关于ava容器、队列,知识点总结
推荐《java 并发编程实战》这本书,中文的翻译有些差(哈哈,并发确实难,不好翻译),适合有并发经验的人来读。
这篇短文,整理了容器的知识点,对容器的使用场景,容器的原理等有个整体的认知!
1. 层次构造
看看下面的Collection层次构造图:
(这张图为突出某些重点,对层次上的东西进行了取舍,此外类继承的多个接口,也没有表示出来)
FIFO:first-in-first-out
bounded:有界队列
doubly-linked:双向链表
natural ordering:自然顺序
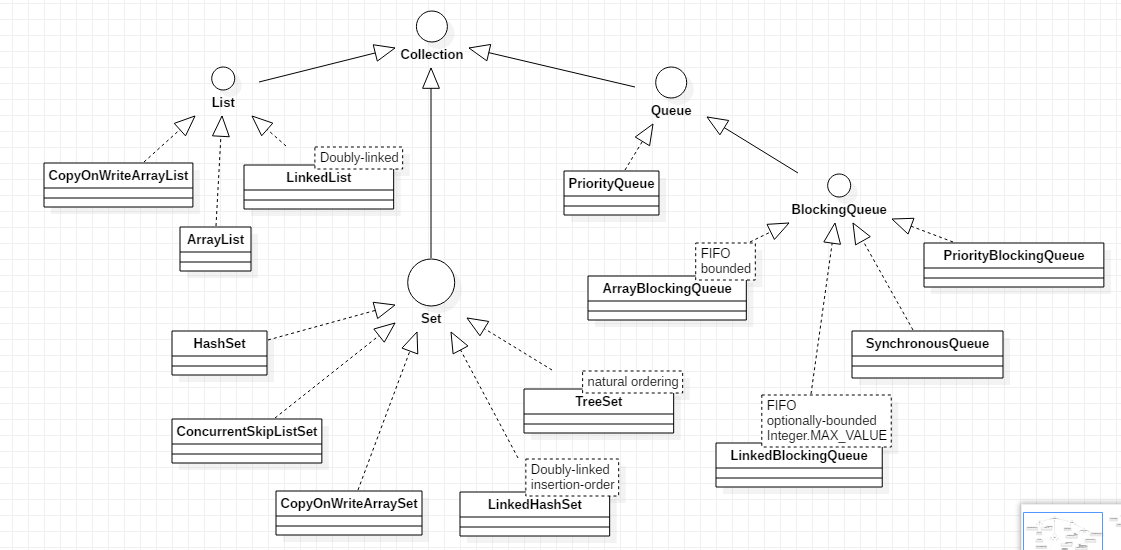
上图中,我们常用的集合基本都罗列了。一些需要注意到的东西也在上面列举了,希望大家好好看看。在类或接口的右上方,有些注释,标明了它的一次特点或是原理。
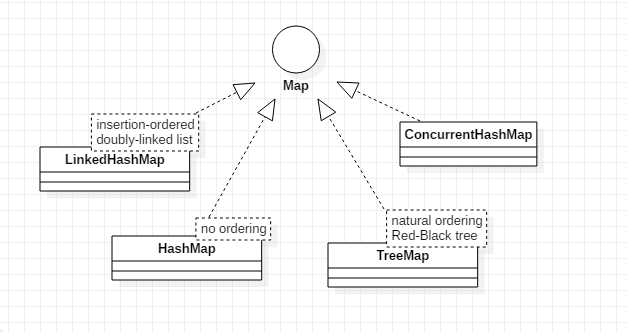
接下来看看Map的部分:
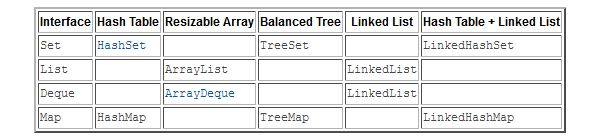
我们再看一下面这张图,阐述了容器实现的方式:
2. 迭代器
ArrayList、LinkedList等容器的实现都不是同步的。在多线程的情况下,必须进行额外的同步操作。一种方式就是,加上同步器,同步器的锁就是list。另外一种方式,在容器创建的时候,用Collections中的方法对容器进行包装,示例如下:
1 List list = Collections.synchronizedList(new ArrayList()); // 包装之后,就是线程安全的。 2 ... 3 synchronized (list) { // 不加锁的话,迭代器会出现ConcurrentModificationException
// 这里呢,还有一种可替代方案:克隆容器,然后在副本上进行迭代 4 Iterator i = list.iterator(); // Must be in synchronized block 5 while (i.hasNext()) 6 foo(i.next()); 7 }
1 Map m = Collections.synchronizedMap(new HashMap()); 2 ... 3 Set s = m.keySet(); // Needn't be in synchronized block 4 ... 5 synchronized (m) { // Synchronizing on m, not s! 6 Iterator i = s.iterator(); // Must be in synchronized block 7 while (i.hasNext()) 8 foo(i.next()); 9 }
(Collections中还有其他实用的方法,请查看java api)
3. 并发容器
ConcurrentHashMap:
使用分段锁的机制,允许任意数量的读取线程并发访问Map,并且一定数量的写入线程可以并发地修改Map。它带来的结果是,在并发访问环境下将实现更好的吞吐量,而在单线程环境中只损失非常小的性能。ConcurrentHashMap和其他并发容器不会抛出ConcurrentModificationException,因此不需要再迭代过程中对容器加锁。ConcurrentHashMap返回的迭代器具有弱一致性,而并非“及时失败”。弱一致性的迭代器可以容忍并发的修改。
(弱一致性该如何理解呢?数据更新后,如果能容忍后续的访问只能访问到部分或者全部访问不到,则是弱一致性。举例说明,可能你期望往ConcurrentHashMap中加入一个元素后,立马能对get可见,但ConcurrentHashMap并不能如你所愿。换句话说,put操作将一个元素加入后,get可能在某段时间内还看不到这个元素)
对于一些需要在整个Map上进行计算的方法,如size和isEmpty,这些方法的语义被略微减弱了以反映容器的并发特性。
额外的原子Map操作:
一些常见的复合操作,例如“若没有则添加”、“若相等则移除”、“若相等则替换”等,这些操作都是原子操作,不需要加锁。
1 computeIfAbsent(K key, Function<? super K,? extends V> mappingFunction) 2 computeIfPresent(K key, BiFunction<? super K,? super V,? extends V> remappingFunction) 3 putIfAbsent(K key, V value) 4 remove(Object key, Object value) 5 replace(K key, V value)
CopyOnWriteArrayList:
用于替代同步List,在某些情况下提供了更好的并发性能,并且在迭代期间不需要对容器进行加锁或是复制。Copy-On-Write的安全性在于每次修改时,都会创建并重新发布一个新的容器的副本,从而实现可变性。但是这需要一定的开销,特别是当容器的规模较大时。仅当迭代操作远多于修改操作时,才应该使用“写入时复制”容器。
4. 链表
分为单向链表(singly-linked list)和双向链表(doubly-linked list)。
首先说一下链表(linked list)和数组(Array)的区别:
①Array是静态分配内存,不能动态扩展。在插入和删除方面,开销很大,但随机访问性强,查找速度快;linked list是动态分配内存,nodes数量可以按需求增加或减少,因此,处理未知数量的对象时,应该使用linked list。虽然,它插入删除速度快,但不能随机查找。
②链表结构区别
singly-linked list:

doubly-linked list:
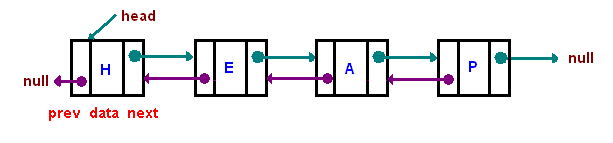
链表跟内存相比会占用更多内存,我们需花费额外的4bytes(32bitCPU中)内存来存储每个reference。
③doubly-linked list在查找和删除时利用了二分法的思想去实现,效率大大提高,但singly-linked list的应用更广泛。原因在于存储效率方面。
每个doubly-linked list的node结构比singly-linked list的多了一个指针,占用更多空间,这时设计者会以时间来换取空间,达到工程总体的平衡。
参考资料:https://www.cs.cmu.edu/~adamchik/15-121/lectures/Linked%20Lists/linked%20lists.html
5. SynchronousQueue
它有两个操作,put()和take(),这两个操作都是阻塞的。比如:当我们执行put()和,会一直阻塞到其他线程执行take()为止。队列的内部没有任何的存储容量(一个都没有),所以它不能插入数据,也不能移除数据,还不能进行迭代。newCachedThreadPool的实现,队列的部分就是使用了SysnchronousQueue。(newCachedThreadPool的特点,接收到一个新的任务就直接开启一个新的线程来执行)
1 public static ExecutorService newCachedThreadPool() { 2 return new ThreadPoolExecutor(0, Integer.MAX_VALUE, // 0代表corePoolSize Integer.MAX_VALUE代表maximumPoolSize 3 60L, TimeUnit.SECONDS, 4 new SynchronousQueue<Runnable>()); 5 }
我们先一个用公共变量来处理传递:
1 public class Demo002 { 2 3 public static void main(String args[]) throws InterruptedException { 4 ExecutorService executor = Executors.newFixedThreadPool(2); 5 AtomicInteger sharedState = new AtomicInteger(); 6 CountDownLatch countDownLatch = new CountDownLatch(1); 7 8 Runnable producer = () -> { 9 Integer producedElement = ThreadLocalRandom 10 .current() 11 .nextInt(); 12 sharedState.set(producedElement); 13 countDownLatch.countDown(); 14 }; 15 16 Runnable consumer = () -> { 17 try { 18 countDownLatch.await(); 19 Integer consumedElement = sharedState.get(); 20 } catch (InterruptedException ex) { 21 ex.printStackTrace(); 22 } 23 }; 24 25 executor.execute(producer); 26 executor.execute(consumer); 27 28 executor.awaitTermination(500, TimeUnit.MILLISECONDS); 29 executor.shutdown(); 30 System.out.println(countDownLatch.getCount()); 31 32 } 33 }
再用SysnchronousQueue处理传递:
1 public class Demo003 { 2 3 public static void main(String args[]) throws InterruptedException { 4 ExecutorService executor = Executors.newFixedThreadPool(2); 5 SynchronousQueue<Integer> queue = new SynchronousQueue<>(); 6 7 Runnable producer = () -> { 8 Integer producedElement = ThreadLocalRandom 9 .current() 10 .nextInt(); 11 try { 12 queue.put(producedElement); 13 } catch (InterruptedException e) { 14 // TODO Auto-generated catch block 15 e.printStackTrace(); 16 } 17 }; 18 19 Runnable consumer = () -> { 20 try { 21 Integer consumedElement = queue.take(); 22 } catch (InterruptedException ex) { 23 ex.printStackTrace(); 24 } 25 }; 26 27 executor.execute(producer); 28 executor.execute(consumer); 29 30 executor.awaitTermination(500, TimeUnit.MILLISECONDS); 31 executor.shutdown(); 32 System.out.println(queue.size()); 33 34 } 35 }
至此,我们看到了它的构造,用例子阐述了它的使用方法,SynchronousQueue服务于一个交换点,这个交换点用于生产者和消费者的协作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号