Elastic Search 学习之路(二)——inverted index(反向索引)
这是篇翻译文,图画的挺有意思。
Elastic使用非常特殊的数据结构,称作反向索引。反向索引中,包括了一组document中出现的唯一的单词,和对应的单词,所出现的位置。反向索引是在ES中,document被创建的同时,创建的。创建的过程称作“分析”。接下来,会说明它是如何被创建以及如何被保存在shard中用来搜索docuemnt
从Document到可被查找的索引
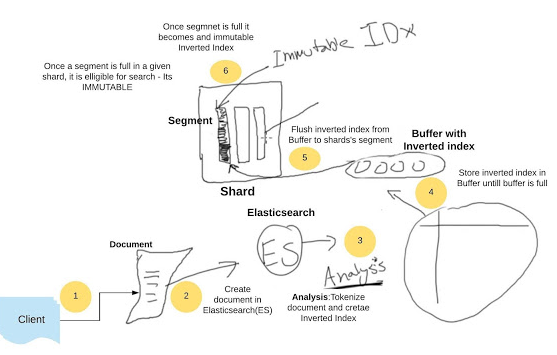
・Client端发送命令在ELS中创建document。
・一旦document在ELS中被创建,它要经历分析阶段。在这阶段中,document被tokenized(整体的东西被拆分成个体)和normalised(正常化)。
・对于给定的document,反向索引将被创建,保存在临时的buff之中,直到buffer变满为止。一旦变满,将被冲到segment中。
・segment是最小的逻辑单元,shard可以看做是一组segment的集合。segment里全是从buffer过来的反向索引。
・一旦segment装满了反向索引,shard就可以被搜索。
用于索引和查询的文本分析(反向索引的创建)
分析过程是在shard中,创建索引的核心过程。不仅在创建document时被使用,还会在查询时使用。下图是在索引过程中如何被使用的。
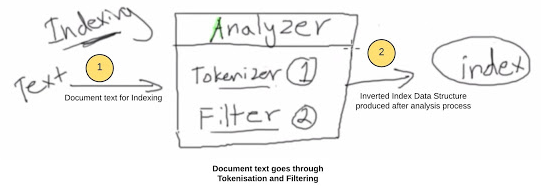
・假设我们有两条document要被创建
{ "name" : "Nikhil", "id": "zytham", "comment" : "The thin lifeguard was swimming in the lake" "date" : "2018-02-12" } { "name" : "Ranjan", "id": "nranjan", "comment" : "Swimmers race with the skinny lifeguard in lake" "date" : "2018-02-12" }
假设我们关心comment部分。我们有两行文本要分析。
1. The thin lifeguard was swimming in the lake
2. Swimmers race with the skinny lifeguard in lake
Tokenisation(分解化):
首先区分单词,创建排序列表。下方1,2表示出现在第几个document中。
| Token | Present in Document |
|---|---|
| Swimmers | 2 |
| The | 1 |
| in | 1,2 |
| lifeguard | 1,2 |
| lake | 1,2 |
| race | 2 |
| skinny | 2 |
| swimming | 2 |
| the | 1,2 |
| thin | 1 |
| was | 1 |
| with | 1 |
Filter:
去除停顿词,如the、in等。
小写化(目的是查询时不区分大小写)
获取词根(swimming to swim)
同义词转换(thin == skinny)
这次都是基于ELS提供的内置的文本分词器。也有对应的中文的分词器。
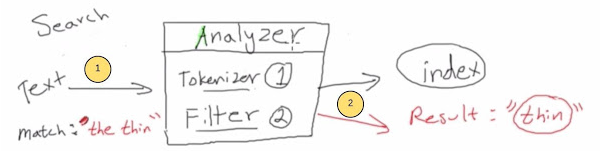
查询document时进行文本分析。
当使用get命令查询document,索引化时会使用同样的分析器。如:查询the thin时,会先去掉the,然后同义词转换,最后查询,返回检索到的document.
参考资料:
http://www.devinline.com/2018/09/elasticsearch-inverted-index-and-its-storage.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号