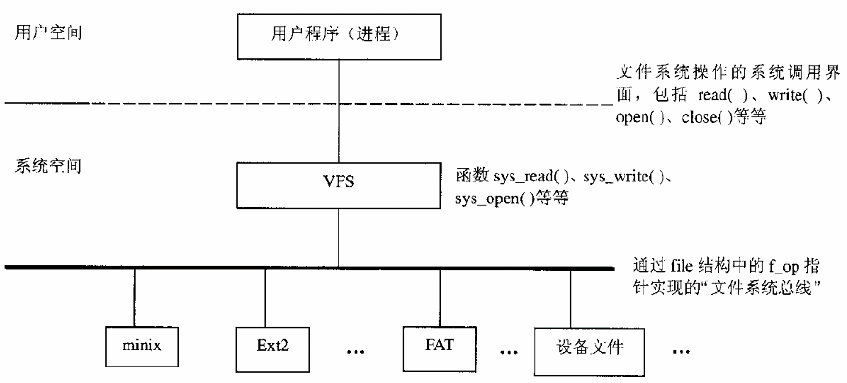
Linux内核文件系统概述
1、设计人员很早就注意到了如何使Linux支持其他各种不同文件系统的问题。要实现这个目的,就要将对各种不同文件系统的操作和管理纳入到一个统一的框架中。让内核中的文件系统界面成为一条文件系统“总线”,使得用户程序可以通过同一个文件系统操作界面,也就是同一组系统调用,对各种不同的文件系统(以及文件)进行操作。这样,就可以对用户程序隐去各种不同文件系统的实现细节,为用户程序提供一个统一的、抽象的、虚拟的文件系统界面,这就是所谓“虚拟文件系统”VFS。这个抽象的界面主要由一组标准的、抽象的文件系统构成,以系统调用的形式提供于用户程序,如read()、write()、lseek()等等。这样,用户程序就可以把所有的文件都看作一致的、抽象的“VFS文件”,通过这些系统调用对文件进行操作,而无需关心具体的文件属于什么文件系统以及具体文件系统的设计和实现。
2、不同的文件系统通过不同的程序来实现其各种功能,但是与VFS之间的界面则是有明确定义的。这个界面的主体就是一个file_operations数据结构。
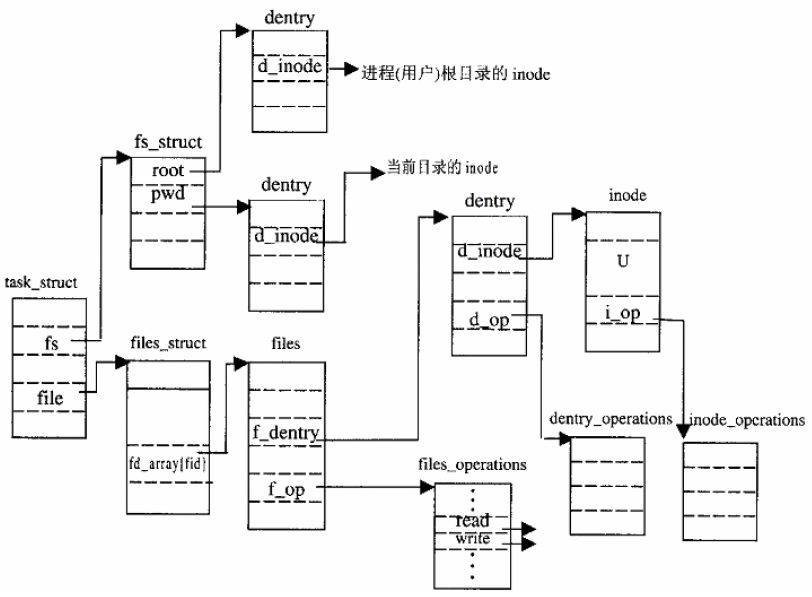
3、进程与文件的连接,即“已打开文件”,是进程的一项“财产”,归具体的进程所有。代表着这种连接的file结构必然与代表着进程的task_struct数据结构存在着联系。
4、file结构中还有个指针f_dentry,指向该文件的dentry数据结构。那么,为什么不干脆把文件的dentry结构放在file结构里面,而只是让file结构通过指针来指向它呢?这是因为一个文件只有一个dentry数据结构,而可能有多个进程打开它,甚至同一个进程也可能多次打开它而建立起多个读写上下文。同理,每种文件系统只有一个file_operations数据结构,它既不专属于某个特定的文件,更不专属于某个特定的上下文。
5、dentry结构所代表的是逻辑意义上的文件,记录的是其逻辑上的属性。而inode结构所代表的是物理意义上的文件,记录的是其物理上的属性;它们之间的关系是多对一的关系。
6、特殊文件在内存中也有inode数据结构和dentry数据结构,但是不一定在存储介质上有索引节点和目录项。特殊文件一般都与外部设备无关,所涉及的介质通常就是内存以及CPU本身。当从一特殊文件“读”时,所读出的数据都是由系统内部按一定的规则临时生成出来的,或者从内存中收集、加工出来的,反之亦然。
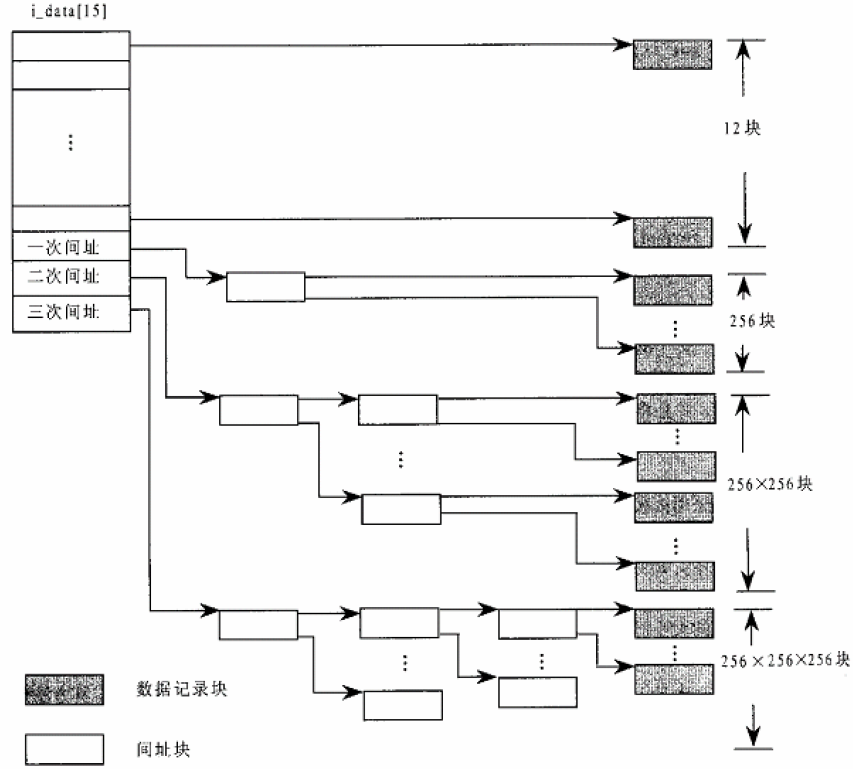
7、所谓inode,也就是“索引节点”(或称“i节点”)的意思。要“访问”一个文件时,一定要通过它的索引才能知道这个文件是什么类型的文件、是怎么组织的、文件中存储着多少数据、这些数据在什么地方以及其下层的驱动程序在哪儿等必要的信息。
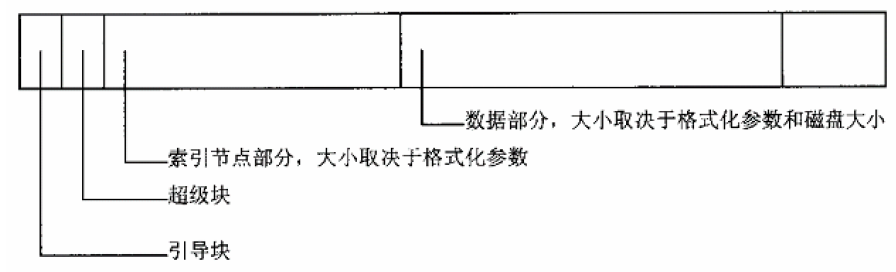
8、以Ext2格式为例,磁盘上的记录块(扇区)主要分为两部分,一部分用于索引节点,一部分用于文件的数据。给定一个索引节点号,就可以通过磁盘的设备驱动程序将其所在的记录块读入内存中。
9、要访问一个文件就得先访问一个目录,才能根据文件名从目录中找到该文件的目录项,进而找到其i节点;可是目录本身也是文件,它本身的目录项又在另一个目录项中,这一来不是成了“先有鸡还是先有蛋”的问题,或者说递归了吗?这个圈子的出口在哪儿呢?我们不妨换一个方式来问这个问题,那就是:是否有这样一个目录,它本身的“目录项”不在其它目录中,而可以在一个固定的位置上或者通过一个固定的算法找到,并且从这个目录出发可以找到系统中的任何一个文件?答案是肯定的,这个目录就是系统的根目录“/”,或者说“根设备”上的根目录。每一个“文件系统”,即每一个格式化成某种文件系统的存储设备上都有一个根目录,同时又都有一个“超级块”,根目录的位置以及文件系统的其他一些参数就记录在超级块中。超级块在设备上的逻辑位置都是固定的,例如,在磁盘上总是在第二个逻辑块(第一个逻辑块为引导快),所以不需要再从其他什么地方去“查找”。同时,对于一个特定的文件系统,超级块的格式也是固定的,系统在初始化时要将一个存储设备(通常就是从中引导出操作系统的那个设备)作为整个系统的“根设备”,它的根目录就成为整个文件系统的“总根”,就是“/”。更确切地说,就是把根设备的根目录“安装”在文件系统的总根“/”节点上。有了根设备以后,还可以进而把其他存储设备也安装到文件系统中空闲的目录节点上。所谓“安装”,就是从一个存储设备上读入超级块,在内存中建立起一个super_block结构。再进而将此设备上的根目录与文件系统中已经存在的一个空白目录挂上钩。系统初始化时整个文件系统只有一个空白目录“/”,所以根设备的根目录就安装在这个节点上。这样,从根目录“/”开始,根据给定的“全路径名”就可以找到文件系统中的任何一个文件。而不论这个文件是在哪一个存储设备上,只要文件所在的存储设备已经安装就行了。
10、/bin/su是个属于超级用户的“set uid”可执行程序,普通用户的进程在执行这个程序时就有了超级用户的“身份”。在检查了口令以后,它就fork()出一个新的shell进程。这个新shell进程的父进程具有超级用户的身份,所以它也成了超级用户进程。至于原来的shell进程和su进程,则都在睡眠等待(直至新的shell进程exit())。从效果上看,就好像新的shell进程从原来的shell进程手中“接管”了终端的键盘和显示屏;而从用户界面来看,则似乎原来的shell进程“升格”成了超级用户进程。
11、系统引导之初,设备上的文件和节点都还是不可访问的。也就是说,还不能按一定的路径名访问其中特定的节点或文件。只有把它“安装”到计算机系统的文件系统中某个节点上,才能使设备上的文件和节点成为可访问的。经过安装以后,设备上的“文件系统”就成为整个文件系统的一部分,或者说一个子系统。
12、最初时,整个系统中只有一个节点,那就是整个文件系统的“根”节点“/”,这个节点存在于内存中,而不在任何具体的设备上。系统在初始化时将一个“根设备”安装到节点“/”上,这个设备上的文件系统就成了整个系统中原始的、基本的文件系统。此后,就可以由超级用户进程通过系统调用mount()把其它的子系统安装到已经存在于文件系统的空闲节点上,使整个文件系统得以扩展,当不再需要使用某个子系统时,或者在关闭系统之前,则通过系统调用umount()把已经安装的设备逐个“拆卸”下来。
13、有些虚拟的文件系统(如pipe、共享内存区等),要由内核通过kern_mount()安装,而根本不允许由用户进程通过系统调用mount()来安装。这样的文件系统类型在其fs_flag中的FS_NOMOUNT标志位为1。虚拟文件系统类型的“设备”其实没有超级块,所以只是按特定的内容初始化,或者说生成一个super_block结构。
14、在inode数据结构中有两个设备号。一个是索引节点所在设备的号码i_dev,另一个是索引节点所代表的设备的号码i_rdev。
15、/proc虚拟文件系统下的主要内容有:

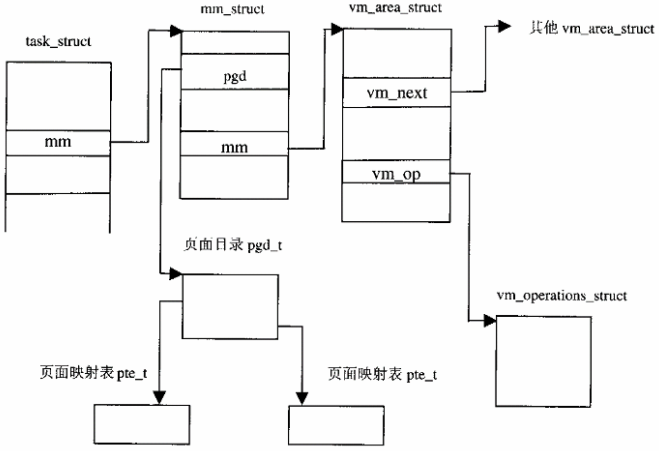
16、mm_struct结构及其属下的各个vm_area_struct只是表明了对虚存空间的需求。一个虚拟地址有相应的虚存区间存在,并不保证该地址所在的页面已经映射到某一个物理(内存或盘区)页面,更不保证该页面就在内存中。当一个未经映射的页面受到访问时,就会产生一个“Page Fault”异常(也称缺页异常、缺页中断),那时候Page Fault异常的服务程序就会来处理这个问题。所以,从这个意义上,mm_struct和vm_area_struct说明了对页面的需求;前面的page、zone_struct等结构则说明了对页面的供应;而页面目录、中间目录以及页面表则是二者中间的桥梁。
17、物理内存页面换入/换出的周转要点如下:
1)空闲。页面的page数据结构通过其队列头结构list链入某个页面管理区(zone)的空闲区队列free_area。页面的使用技术count为0。
2)分配。通过函数__alloc_pages()或__get_free_page()从某个空闲队列中分配内存页面,并将所分配页面的使用技术count置成1,其page数据结构的队列头list结构则变成空闲。
3)活跃状态。页面的page数据结构通过其队列头结构lru链入活跃页面队列active_list,并且至少有一个进程的(用户空间)页面表项指向该页面。每当为页面建立或恢复映射时,都使页面的使用技术count加1。
4)不活跃状态(脏)。页面的page数据结构通过其队列头结构lru链入不活跃“脏”页面队列inactive_dirty_list,但是原则上不再有任何进程的页面表项指向该页面。每当断开页面的映射时都使页面的使用技术count减1。
5)将不活跃“脏”页面的内容写入交换设备,并将页面的page数据结构从不活跃“脏”页面队列inactive_dirty_list转移到某个不活跃“干净”页面队列中。
6)不活跃状态(干净)。页面的page数据结构通过其队列头结构lru链入某个不活跃“干净”页面队列,每个页面管理区都有一个不活跃“干净”页面队列inactive_clean_list。
7)如果在转入不活跃状态以后的一段时间内页面受到访问,则又转入活跃状态并恢复映射。
8)当有需要时,就从“干净”页面队列中回收页面,或退回到空闲队列中,或直接另行分配。
18、内核怎样管理每个进程的3G字节虚存空间呢?粗略地说,用户程序经过编译、连接形成的映象文件中有一个代码段和一个数据段(包括data段和bss段),其中代码段在下,数据段在上。数据段中包括了所有静态分配的数据空间,包括全局变量和说明为static的局部变量。这些空间是进程所必须的基本要求,所以内核在建立一个进程的运行映象时就分配好这些空间,包括虚存地址区间和物理页面,并建立好二者间的映射。除此之外,堆栈使用的空间也属于基本要求,所以也是在建立进程时就分配好的(但可以扩充)。所不同的是,堆栈中间安置在虚存空间的顶部,运行时由顶向下延伸;代码段和数据段则在底部,在运行时并不向上伸展。而从数据段的顶部end_data到堆栈段地址的下沿这个中间区域则是一个巨大的空洞,这就是可以在运行时动态分配的空间。最初,这个动态分配空间是从进程的end_data开始的,这个地址为内核和进程所共知。以后,每次动态分配一块“内存”,这个边界就往上推进一段距离,同时内核和进程都要记下当前的边界在哪里。在进程这一边由malloc()或类似的库函数管理,而在内核中则将当前的边界记录在进程的mm_struct结构中。具体地说,mm_struct结构中有一个成分brk,表示动态分配区当前的底部。当一个进程需要分配内存时,将要求的大小与其当前的动态分配区底部边界相加,所得的就是所要求的新边界,也就是brk()调用时的参数brk。当内核能满足要求时,系统调用brk()返回0,此后新旧两个边界之间的虚存地址就都可以使用了。当内核发现无法满足要求,或者发现新的边界已经过了逼近设于顶部的堆栈时,就拒绝分配而返回-1。
19、一个进程可以通过系统调用mmap()将一个文件映射到它的用户空间。建立了这样的映射以后,就可以像访问内存一样地访问这个文件,如果将文件的内容以页面为单位缓冲,放在附属于该文件的inode结构的缓冲队列中,那么只要相应地设置进程的内存映射表,就可以很自然地将这些缓冲页面映射到进程的用户空间中。这样,在按常规的文件操作访问一个文件时,可以通过read()和write()系统调用目标文件的inode结构访问这些缓冲页面;而通过内存映射机制访问这个文件时,就可以经由页面映射表直接读写这些缓冲着的页面。当目标文件不在内存内中,常规的文件操作通过系统调用read()、write()的底层将其从设备上读入,而通过内存映射机制访问这个文件时则由“缺页异常”的服务程序将目标页面从设备上读入。也就是说,同一个缓冲页面可以满足两方面的要求,文件系统的缓冲机制和文件的内存映射机制巧妙地结合在一起了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号