节点和左儿子节点之间建立一条边,加入G
get_networkx_graph(G,root.right)#对右儿子执行同样操作
##编写函数,输入节点集合,返回其位置布局字典对象。
def get_tree_pos(G):
pos = {}
for node in G.nodes:
pos[node] = node.pos
return pos
##给节点设置显示颜色
def get_node_color(G):
color_dict = []
for node in G.nodes:
if node.f == None: #叶子节点
label = np.argmax(node.label_dist)
if label%3 == 0:
color_dict.append("#007979") #深绿色
elif label%3 == 1:
color_dict.append("#E4007F") #洋红色
else:
color_dict.append("blue")
else:
color_dict.append("gray")
return color_dict
#绘图
import matplotlib.pyplot as plt
import networkx as nx
%matplotlib inline
#1训练决策树
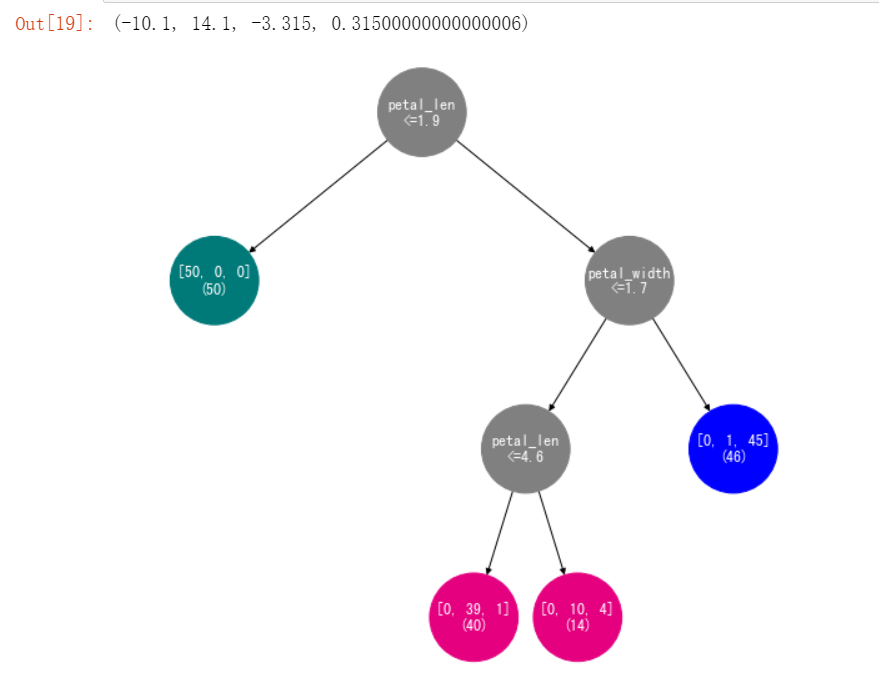
root,nodes = decision_tree_classifier(X_iris,y_iris,min_leaf_samples=10,max_depth=4)
#2将决策树进行可视化
fig, ax = plt.subplots(figsize=(9, 9)) #2.1将图的大小设置为 9×9
graph = nx.DiGraph() #2.2 创建 Networkx 中的网络对象
get_networkx_graph(graph, root) # 2.3 将决策树转换成 Networkx 的网络对象
pos = get_tree_pos(graph) #2.4 获取节点的坐标
# 2.5 绘制决策树
#node_size是节点标签,在生成TreeNode时已经特别写了一个函数打印节点标签。
nx.draw_networkx(graph,pos = pos,ax = ax,node_shape="o",font_color="w",node_size=5000,node_color=get_node_color(graph))
plt.box(False) #去掉边框
plt.axis("off")#去掉坐标轴
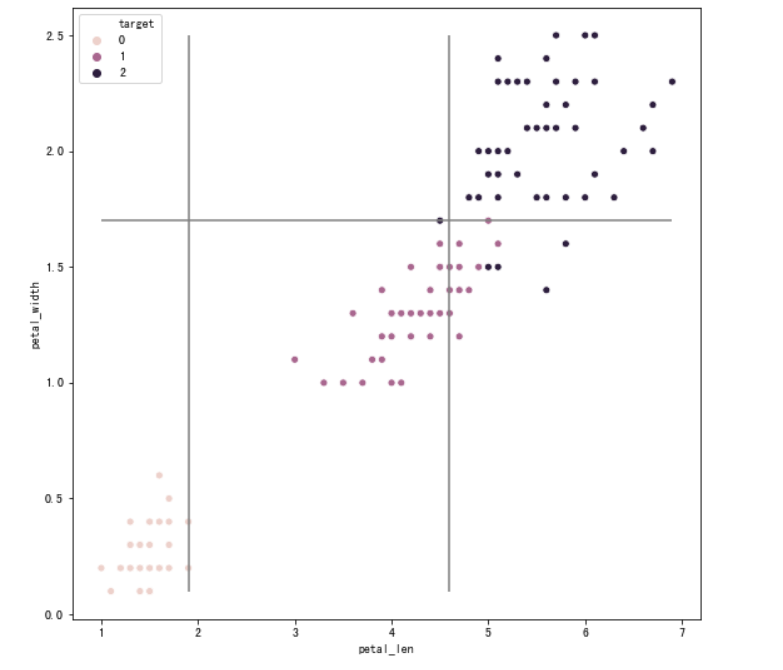
之后是绘制决策边界,这里使用的是seaborn
#绘制决策边界
import seaborn as sns
#筛选两列特征
feature_names = ["petal_len","petal_width"]
X = iris_df[feature_names]
y = iris_df["target"]
#训练决策树模型
tree_two_dimension, nodes = decision_tree_classifier(X,y,min_leaf_samples=10,max_depth=4)
#绘图
fig, ax = plt.subplots(figsize=(9, 9)) #设置图片大小
sns.scatterplot(x = X.iloc[:,0], y = X.iloc[:,1],ax = ax,hue = y) #绘制样本点
#遍历决策树节点,绘制划分直线
for node in nodes:
if node.f == X.columns[0]:
ax.vlines(node.v,X.iloc[:,1].min(),X.iloc[:,1].max(),color="gray") # 如果节点分裂特征是 petal_len ,则绘制竖线
elif node.f == X.columns[1]:
ax.hlines(node.v,X.iloc[:,0].min(),X.iloc[:,0].max(),color="gray") #如果节点分裂特征是 petal_width ,则绘制水平线
#将绘制决策边界方法封装成一个函数
def plot_tree_boundary(X,y,tree,nodes):
#优化计算每个决策线段的起始点
for node in nodes:
node.x0_min,node.x0_max,node.x1_min,node.x1_max = X.iloc[:,0].min(),X.iloc[:,0].max(),X.iloc[:,1].min(),X.iloc[:,1].max(),
node_list = []
node_list.append(tree)
while(len(node_list)> 0):
node = node_list.pop()
if node.f != None:
node_list.append(node.left)
node_list.append(node.right)
if node.f == X.columns[0]:
node.left.x0_max = node.v
node.right.x0_min = node.v
elif node.f == X.columns[1]:
node.left.x1_max = node.v
node.right.x1_min = node.v
fig, ax = plt.subplots(figsize=(9, 9)) #设置图片大小
sns.scatterplot(x = X.iloc[:,0], y = X.iloc[:,1],ax = ax,hue = y) #绘制样本点
#遍历决策树节点,绘制划分直线
for node in nodes:
if node.f == X.columns[0]:
ax.vlines(node.v,node.x1_min,node.x1_max,color="gray") # 如果是节点分裂特征是 petal_len ,则绘制竖线
elif node.f == X.columns[1]:
ax.hlines(node.v,node.x0_min,node.x0_max,color="gray") #如果是节点分裂特征是 petal_width ,则绘制水平线
#绘制边框
ax.vlines(X.iloc[:,0].min(),X.iloc[:,1].min(),X.iloc[:,1].max(),color="gray")
ax.vlines(X.iloc[:,0].max(),X.iloc[:,1].min(),X.iloc[:,1].max(),color="gray")
ax.hlines(X.iloc[:,1].min(),X.iloc[:,0].min(),X.iloc[:,0].max(),color="gray")
ax.hlines(X.iloc[:,1].max(),X.iloc[:,0].min(),X.iloc[:,0].max(),color="gray")
#调用该函数
plot_tree_boundary(X,y,tree_two_dimension,nodes)
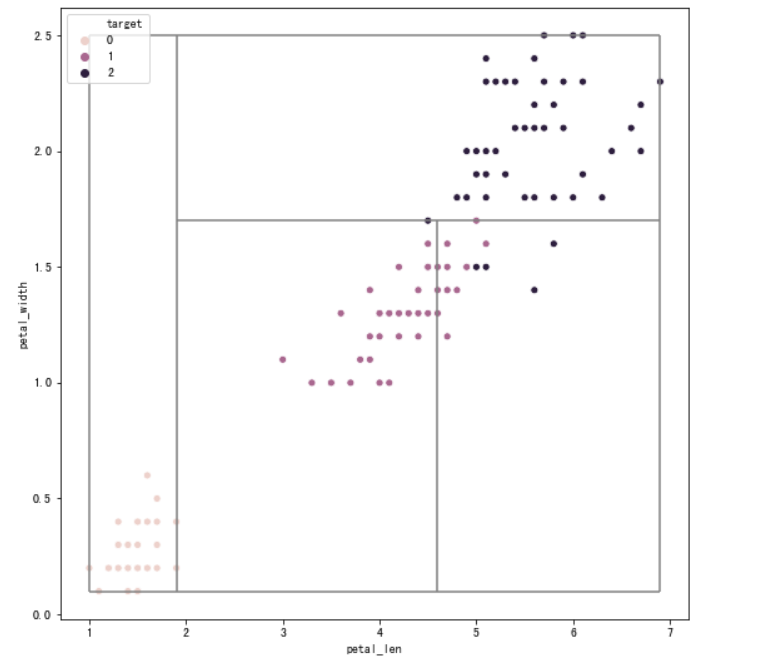
为了更好地理解决策边界,再随机生成两个数据集,绘图
#使用make_circles生成环形随机数据 ##再次绘制决策边界 from sklearn import datasets # 生成环形图,factor 控制两个环的距离 sample,target = datasets.make_circles(n_samples=1000,shuffle=True,noise=0.2,random_state=0,factor=0.4) data = pd.DataFrame(data=sample,columns=["x1","x2"]) data["label"] = target tree_two_dimension,nodes2 = decision_tree_classifier(data[["x1","x2"]],data["label"],min_leaf_samples=10,max_depth=5) plot_tree_boundary(data[["x1","x2"]],data["label"],tree_two_dimension,nodes2)
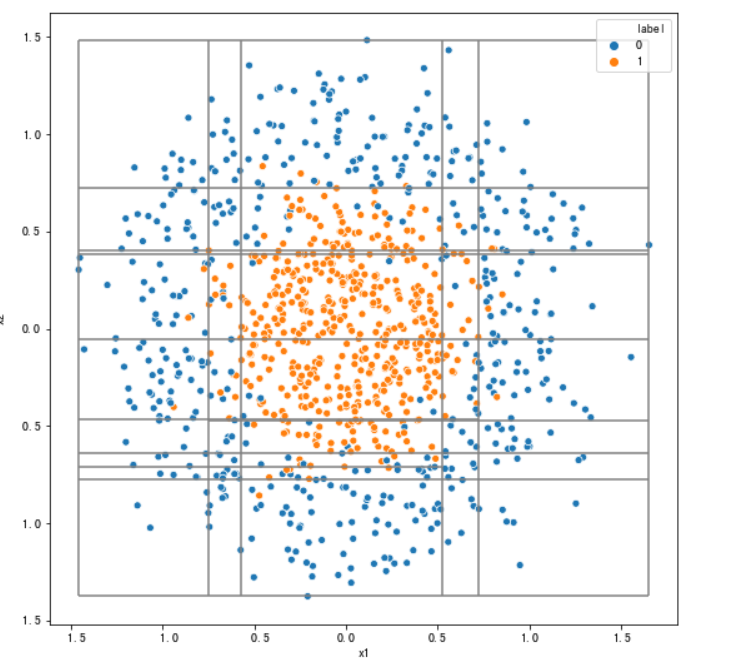
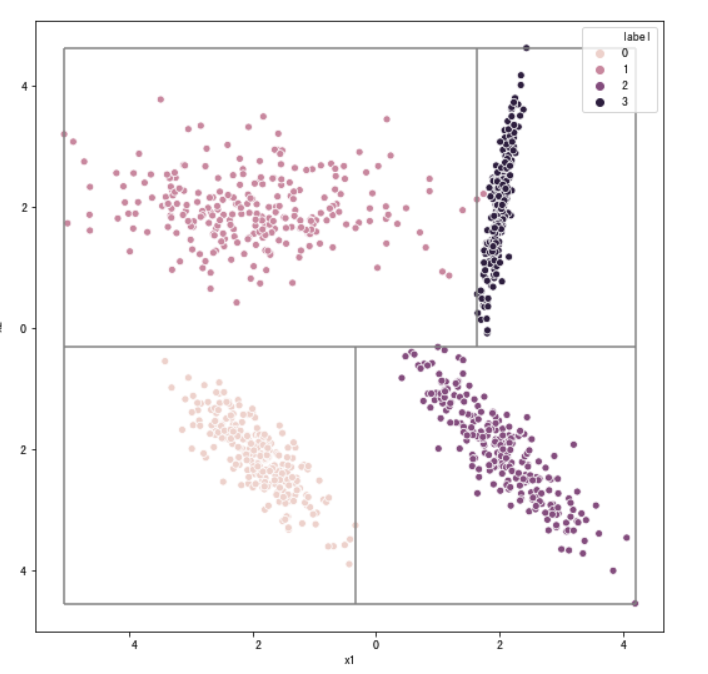
#使用make_classification生成一个随机分类数据集
##再次绘制决策边界
from sklearn import datasets
sample,target = datasets.make_classification(n_samples=1000, #样本数量
n_classes=4, #类别数量
n_features=2, #特征数量
n_informative=2,#有信息特征数量
n_redundant=0, #冗余特征数量
n_repeated=0, # 重复特征数量
n_clusters_per_class=1, #每一类的簇数
flip_y=0, # 样本标签随机分配的比例
class_sep=2,#不同类别样本的分散程度
random_state=203)
data = pd.DataFrame(data=sample,columns=["x1","x2"])
data["label"] = target
tree_two_dimension,nodes2 = decision_tree_classifier(data[["x1","x2"]],data["label"],min_leaf_samples=10,max_depth=5)
plot_tree_boundary(data[["x1","x2"]],data["label"],tree_two_dimension,nodes2)
最后是决策树的预测函数
#实现决策树的预测函数:在原有TreeNode类的基础上添加predict函数
class TreeNode:
def __init__(self,x_pos,y_pos,layer,class_labels=[0,1,2]):
self.f = None #当前节点的切分特征
self.v = None #当前节点的切分点
self.left = None #左儿子节点
self.right = None #右儿子节点
self.pos = (x_pos,y_pos) # 节点坐标,可视化用
self.label_dist = None #当前节点样本的类分布
self.layer = layer
self.class_labels = class_labels
def __str__(self): #打印节点信息,可视化时的节点标签
if self.f != None:
return self.f + "\n<=" + str(self.v)
else:
return str(self.label_dist) + "\n(" + str(round(np.sum(self.label_dist),2)) + ")"
#对测试样本进行预测
def predict(self,x):
if self.f == None:
return self.class_labels[np.argmax(self.label_dist)]
elif x[self.f] <= self.v:
return self.left.predict(x)
else:
return self.right.predict(x)
#训练决策树模型
tree,tree_nodes = decision_tree_classifier(X_iris,y_iris,min_leaf_samples=10,max_depth=4)


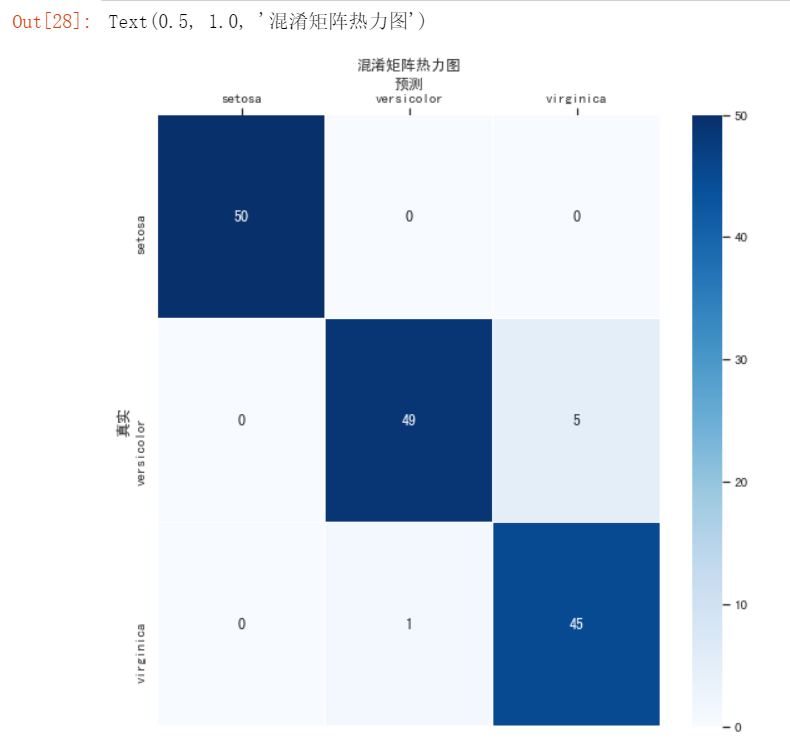
#绘制热力图
from sklearn.metrics import confusion_matrix
import seaborn as sns
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(9,9))
# 设置正常显示中文
sns.set(font='SimHei')
# 绘制热力图
confusion_matrix = confusion_matrix(y_pred,iris_df["target"])#计算混淆矩阵
ax = sns.heatmap(confusion_matrix,linewidths=.5,cmap="Blues",
annot=True, fmt='d',xticklabels=iris.target_names, yticklabels=iris.target_names)
ax.set_ylabel('真实')
ax.set_xlabel('预测')
ax.xaxis.set_label_position('top')
ax.xaxis.tick_top()
ax.set_title('混淆矩阵热力图')
随机森林算法:
#随机森林算法。
def random_forest(X,y,num_trees=10,num_features = 10,min_leaf_samples=10,max_depth=5):
trees = []
nodes_list = []
for t in range(num_trees):
#2.1随机生成特征子集
features_sample = np.random.choice(X.columns,num_features,replace=False)
# 有放回地抽样样本
sample_index = np.random.choice(X.index,len(X),replace=True)
#2.2 得到本轮训练数据集
X_sample = X[features_sample].loc[sample_index,:]
y_sample = y[sample_index]
#2.3训练决策树
tree,nodes = decision_tree_classifier(X_sample,y_sample,min_leaf_samples,max_depth)
trees.append(tree)
nodes_list.append(nodes)
return trees,nodes_list #返回树根的集合,以及每棵树的节点集合的列表
#使用鸢尾花数据集进行测试
##先将鸢尾花数据集随机划分为训练集和测试集
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X_iris,y_iris,test_size=0.5,stratify=y_iris)
##训练随机森林算法,树数量=10,每棵树随机选择3个特征训练,决策树最大深度=3,叶子节点最小样本数=10
trees,nodes_list = random_forest(X_train,y_train,num_trees=10,num_features = 3,min_leaf_samples=10,max_depth=3)
##绘图
%matplotlib inline
fig, ax = plt.subplots(figsize=(30, 30))
for i in range(len(trees)): # 遍历随机森林中的每棵树
plt.subplot(3,4,i+1)
graph = nx.DiGraph()
get_networkx_graph(graph, trees[i]) #将决策树转换成 networkx 网络对象
pos = get_tree_pos(graph)
nx.draw_networkx(graph,pos = pos,node_shape="o",font_color="w",node_size=5000,node_color=get_node_color(graph)) #绘制决策树
plt.box(False)
plt.axis("off")
部分效果图如下:
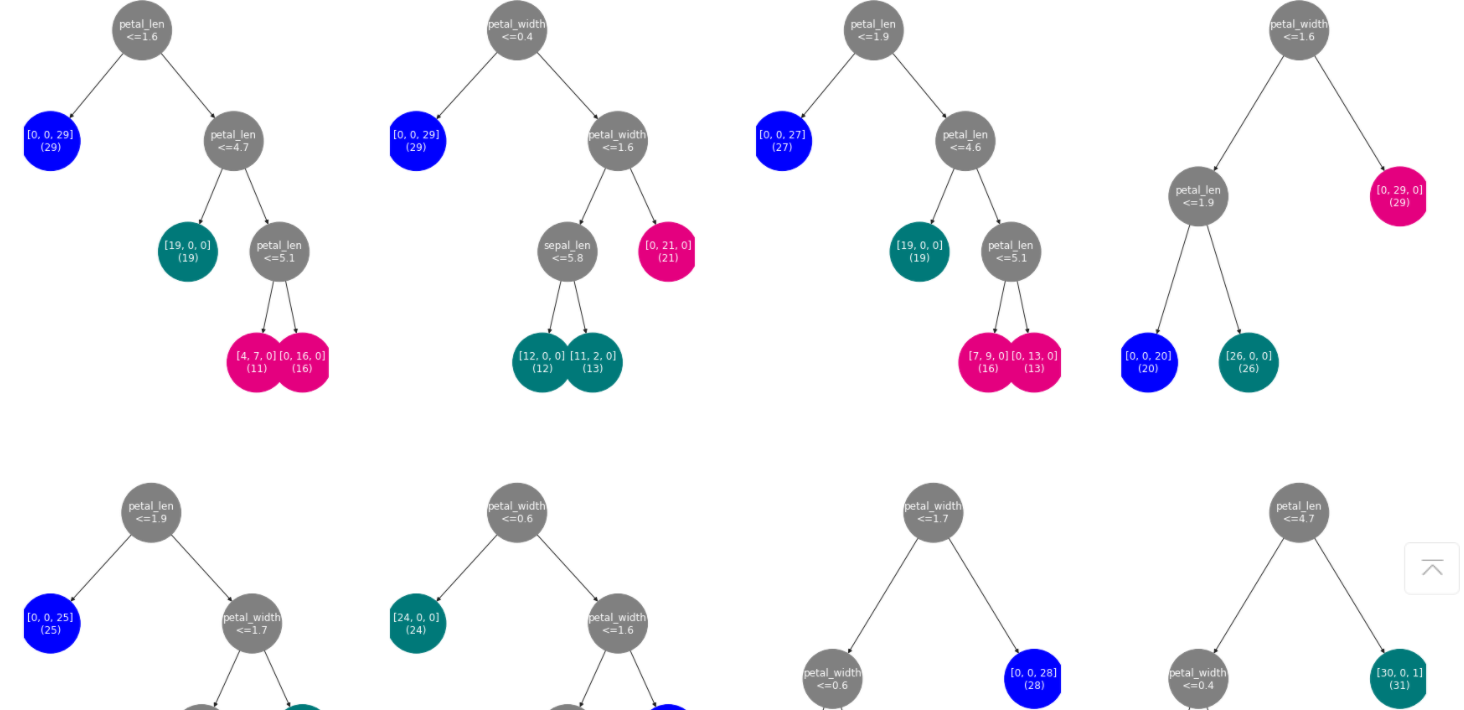
#随机森林预测
def rf_predict(trees,X_test):
results = []
for _,sample in X_test.iterrows():
pred_y = []
for tree in trees:
pred_y.append(tree.predict(sample))
results.append(pd.Series(pred_y).value_counts().idxmax()) #实现投票
return results
#获得在预测集上的预测结果
y_test_pred = rf_predict(trees,X_test)
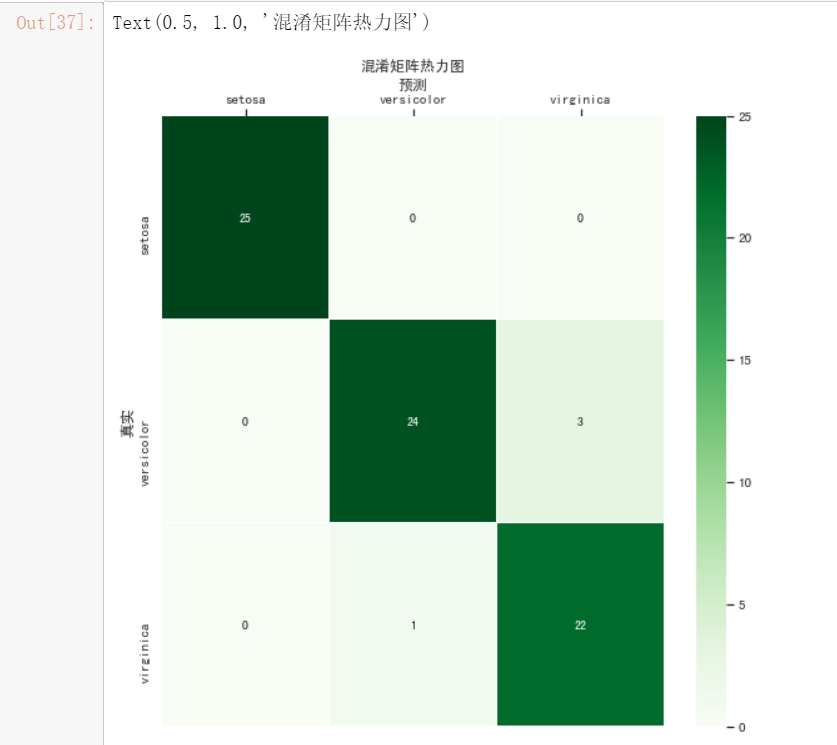
#绘制热力图
from sklearn.metrics import confusion_matrix
import seaborn as sns
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(9,9))
confusion_matrix = confusion_matrix(y_test_pred,y_test)#计算混淆矩阵
ax = sns.heatmap(confusion_matrix,linewidths=.5,cmap="Greens",
annot=True, fmt='d',xticklabels=iris.target_names, yticklabels=iris.target_names)
ax.set_ylabel('真实')
ax.set_xlabel('预测')
ax.xaxis.set_label_position('top')
ax.xaxis.tick_top()
ax.set_title('混淆矩阵热力图')
AdaBoost算法:
import numpy as np
def gini_with_weight(y,sample_weights):
weights = sample_weights[y.index] #从全量样本权重中,抽取当前样本子集的权重
return 1 - np.square(weights.groupby(y).sum()/weights.sum()).sum() #将权重按照取值进行分组,每一组求和,除以当前样本总权重,再求平方和。
#修改基尼系数
def generate_with_weights(X,y,x_pos,y_pos,nodes,min_leaf_samples,max_depth,layer,class_labels,sample_weights):
current_node = TreeNode(x_pos,y_pos,layer,class_labels)#创建节点对象
current_node.label_dist = [len(y[y==v]) for v in class_labels] #当前节点类样本分布
nodes.append(current_node)
if(len(X) < min_leaf_samples or gini_with_weight(y,sample_weights) < 0.1 or layer > max_depth): #判断是否需要生成子节点
return current_node
max_gini,best_f,best_v = 0,None,None
for f in X.columns: #特征遍历
for v in X[f].unique(): #取值遍历
y1,y2 = y[X[f] <= v],y[X[f] > v]
if(len(y1) >= min_leaf_samples and len(y2) >= min_leaf_samples):
imp_descent = gini_with_weight(y,sample_weights) - gini_with_weight(y1,sample_weights)*sample_weights[y1.index].sum()/sample_weights[y.index].sum() - gini_with_weight(y2,sample_weights)*sample_weights[y2.index].sum()/sample_weights[y.index].sum() # 计算不纯度变化
if imp_descent > max_gini:
max_gini,best_f,best_v = imp_descent,f,v
current_node.f,current_node.v = best_f,best_v
if(current_node.f != None):
current_node.left = generate_with_weights(X[X[best_f] <= best_v],y[X[best_f] <= best_v],x_pos-(2**(max_depth-layer)),y_pos -1,nodes,min_leaf_samples,max_depth,layer + 1,class_labels,sample_weights)
current_node.right = generate_with_weights(X[X[best_f] > best_v],y[X[best_f] > best_v],x_pos+ (2**(max_depth-layer)),y_pos -1,nodes,min_leaf_samples,max_depth,layer + 1,class_labels,sample_weights)
return current_node
#实现AdaBoost算法
def adaboost(X,y,num_trees=10,min_leaf_samples=10,max_depth=5):
trees = []
tree_weights = []
# 1 初始化样本权重
sample_weights = pd.Series(data=np.ones_like(y)/len(y),index=y.index)
for t in range(num_trees):
#2.1 使用当前权重训练决策树
nodes = []
tree = generate_with_weights(X,y,0,0,nodes,min_leaf_samples,max_depth,1,[-1,1],sample_weights)
# 2.2 计算当前分类器的误差
#获得预测值
y_pred = []
for _,sample in X.iterrows():
y_pred.append(tree.predict(sample))
y_pred_ts = pd.Series(data=y_pred,index=y.index)
error = sample_weights[y != y_pred_ts].sum()/sample_weights.sum()
# 2.3 根据当前误差,计算当前数的权重
alpha_t = 0.5*np.log((1-error)/error)
# 2.4 更新样本的权重
sample_weights = sample_weights * np.power(np.e,-alpha_t * y_pred_ts * y)
sample_weights = sample_weights/sample_weights.sum()
trees.append(tree)
tree_weights.append(alpha_t)
return trees,tree_weights
使用随机数据集进行测试
from sklearn import datasets
# 生成数据
sample,target = datasets.make_classification(n_samples=20, n_features=2, n_informative=2,n_redundant=0, n_classes=2, n_clusters_per_class=2, scale=7.0,random_state=110)
data = pd.DataFrame(data=sample,columns=["x1","x2"])
data["label"] = target
data["label"] = data["label"].map({0:-1,1:1})
X,y = data.iloc[:,:-1], data["label"]
fig, ax = plt.subplots(figsize=(9, 9)) #设置图片大小
sns.scatterplot(x = X.iloc[:,0], y = X.iloc[:,1],ax = ax,hue = y,s=100) #绘制样本点
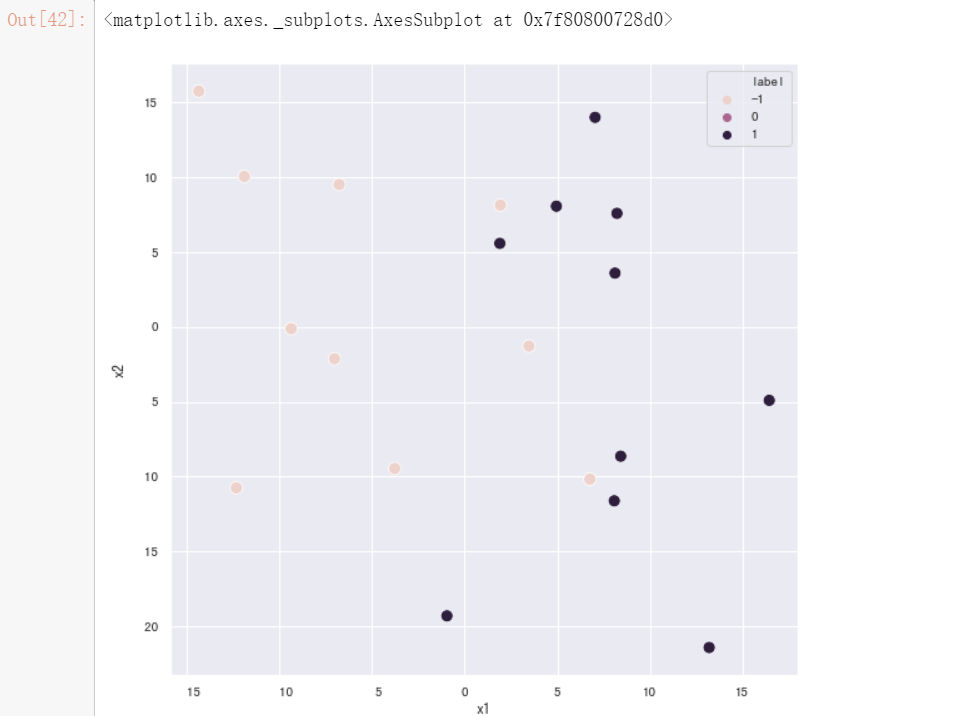
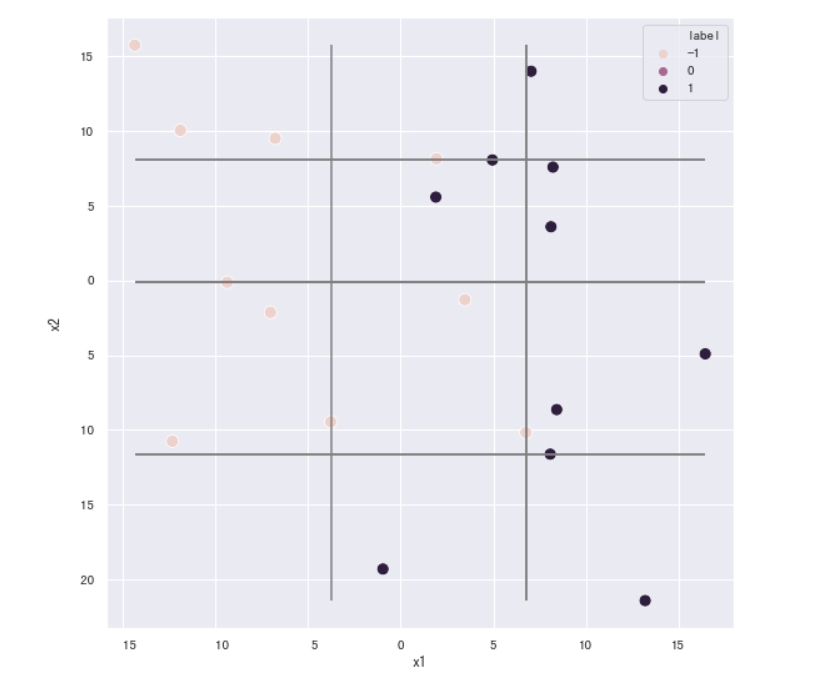
adatrees_two_dimension,_ = adaboost(X,y,num_trees=10,min_leaf_samples=2,max_depth=1)
fig, ax = plt.subplots(figsize=(9, 9)) #设置图片大小
sns.scatterplot(x = X.iloc[:,0], y = X.iloc[:,1],ax = ax,hue = y,s=100) #绘制样本点
#绘制划分直线
for tree in adatrees_two_dimension:
if tree.f == "x1":
plt.vlines(tree.v,data["x2"].min(),data["x2"].max(),color="gray") # 如果是节点分裂特征是 x1 ,则绘制竖线
elif tree.f == "x2":
plt.hlines(tree.v,data["x1"].min(),data["x1"].max(),color="gray") #如果是节点分裂特征是 x2 ,则绘制水平线
最后附上AdaBoost算法的预测函数写法,因运行问题未能实现后续案例中的实例效果展示:
def adaboost_predict(trees,weights,X_test):
results = []
for _,sample in X_test.iterrows():
pred_y_sum = 0
for t in range(len(trees)):
pred_y_sum += trees[t].predict(sample)*weights[t] #每棵树的预测值的加权和
results.append(1 if pred_y_sum >= 0 else -1)
return results

 浙公网安备 33010602011771号
浙公网安备 33010602011771号