

强化学习-策略迭代
参考:
(1)强化学习(第二版)
(2)强化学习精要-核心算法与TensorFlow实现
一、策略迭代
1、策略评估
给定策略,计算其价值函数,即为策略评估,有时也称其为预测问题。
方法:根据的贝尔曼方程不断迭代直至收敛。

2、策略改进
求解最优的策略和价值函数,即为策略改进,有时也称其为控制问题。
策略改进定理:如果对于任意,,那么策略不会比策略差(一样好或者更好)。
构造一个贪心策略来满足策略改进定理:
可知通过执行这种贪心算法,我们就可以得到一个更好的策略。
3、策略迭代算法流程
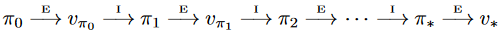

二、策略迭代实例
1、游戏背景介绍
100个格子的棋盘,起始位置为1,终点位置为100。在每个位置上,玩家可以有2种选择,第一种选择是投掷一个包含点数1-3的骰子,第二种选择是投掷一个包含点数1-6的骰子,投掷的点数即行进的步数。如果当前的位置加上行进的步数超过100,则需回退。第100个格子的奖励为100,其余格子的奖励均为-1。特别的,棋盘上包含10个梯子,这些梯子即可能是上升的,也可能是下降的,例如,一个梯子可能使玩家从第50个格子到达第80个格子,也可能使玩家从第70个格子到达第20个格子。玩家的目的是尽快地到达终点(获得的奖励最多)。
2、代码实现

import numpy as np import gym from gym.spaces import Discrete from contextlib import contextmanager import time class SnakeEnv(gym.Env): #棋格数 SIZE = 100 def __init__(self, dices): #动作上限列表 self.dices = dices #梯子 self.ladders = {82: 52, 52: 92, 26: 66, 98: 22, 14: 22, 96: 63, 35: 12, 54: 78, 76: 57} #状态空间 self.observation_space = Discrete(self.SIZE + 1) #动作空间 self.action_space = Discrete(len(dices)) #初始位置 self.pos = 1 def reset(self): self.pos = 1 return self.pos def step(self, a): step = np.random.randint(1, self.dices[a] + 1) self.pos += step #到达终点,结束游戏 if self.pos == 100: return 100, 100, 1, {} #超过终点位置,回退 elif self.pos > 100: self.pos = 200 - self.pos if self.pos in self.ladders: self.pos = self.ladders[self.pos] return self.pos, -1, 0, {} def reward(self, s): if s == 100: return 100 else: return -1 def render(self): pass class TableAgent(): def __init__(self, env): #状态空间数 self.s_len = env.observation_space.n #动作空间数 self.a_len = env.action_space.n #每个状态的奖励 self.r = [env.reward(s) for s in range(0, self.s_len)] #策略(初始时每个状态只采取第一个策略) self.pi = np.array([0 for s in range(0, self.s_len)]) #状态转移概率 self.p = np.zeros([self.s_len, self.a_len, self.s_len], 'float') ladder_move = np.vectorize(lambda x: env.ladders[x] if x in env.ladders else x) for src in range(1, 100): for i, dice in enumerate(env.dices): prob = 1 / dice step = np.arange(1, dice + 1) step += src step = np.piecewise(step, [step > 100, step <= 100], [lambda x: 200 - x, lambda x: x]) step = ladder_move(step) for dst in step: self.p[src, i, dst] += prob #状态价值函数 self.value_pi = np.zeros((self.s_len)) #状态-动作价值函数 self.value_q = np.zeros((self.s_len, self.a_len)) #打折率 self.gamma = 0.8 def play(self, state): return self.pi[state] class PolicyIteration(): def __init__(self): pass def policy_evaluation(self, agent): while True: f = 0 for i in range(1, agent.s_len): ac = agent.pi[i] transition = agent.p[i, ac, :] d = agent.value_pi[i] #通过迭代使状态价值函数收敛 agent.value_pi[i] = np.dot(transition, agent.r + agent.gamma * agent.value_pi) f = max(f, abs(agent.value_pi[i] - d)) if f < 1e-6: break def policy_improvement(self, agent): new_policy = np.zeros_like(agent.pi) for i in range(1, agent.s_len): for j in range(0, agent.a_len): #计算动作价值函数 agent.value_q[i, j] = np.dot(agent.p[i, j, :], agent.r + agent.gamma * agent.value_pi) #策略改进 max_act = np.argmax(agent.value_q[i, :]) new_policy[i] = max_act if np.all(np.equal(new_policy, agent.pi)): return False else: agent.pi = new_policy return True def policy_iteration(self, agent): iteration = 0 while True: iteration += 1 self.policy_evaluation(agent) ret = self.policy_improvement(agent) if not ret: break print('Iter {} rounds converge'.format(iteration)) def eval_game(env, policy): state = env.reset() return_val = 0 for epoch in range(100): while True: if isinstance(policy, TableAgent): act = policy.play(state) elif isinstance(policy, list): act = policy[state] else: raise IOError('Illegal policy') state, reward, terminate, _ = env.step(act) return_val += reward if terminate: break return return_val / 100 def policy_iteration_demo(): env = SnakeEnv([3, 6]) agent = TableAgent(env) pi_algo = PolicyIteration() pi_algo.policy_iteration(agent) print('pi avg = {}'.format(eval_game(env, agent))) print(agent.pi) policy_iteration_demo()
3、运行结果



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!