《机器学习十讲》第一讲
源地址(相关案例在视频下方):http://cookdata.cn/auditorium/course_room/10012/
第一讲主要是对机器学习的概念介绍,总结如下:
机器学习定义:机器学习是一系列【能够自动从已知数据里检测出模式(规律),并使用该模式对未来数据的模式(规律)去做预测,用以支持决策】的方法。该决策是不确定性的。
Data--->X Y=F(X)
Data:数据;X:表示,特征,指标;F:模型;Y:智慧(预测任务或目标)
大数据指数据采集,数据清洗,数据分析和数据应用的整个流程中理论,技术和方法,即上述公式的整个流程
机器学习是大数据分析的核心内容,解决的是找到关联X和Y的模型F,从Data到X的步骤通常是人工完成(特征工程)
深度学习是机器学习的一部分,核心是自动找到对特定任务有效的特征,即自动完成Data到X的转换。
若Y是模拟人类的行为,则称为人工智能。
机器学习方法:有监督学习,无监督学习,强化学习。
有监督学习:数据集中样本带有标签(Y),有明确目标。【有X,有Y】
目标:找到样本到标签的最佳映射(F)。
典型方法:回归模型:线性回归,岭回归,LASSO和回归样条等
分类模型:逻辑回归,K近邻,决策树,支持向量机
应用场景:垃圾邮件分类,病理切片分类,客户流失预警,客户风险评估,房价预测等。
无监督学习:数据集中样本没有标签,没有明确目标。【有X,没有Y】
聚类:将数据集中相似的样本进行分组,使得同一组对象之间尽可能相似;不同组对象之间尽可能不相似。
应用场景:基因表达水平聚类,运动员划分,客户分析等。
强化学习:智慧决策过程,通过过程模拟和观察来不断学习,提高决策能力。例:AlphaGo。
基本概念:agent(智能体),environment(环境),state(状态,st),action(行动,at),reward(奖励,rt)。
策略:Π(a|s)。
目标:求解最大化效用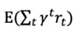 的最优策略。
的最优策略。
核心概念:一开始没有数据,通过动作模拟产生数据,再根据环境交互进行学习。
基础概念:
数据集:一组样本的集合
样本:数据集的一行。一个样本包含一个或多个特征,还可能包含一个标签。【有监督学习包括特征和样本,无监督学习只有特征】
特征:在进行预测时使用的输入变量。
训练集:用于训练模型的数据集
测试集:用于测试模型的数据集
模型:建立数据的输入x和输出y之间的映射关系,y=f(x)
损失函数:L(yi,f(xi)),例如对回归问题可以定义为(f(xi)-yi)^2
优化目标: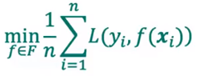 损失函数最小化。
损失函数最小化。
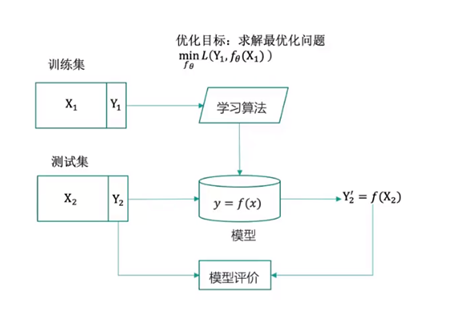
机器学习一般流程(图示,有监督学习):
过度拟合问题
定义:模型过于复杂,对已知数据预测很好,但对未知数据预测很差。
解决方法之一——正则化:
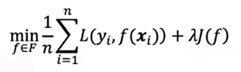
在误差函数上加一个正则项,正则项通常为参数向量的范数。
模型选择
交叉验证:重复地使用数据。将数据集随机切分,切分的数据集组合为训练集和测试集,在此基础上反复进行训练,测试和模型选择。
K折交叉验证:随机地将数据切分为k个子集;每次利用k-1个子集的数据训练模型,余下的数据用来测试模型;最后选择在k次测评中平均性能最好的模型
机器学习的数学结构
度量结构:表示数据之间的距离。
以文本处理为例,计算两篇文章距离:
① 以字典上所有词作为坐标,对应文章中词频作为坐标值,将文章表示为向量。
② 使用余弦相似度计算文章的距离。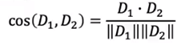
其他常用距离:曼哈顿距离,欧式距离,极大距离。
K近邻
定义:对测试样本进行分类时,找到训练集中与该样本最相似的K个样本,根据K个样本的标签确定测试样本标签。
注意:K的选择对模型的影响很大,因此K通常要做一个超参数,进行交叉验证。
提高计算速度:K近邻算法最常用的数据结构为k-d树,是二叉搜索树在多维空间上的扩展;当落在某一个节点的超立方体中的样本数少于给定阈值时,节点不再进一步分裂;K近邻算法中k-d树的作用是对训练数据集构建索引,在预测时能够快速找到与测试样本近似的样本。
————————————————————
网络结构:有些数据本身就有网络结构,如社交网络。若没有,可以利用度量结构给数据附加一个网络结构。
表示:G=<V,E>,V表示节点,E表示边。
两个样本的距离小于某个阈值时,就连一条边,也可以进一步将边赋予权重(两个样本的相似度)
PageRank算法
1,在网络结构上定义邻接矩阵A=[aij],其中aij定义为:aij=1【节点i与j相连】,aij=0【节点i与j不相连】
2,从邻接矩阵得到概率转移矩阵,T=[tij],其中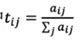
3,如果Πi表示节点i的重要性,PageRank算法主要在求解方程Π=ΠT
可见PageRank的解是转移矩阵特征值1对应的特征向量。
如果网络是连通的,则算法有唯一的正的解(Perron-Frobenius定理)
————————————————————
代数结构:将数据看作向量,矩阵或更高阶的张量。
几何结构:流形,对称性等。
很多看上去是高维空间的数据集,实际上在高维空间的一个低维的流形上,因此复杂数据往往有简单的结构,深度学习不容易发生过拟合的原因之一正是在处理复杂数据集时往往倾向这些“简单的结构”。
图像往往具有旋转不变性和平移不变性等,卷积神经网络就主要考虑了这些性质。
工具介绍——Scikit-learn。
由于我已经安装了Anaconda环境,因此无须安装,可以直接使用。
Scikit-learn基本建模流程:
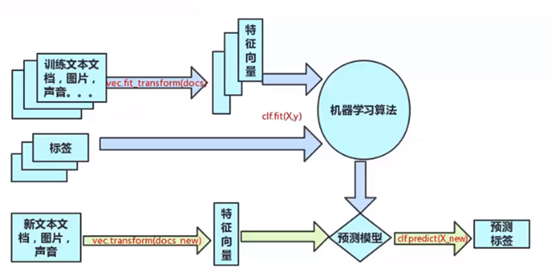
常用函数:
transform函数:数据转换
fit函数:模型训练
predict函数:模型预测
主要模块:
preprocessing:数据预处理和标准化
feature_extraction:特征提取
feature_selection:特征选择
linear_model:线性模型
tree:基于树的模型
cluster:无监督聚类算法
discriminant_analysis:线性判别分析
ensemble:集成模型
metrics:模型评价
model_selection:模型选择与参数调优
视频中还通过两个案例来进行讲解,分别是KNN算法和PageRank算法,案例已经存好,正在进行代码理解:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号