开源任务管理框架oozie学习
1、 oozie简介
应用背景:在工作中,可能需要好几个Hadoop作业(job)来协作完成,往往一个job的输出会被当做另一个job的输入来使用,这个时候就涉及到了数据流的处理。
我们不可能就盯着程序,等它运行完再去运行下一个程序,所以,一般的做法就是通过shell来做,但是如果涉及到的工作流很复杂(比方说有1,2,3,4四个作业,1的输出作为2 3 4的输入,然后2 3的结果运算之后再和1的结果进行某种运算……最后再输出)是很费时费力的。这里就用到了oozie——一个能把多个MR作业组合为一个逻辑工作单元(一个工作流),从而自动完成任务调用的工具。
oozie字面释义为训象人,是一个基于Hadoop的开源工作流调度框架,运行在内置的Tomcat中,支持多种Hadoop类型作业调度,如常见的MapReduce、hive、spark、shell脚本等任务。
特点:1)、基于Hadoop的任务流的任务调度系统;(任务流基于workflow.xml配置文件去定义,主要围绕Hadoop的平台组件的任务调度);
2) 、工作流是由action组成的有向无环图(DAG);
3)、多个workflow(任务流)可以组成一个coordinator(协调器),多个coordinator可以抽象成bundle。coordinator job是由时间(频率)和数据可用性触发的重复的workflow jobs;
4)、支持Hadoop平台的多种任务类型,如Java map-reduce, Streaming map-reduce, Pig, Hive, Sqoop and Distcp,同时也支持Java 程序和shell脚本等;
5)、oozie是一个可伸缩、高可用、可扩展的系统;(基于Hadoop平台而言)
oozie 安装:1)从Apache官网下载源码,通过maven编译生成安装包,mkdistro.sh脚本编译需要指定Hadoop、hive、spark等版本号,根据版本获取依赖包,生成安装文件;

2)、编译成功之后会在distro/target下生成一个oozie-4.3.1-distro.tar.gz 安装文件,解压安装文件,将oozie.war增加extjs 包和数据库jdbc连接包之后,从先打包成新的war包;
3)、通过oozie.sql 创建数据库,导入环境变量,执行oozie-run.sh,启动成功,界面为11000端口访问:
2、 oozie的架构及实现原理
组件架构图如下:
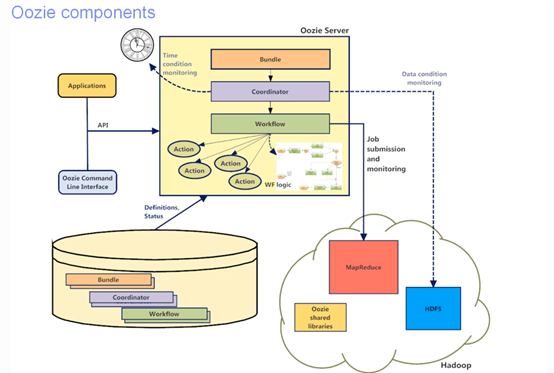
原理:oozie对工作流的编排,是基于workflow.xml文件来完成的,用户预先将工作流执行规则定制于workflow.xml文件中,并在job.properties配置相关的参数,然后由oozie server 向服务器提交一个JOB来启动工作流。
工作流由两种节点组成,分别为控制流节点和执行节点:
控制流节点(Control Flow Nodes):控制工作流的执行路径,包括start、end、kill、decision、fork、join等;
行为节点(Action Nodes):决定每个操作执行的任务类型,包括map-reduce,java,hive,shell,pig等;
3、工作流配置
一个oozie 的 job 一般由以下文件组成(文件需要上传到HDFS,不支持本地运行):
job.properties :记录了job的属性;
workflow.xml :定义任务的流程和分支;
lib目录:用来执行具体的任务,也就是我们需要执行的jar包或命令文件;
job.properties 配置文件:
nameNode=hdfs://127.0.0.1:8020 //HDFS 地址 jobTracker=127.0.0.1:8032 // 配置resourcemanager地址 queueName=default //oozie队列名称(默认default) examplesRoot=examples //全局目录(默认examples) oozie.use.system.libpath=true //是否加载用户lib目录 oozie.wf.application.path=${nameNode}/user/${user.name}/${examplesRoot}/apps/spark //任务流地址(workflow.xml所在地址) //user.name 当前用户
workflow.xml 配置文件:
spark action:
<workflow-app name="[WF-DEF-NAME]" xmlns="uri:oozie:workflow:0.3"> ... <action name="[NODE-NAME]"> <spark xmlns="uri:oozie:spark-action:0.1"> <job-tracker>[JOB-TRACKER]</job-tracker> <name-node>[NAME-NODE]</name-node> <prepare> //任务启动之前执行文件操作 <delete path="[PATH]"/> ... <mkdir path="[PATH]"/> ... </prepare> <job-xml>[SPARK SETTINGS FILE]</job-xml> //指定spark job的配置文件,多个配置文件可以配置多个标签 <configuration> //需要对spark进行定义的配置属性,如name为mapred.compress.map.output,value为true <property> <name>[PROPERTY-NAME]</name> <value>[PROPERTY-VALUE]</value> </property> ... </configuration> <master>[SPARK MASTER URL]</master> //yarn-cluster 、yarn-master等 <mode>[SPARK MODE]</mode> //spark 运行模式client、cluster等 <name>[SPARK JOB NAME]</name> //job name <class>[SPARK MAIN CLASS]</class> <jar>[SPARK DEPENDENCIES JAR / PYTHON FILE]</jar> // jar包或python文件,多个以,分隔 <spark-opts>[SPARK-OPTIONS]</spark-opts> //传递给driver的参数,如—conf,--driver-memory 等 <arg>[ARG-VALUE]</arg> //指定spark job参数,如inputpath,value等 ... </spark> <ok to="[NODE-NAME]"/> //执行成功之后下一个执行action <error to="[NODE-NAME]"/> //执行失败之后下一个执行action </action> ... </workflow-app> hive action: <workflow-app name="[WF-DEF-NAME]" xmlns="uri:oozie:workflow:0.4"> ... <action name="[NODE-NAME]"> <hive2 xmlns="uri:oozie:hive2-action:0.1"> <job-tracker>[JOB-TRACKER]</job-tracker> <name-node>[NAME-NODE]</name-node> <prepare> <delete path="[PATH]"/> ... <mkdir path="[PATH]"/> ... </prepare> <job-xml>[HIVE SETTINGS FILE]</job-xml> <configuration> <property> <name>[PROPERTY-NAME]</name> <value>[PROPERTY-VALUE]</value> </property> ... </configuration> <jdbc-url>[jdbc:hive2://HOST:10000/default]</jdbc-url> <password>[PASS]</password> <script>[HIVE-SCRIPT]</script> //指定hive脚本的执行文件 <param>[PARAM-VALUE]</param> //对hive脚本中定义的变量进行值传递 ... <param>[PARAM-VALUE]</param> <argument>[ARG-VALUE]</argument> //beeline 命令行的参数值传递 ... </hive2> <ok to="[NODE-NAME]"/> <error to="[NODE-NAME]"/> </action> ... </workflow-app>
4、例子
以自带的example为示例,配置job.properties:
public final class SparkFileCopy { public static void main(String[] args) throws Exception { if (args.length < 2) { System.err.println("Usage: SparkFileCopy <file> <file>"); System.exit(1); } SparkConf sparkConf = new SparkConf().setAppName("SparkFileCopy"); JavaSparkContext ctx = new JavaSparkContext(sparkConf); JavaRDD<String> lines = ctx.textFile(args[0]); lines.saveAsTextFile(args[1]); System.out.println("Copied file from " + args[0] + " to " + args[1]); ctx.stop(); } }
任务提交命令:oozie job -oozie http://127.0.0.1:11000/oozie -config job.properties -run
job.properties 配置:
nameNode=hdfs://127.0.0.1:8020 jobTracker=127.0.0.1:8032 master=yarn-client queueName=default examplesRoot=examples oozie.use.system.libpath=true oozie.wf.application.path=${nameNode}/user/${user.name}/${examplesRoot}/apps/spark

 浙公网安备 33010602011771号
浙公网安备 33010602011771号