【Kaggle竞赛】树叶分类任务
本文kaggle链接
本篇博客将记录,我在学习d2l过程中的树叶分类任务的心路历程。从开始做这个比赛已经四五天了,原本打算将代码分为几个部分:载入数据集,网络结构,训练函数,测试。这四个部分,当我把这四个部分写完,开始训练的时候,发现loss死活不下降,保持在一个稳定的数值,让我百思不得其解。
于是我开始寻找问题所在,从网络架构,到训练函数,再到数据增强部分。
我用别人完成了的训练函数,来训练我的网络,还是保持不变,排除训练函数的问题;
我用别人的网络,用我自己的训练函数,还是保持不变,则排除了网络的问题;
…
测试来测试去,终于我的loss下降了???
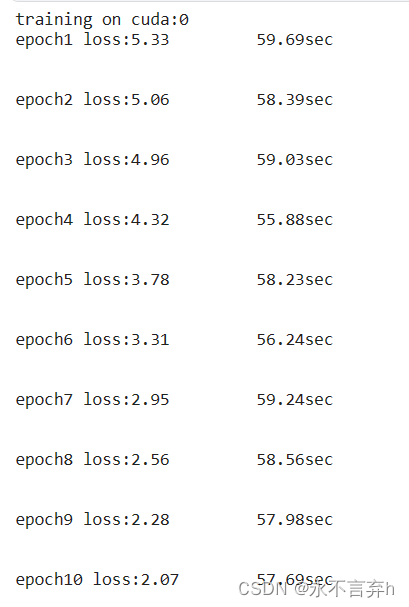
最终定位问题:载入数据集/构建自己的dataset/重写dataset类
构建数据集(重写Dataset类)#
这里我们需要写三个类方法,一个classes方法返回输入data中的全部176个标签,len函数返回数据集的长度或大小,getitem函数将数据集中指定idx索引下的图片以及标签读取,如果是训练就做数据增强,如果不是训练就不做数据增强,最后返回图片和标签。
class CustomDataset(Dataset):
def __init__(self,csv_file,root_dir,transform=None,is_test=False):
super().__init__()
self.data = csv_file
self.root_dir = root_dir
self.transform = transform
self.is_test = is_test
@property
def classes(self):
# 获取数据集的标签列表独一无二的
return self.data.iloc[:,1].unique().tolist()
def __len__(self):
return len(self.data)
def test(self):
return self.data
def __getitem__(self,idx):
# ./classify-leaves/images/0.jpg
img_path = os.path.join(self.root_dir,self.data.iloc[idx,0])
image = Image.open(img_path)
if self.transform:
# 训练是做图片增强
image = self.transform(image)
if self.is_test:
return image
label = self.data.iloc[idx, 2]
label = torch.tensor(label)
return image,label
def load_dataset(batch_size,img_size):
# 数据预处理
train_transforms = transforms.Compose([
transforms.Resize(img_size),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.ToTensor(),
]
)
test_transforms = transforms.Compose([
transforms.Resize(img_size),
transforms.ToTensor(),
])
# 输入相关的目录,载入训练标签表
root_folder = "/kaggle/input/classify-leaves"
train_csv = pd.read_csv("/kaggle/input/classify-leaves/train.csv")
test_csv = pd.read_csv("/kaggle/input/classify-leaves/test.csv")
# 将标签进行都热编码
leaves_labels = train_csv.iloc[:,1].unique()
n_classes = len(leaves_labels)
class_to_num = dict(zip(leaves_labels,range(n_classes)))
num_to_class = dict(zip(class_to_num.values(), class_to_num.keys()))
# 将class_to_num 保存到本地
with open('/kaggle/working/class_to_num.txt', 'w') as json_file0:
json.dump(class_to_num, json_file0)
with open('/kaggle/working/num_to_class.txt', 'w') as json_file1:
json.dump(num_to_class, json_file1)
train_csv["labelEncode"] = train_csv.iloc[:,1].map(class_to_num)
# 获取两个数据集 一个是训练数据集 第二个是预测数据集(用于提交)
full_dataset = CustomDataset(train_csv,root_folder,transform=train_transforms)
predict_dataset = CustomDataset(test_csv,root_folder,transform=test_transforms,is_test =True)
# 拆分训练数据集 一部分用来训练,另一部分用来验证
train_size = int(0.9 * len(full_dataset))
test_size = len(full_dataset) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(full_dataset, [train_size, test_size])
# 将实例化的数据集放入dataloader迭代器
train_dataloader = DataLoader(train_dataset,batch_size = batch_size,shuffle=True)
test_dataloader = DataLoader(train_dataset,batch_size = batch_size,shuffle=True)
dataloaders = {"train":train_dataloader,"test":test_dataloader}
return dataloaders,full_dataset.classes,predict_dataset,class_to_num,num_to_class
训练函数#
d2l.argmax()是将输出的y_hat全部转换成176个都热编码数字。
其实argmax()回去的是axis=1最大值的索引,正好与176个分类的编码一样
def evaluate_accuracy_gpu(net, data_iter, device=None):
# 计算精度函数
with torch.no_grad():
all_acc = []
for X, y in data_iter:
X, y = X.to(device),y.to(device)
y_hat = net(X)
y_hat = d2l.argmax(y_hat, axis=1)
ture = y_hat == y
acc = ture.sum()/ture.shape[0]
all_acc.append(acc)
return sum(all_acc)/len(all_acc)
这里我们构建的数据集需要通过dataloader["train"]来访问到训练集,训练集已经分开一部分用来训练,另一部分用来验证。
def train(net,dataloaders,num_epochs,lr,device):
# 对全权值做初始化 正太分布
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
# nn.init.normal_(m.weight, mean=0.0, std=1.0)
# nn.init.uniform_(m.weight, a=0, b=1)
# nn.init.zeros_(m.weight)
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
print('training on', device)
net.to(device)
opt = torch.optim.Adam(net.parameters(), lr=lr)
# 损失函数
loss = nn.CrossEntropyLoss()
# 第epoch轮训练
for epoch in range(num_epochs):
net.train()
timer = d2l.Timer()
epoch_loss = []
for i ,(X,y) in enumerate(dataloaders['train']):
opt.zero_grad() # 梯度清0
X, y = X.to(device),y.to(device)
y_hat = net(X)
l = loss(y_hat,y)
epoch_loss.append(l)
l.backward()
opt.step()
# 打印每一个epoch的loss损失
# print(epoch_loss)
temp_loss = float(sum(epoch_loss)/len(epoch_loss))
# 数据可视化
epoch_test_acc = evaluate_accuracy_gpu(net,dataloaders['test'],d2l.try_gpu()) # 计算测试精度
epoch_train_acc = evaluate_accuracy_gpu(net,dataloaders['train'],d2l.try_gpu()) # 计算测试精度
print(f"epoch{epoch+1} loss:{float(sum(epoch_loss)/len(epoch_loss)):.2f}","\t",
f"train_acc:{epoch_train_acc:.2f}","\t",
f"test_acc:{epoch_test_acc:.2f}","\t",
f"{timer.stop():.2f}sec")
epoch_loss = []
print("\n")
获取模型#
这里我本来是打算用resnet152,但是好像读不进去,所以用来101层的resnet,我也不知道为什么。
这里我们修改了一下线性层的输出层。
import torchvision.models as models
net = models.resnet101()
net.fc = nn.Linear(2048, 176)
开始训练#
torch.cuda.empty_cache()
num_epochs,lr,batch_size,img_size = 100,0.01,32,256
dataloaders,class_names,predict_dataset,class_to_num,num_to_class = load_dataset(batch_size,img_size)
torch.cuda.empty_cache()
train(net,dataloaders,num_epochs,lr,d2l.try_gpu())
训练结果#
最后没有跑完完整的100个epoch,kaggle gpu的额度不够了当时。
epoch1 loss:5.38 train_acc:0.03 test_acc:0.04 520.49sec
........
epoch83 loss:0.09 train_acc:0.98 test_acc:0.98 503.97sec
epoch84 loss:0.07 train_acc:0.97 test_acc:0.97 504.12sec
得分结果#
感觉才0.88有点低。

采用多GPU训练方式#
根据d2l课程,我们将训练函数做一点修改
net = nn.DataParallel(net, device_ids=devices).cuda()将网络通过DataParallel的方法自动分割到多个GPU上。
这里我有个疑问?把数据和标签放到GPU0上那岂不是计算都在GPU0上了吗,为什么不需要将数据和标签放在GPU1上呢。
def evaluate_accuracy_gpu(net, data_iter,device=None):
# 计算精度函数
with torch.no_grad():
all_acc = []
for X, y in data_iter:
X, y = X.to(device),y.to(device)
y_hat = net(X)
y_hat = d2l.argmax(y_hat, axis=1)
ture = y_hat == y
acc = ture.sum()/ture.shape[0]
all_acc.append(acc)
return sum(all_acc)/len(all_acc)
def train(net,num_gpus,dataloaders,num_epochs,lr):
devices = [d2l.try_gpu(i) for i in range(num_gpus)]
# 对全权值做初始化 正太分布
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
# nn.init.normal_(m.weight, mean=0.0, std=1.0)
# nn.init.uniform_(m.weight, a=0, b=1)
# nn.init.zeros_(m.weight)
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
net = nn.DataParallel(net, device_ids=devices).cuda()
print('training on', devices)
# net.to(device)
opt = torch.optim.Adam(net.parameters(), lr=lr)
# 损失函数
loss = nn.CrossEntropyLoss()
# 第epoch轮训练
for epoch in range(num_epochs):
net.train()
timer = d2l.Timer()
epoch_loss = []
for i ,(X,y) in enumerate(dataloaders['train']):
opt.zero_grad() # 梯度清0
X, y = X.to(devices[0]), y.to(devices[0])
# y_hat = net(X)
l = loss(net(X),y)
epoch_loss.append(l)
l.backward()
opt.step()
# 打印每一个epoch的loss损失
# print(epoch_loss)
temp_loss = float(sum(epoch_loss)/len(epoch_loss))
# 数据可视化
epoch_test_acc = evaluate_accuracy_gpu(net,dataloaders['test'],d2l.try_gpu()) # 计算测试精度
epoch_train_acc = evaluate_accuracy_gpu(net,dataloaders['train'],d2l.try_gpu()) # 计算测试精度
print(f"epoch{epoch+1} loss:{float(sum(epoch_loss)/len(epoch_loss)):.2f}","\t",
f"train_acc:{epoch_train_acc:.2f}","\t",
f"test_acc:{epoch_test_acc:.2f}","\t",
f"{timer.stop():.2f}sec")
epoch_loss = []
print("\n")
采用resnet152进行训练#
之前采用152层老是溢出,于是我加了torch.cuda.empty_cache()用来情况GPU的显存。
参考博客#
https://www.kaggle.com/code/licgsg/classify-leaves-resnet18/notebook
作者:liguochun
出处:https://www.cnblogs.com/liguochun0304/p/17997902
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 25岁的心里话
· 按钮权限的设计及实现