深度学习(四)RNN & Word2Vec
RNN(Recurrent Netural Network)循环神经网络,用来处理和预测序列数据,在语音识别,语言描述,翻译等领域有很好的运用。
传统神经网络结构如CNN是假设所有的input之间是相互独立的,output之间也相互独立,但实际中会存在由前面几个字去推测后面的词,这个时候CNN的假设就不能成立了。
而RNN可以通过时序结构来关联input,记住input之间的关系。
RNN的典型结构如下:

展开之后为:
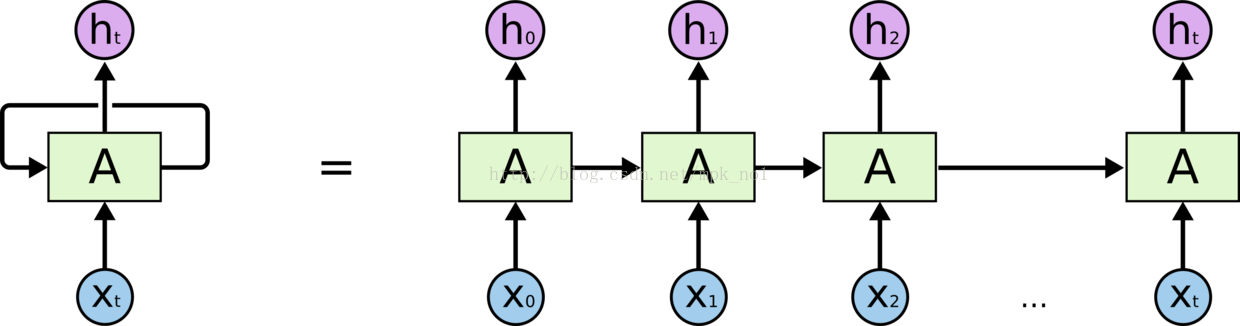
可以看到隐藏层的输入有两个:隐藏层的输入(前一个隐藏层的输出 h)以及原始输入(指某个词的vector x)
具体例子如下:
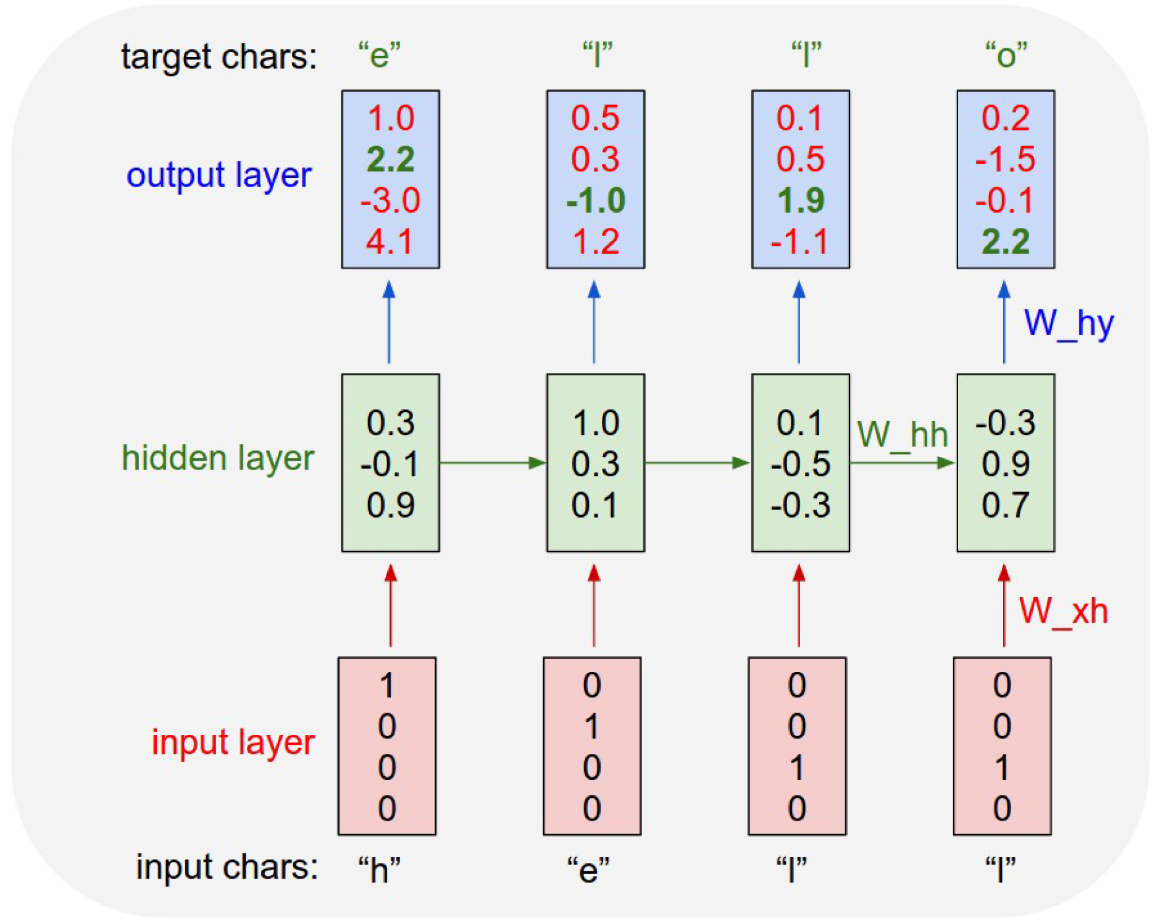
RNN模型中有个time step的概念,表示记忆的长度,例子中的记忆长度就是4.
但是RNN无法解决长时间依赖的问题,也就是记忆长度不能特别长(容易出现梯度弥散的问题),因此出现了一些改进版的RNN,如LSTM(Long short term memory)
两者的结构对比图如下:
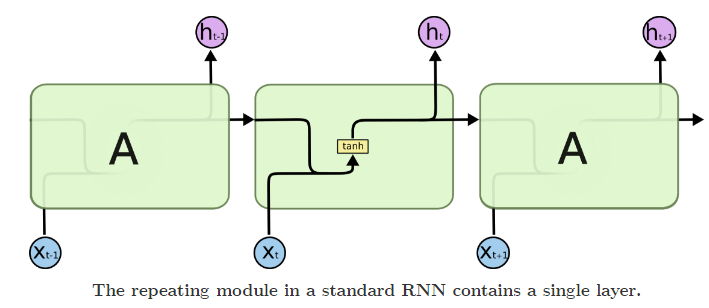
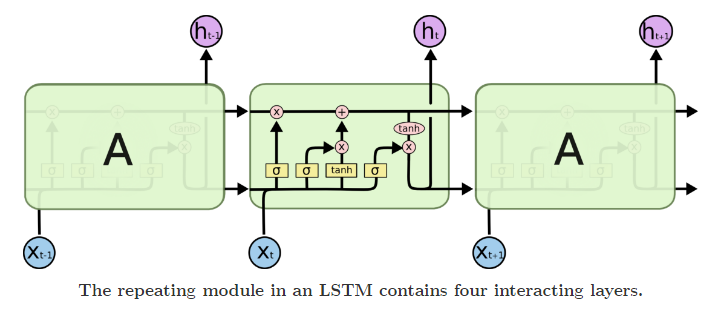
从对比图上可以看出,所有RNN都具有一个重复模块,标准RNN重复模板是比较简单的tanh,而LSTM则是由通过精心设计的称作“门”的结构来去除或者增加信息。
(1)清除无用信息 (遗忘门 forget gate)

(2)添加新的信息
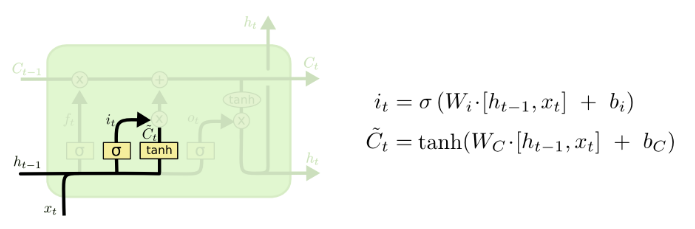
(3)更新细胞状态
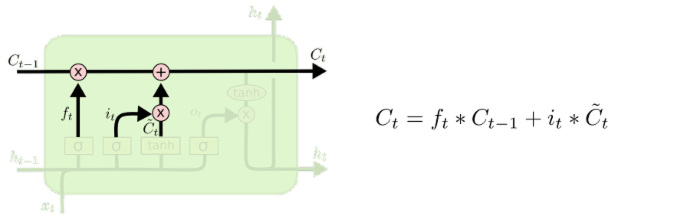
(4)输出信息
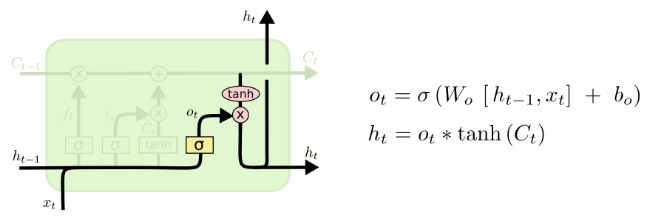
以上便展示了LSTM的几个重要计算逻辑。
在现实中,我们用的训练数据往往是句子或者词组,因此需要先做一些处理,下面介绍几个句子处理中的常见概念
(1)词向量(把一个词转换成一个向量)
a. one hot representation
用一个很长向量表示一个词,向量长度是词典长度,向量中只有元素0和1,1的位置对应词在词典中的位置
这种方法在NLP中运用的比较多,但也有明显的问题:维度灾难和无法刻画近义词之间的相似性
b. distributed representation
以普通向量表示一个词,一般是50维或者100维 (??? how),可以认为是Word embedding(词嵌入)??
(2)Word2Vec (google提出的基于word embedding的工具或者算法集合)
本质上是构造多层神经网络,input是one-hot vector,通过hidden layer(lookup table)找到对应的vector,在训练过程中不断修正参数,具体图如下:
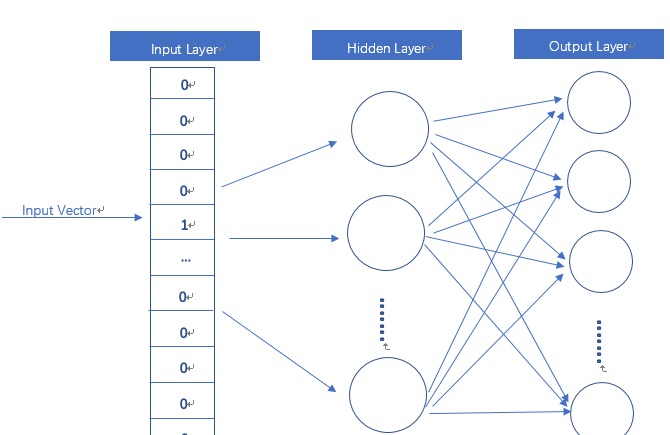
计算过程如下:

这样一个one hot vector被转换成dense vector,而且维度降低
Word2Vec的主要模式:
a. CBOW(Continuous Bag of Words), 从当前词的上下文推测当前词语,对小型数据库比较适合
b. Skip-gram 从当前词语推测词语的上下文
举例如下:
There is a little dog.
CBOW: [There, a] -> [is], [is, little] -> [a], [a, dog] -> [little]
Skip-gram:(skip1) [is] -> [There], [is] -> a, [a] -> [is], [a] -> [little] ....
c. 复杂度分析 (未完待续)
Word2Vec的主要步骤(未完待续)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号