LangMem
LangMem
https://blog.langchain.dev/langmem-sdk-launch/
On memory and adaptive agents
Agents use memory to learn, but the way their memories are formed, stored, updated, and retrieved impacts types of things your agent can learn to know or do. At LangChain, we’ve found it useful to first identify the capabilities your agent needs to be able to learn, map these to specific memory types or approaches, and only then implement them in your agent. Before adding memory, we think you should consider:
- What behavior should be learned (user-informed) vs. pre-defined?
- What types of knowledge or facts should be tracked?
- What conditions should trigger a memory to be recalled?
While there may be some overlap, each memory type serves distinct functions when building adaptive agents:
Memory Type Purpose Agent Example Human Example Typical Storage Pattern Semantic Facts & Knowledge User preferences; knowledge triplets Knowing Python is a programming language Profile or Collection Episodic Past Experiences Few-shot examples; Summaries of past conversations Remembering your first day at work Collection Procedural System Behavior Core personality and response patterns Knowing how to ride a bicycle Prompt rules or Collection
All of these memory types are meant to address recall beyond individual conversations. Memory within a given conversation, or thread, is already handled reasonably well using checkpointing in LangGraph (so long as it doesn’t extend beyond the model’s effective context window), which serves as the “short-term” or “working” memory system for your agent.
Note that this also differs from standard RAG in a couple ways. One is the way the information is gained: through interaction rather than offline data ingestion. The other is in the type of information that’s prioritized. Below, we will share more about the memory types in more detail.
Semantic memory: facts
Semantic memory stores key facts (and their relationships) and other information that ground an agent's responses. It lets your agent remember important details that wouldn’t be “pre-trained” into the model itself and that isn’t accessible from a web search or generic retriever.
Code
memories = [ ExtractedMemory( id="27e96a9d-8e53-4031-865e-5ec50c1f7ad5", content=Memory( content="Alice manages the ML team and mentors Bob, who is also on the team." ), ), ExtractedMemory( id="e2f6b646-cdf1-4be1-bb40-0fd91d25d00f", content=Memory( content="Bob now leads the ML team and the NLP project." ), ), ]In our experience, semantic memory is the most common form of “memory” that engineers ask for and imagine (after, perhaps, short-term “conversation history” memory) when they first seek to add a memory layer.
It also (debatably) has the most overlap with traditional RAG systems. If the knowledge is available from another store (docs site, codebase, etc.), and if that store is the source of truth (rather than the interactions themselves), then your agent may work fine simply retrieving over that knowledge corpus directly. Or you can periodically ingest that knowledge to integrate that in the semantic memory system. If the knowledge is regarding personalization (about the user) or conceptual relationships not found in the raw materials, then semantic memory is perfect for you.
Procedural memory: evolving behavior
Procedural memory represents internalized knowledge of how to perform tasks. It is distinct from episodic memory in that it focuses on generalized skills, rules, and behaviors. For AI agents, procedural memory is saved across a combination of model weights, agent code, and agent's prompt that collectively determine the agent's functionality. In LangMem, we focus on saving learned procedures as updated instructions in the agent's prompt.
Code
""" You are a helpful assistant.. If the user asks about astronomy, explain topics clearly using real-world examples and current scientific data. Use visual references when helpful and adapt to the user's knowledge level. Balance practical observational astronomy with theoretical concepts, providing either viewing advice or technical explanations based on user needs. """The optimizer is prompted with identifying patterns in successful and unsuccessful interactions, then updating the system prompt to reinforce effective behaviors. This creates a feedback loop where the agent's core instructions evolve based on observed performance.
Informed by our work on prompt optimization, LangMem provides multiple algorithms for generating prompt update proposals, including:
metapromptuses reflection & additional “thinking” time to study the conversations and then use a meta-prompt to propose the update;gradientexplicitly divides the work into separate steps of critique and prompt proposals to further simplify the task at each step; and a simpleprompt_memoryalgorithm that attempts to do the above in a single step.Episodic memory: events and experiences
Episodic memory stores memories of past interactions. It is distinct from procedural memory in its focus on recalling specific experiences. It is distinguished from semantic memory in its focus on past events rather than general knowledge, answering “how” the agent solved a particular problem rather than just “what” the answer was. It often takes the form of few-shot examples, with each example distilled from a longer raw interaction. LangMem doesn't yet support opinionated utilities for episodic memory.
视频
https://www.bilibili.com/video/BV1yLPieVEvo/?spm_id_from=333.337.search-card.all.click&vd_source=57e261300f39bf692de396b55bf8c41b
Lang
Chain Chain系列可以说是现在最认真且坚持在不断改进的项目了,最近一直在思考现在Agent与LLM的边界在哪里。关于最近letta和
https://langchain-ai.github.io/langmem/
LangMem helps agents learn and adapt from their interactions over time.
It provides tooling to extract important information from conversations, optimize agent behavior through prompt refinement, and maintain long-term memory.
It offers both functional primitives you can use with any storage system and native integration with LangGraph's storage layer.
This lets your agents continuously improve, personalize their responses, and maintain consistent behavior across sessions.
Key features¶
- 🧩 Core memory API that works with any storage system
- 🧠 Memory management tools that agents can use to record and search information during active conversations "in the hot path"
- ⚙️ Background memory manager that automatically extracts, consolidates, and updates agent knowledge
- ⚡ Native integration with LangGraph's Long-term Memory Store, available by default in all LangGraph Platform deployments
Hot Path Quickstart Guide
https://langchain-ai.github.io/langmem/hot_path_quickstart/
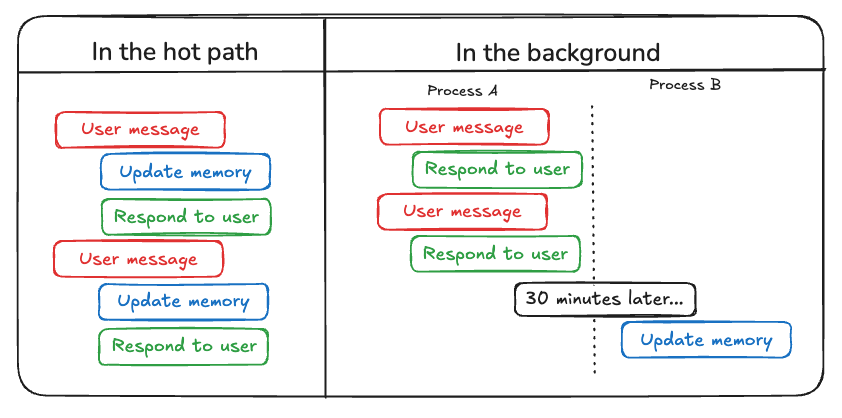
Memories can be created in two ways:
- 👉 In the hot path (this guide): the agent consciously saves notes using tools.
- In the background: memories are "subconsciously" extracted automatically from conversations (see Background Quickstart).
In this guide, we will create a LangGraph agent that actively manages its own long-term memory through LangMem's
manage_memorytool.
from langgraph.checkpoint.memory import MemorySaver from langgraph.prebuilt import create_react_agent from langgraph.store.memory import InMemoryStore from langgraph.utils.config import get_store from langmem import ( # Lets agent create, update, and delete memories create_manage_memory_tool, ) def prompt(state): """Prepare the messages for the LLM.""" # Get store from configured contextvar; store = get_store() # Same as that provided to `create_react_agent` memories = store.search( # Search within the same namespace as the one # we've configured for the agent ("memories",), query=state["messages"][-1].content, ) system_msg = f"""You are a helpful assistant. ## Memories <memories> {memories} </memories> """ return [{"role": "system", "content": system_msg}, *state["messages"]] store = InMemoryStore( index={ # Store extracted memories "dims": 1536, "embed": "openai:text-embedding-3-small", } ) checkpointer = MemorySaver() # Checkpoint graph state agent = create_react_agent( "anthropic:claude-3-5-sonnet-latest", prompt=prompt, tools=[ # Add memory tools # The agent can call "manage_memory" to # create, update, and delete memories by ID # Namespaces add scope to memories. To # scope memories per-user, do ("memories", "{user_id}"): create_manage_memory_tool(namespace=("memories",)), ], # Our memories will be stored in this provided BaseStore instance store=store, # And the graph "state" will be checkpointed after each node # completes executing for tracking the chat history and durable execution checkpointer=checkpointer, )
Background Quickstart Guide
https://langchain-ai.github.io/langmem/background_quickstart/
Memories can be created in two ways:
- In the hot path: the agent consciously saves notes using tools (see Hot path quickstart).
- 👉In the background (this guide): memories are "subconsciously" extracted automatically from conversations.
This guide shows you how to extract and consolidate memories in the background using
create_memory_store_manager. The agent will continue as normal while memories are processed in the background.
from langchain.chat_models import init_chat_model from langgraph.func import entrypoint from langgraph.store.memory import InMemoryStore from langmem import ReflectionExecutor, create_memory_store_manager store = InMemoryStore( index={ "dims": 1536, "embed": "openai:text-embedding-3-small", } ) llm = init_chat_model("anthropic:claude-3-5-sonnet-latest") # Create memory manager Runnable to extract memories from conversations memory_manager = create_memory_store_manager( "anthropic:claude-3-5-sonnet-latest", # Store memories in the "memories" namespace (aka directory) namespace=("memories",), ) @entrypoint(store=store) # Create a LangGraph workflow async def chat(message: str): response = llm.invoke(message) # memory_manager extracts memories from conversation history # We'll provide it in OpenAI's message format to_process = {"messages": [{"role": "user", "content": message}] + [response]} await memory_manager.ainvoke(to_process) return response.content # Run conversation as normal response = await chat.ainvoke( "I like dogs. My dog's name is Fido.", ) print(response) # Output: That's nice! Dogs make wonderful companions. Fido is a classic dog name. What kind of dog is Fido?
Long-term Memory in LLM Applications
https://langchain-ai.github.io/langmem/concepts/conceptual_guide/


standalone_examples
https://github.com/langchain-ai/langmem/tree/main/examples/standalone_examples
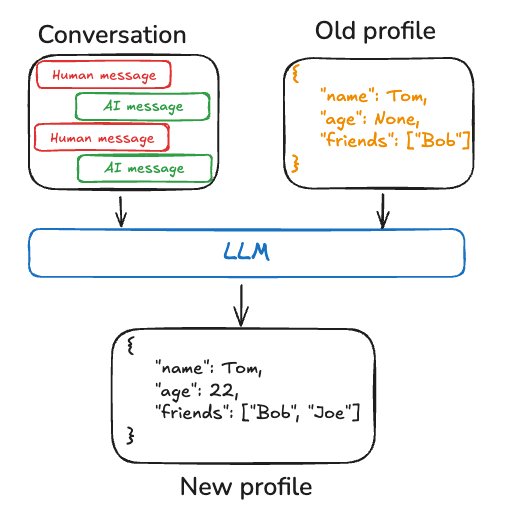
"""Example demonstrating how to use a custom store with the memory manager. This example shows how to: 1. Create a custom InMemoryStore 2. Define a structured memory schema using Pydantic 3. Initialize a memory manager with the custom store 4. Use the memory manager to store and retrieve memories The example demonstrates that the memory manager can work independently of LangGraph's context store, making it usable in standalone applications. """ from langgraph.store.memory import InMemoryStore from pydantic import BaseModel from langmem import create_memory_store_manager class PreferenceMemory(BaseModel): """Store preferences about the user.""" category: str preference: str context: str def create_store(): """Create a custom InMemoryStore with OpenAI embeddings.""" return InMemoryStore( index={ "dims": 1536, "embed": "openai:text-embedding-3-small", } ) async def run_example(): """Run the example demonstrating custom store usage.""" # Create our custom store store = create_store() # Initialize memory manager with custom store manager = create_memory_store_manager( "openai:gpt-4o-mini", schemas=[PreferenceMemory], namespace=("project", "{langgraph_user_id}"), store=store # Pass our custom store here ) # Simulate a conversation conversation = [ {"role": "user", "content": "I prefer dark mode in all my apps"}, {"role": "assistant", "content": "I'll remember that preference"} ] # Process the conversation and store memories print("Processing conversation...") await manager.ainvoke( {"messages": conversation}, config={"configurable": {"langgraph_user_id": "user123"}} ) # Retrieve and display stored memories print("\nStored memories:") memories = store.search(("project", "user123")) for memory in memories: print(f"\nMemory {memory.key}:") print(f"Content: {memory.value['content']}") print(f"Kind: {memory.value['kind']}") if __name__ == "__main__": import asyncio print("\nStarting custom store example...\n") asyncio.run(run_example()) print("\nExample completed.\n")
How to Extract Episodic Memories
https://langchain-ai.github.io/langmem/guides/extract_episodic_memories/#without-storage
from langmem import create_memory_manager from pydantic import BaseModel, Field class Episode(BaseModel): """Write the episode from the perspective of the agent within it. Use the benefit of hindsight to record the memory, saving the agent's key internal thought process so it can learn over time.""" observation: str = Field(..., description="The context and setup - what happened") thoughts: str = Field( ..., description="Internal reasoning process and observations of the agent in the episode that let it arrive" ' at the correct action and result. "I ..."', ) action: str = Field( ..., description="What was done, how, and in what format. (Include whatever is salient to the success of the action). I ..", ) result: str = Field( ..., description="Outcome and retrospective. What did you do well? What could you do better next time? I ...", ) manager = create_memory_manager( "anthropic:claude-3-5-sonnet-latest", schemas=[Episode], instructions="Extract examples of successful explanations, capturing the full chain of reasoning. Be concise in your explanations and precise in the logic of your reasoning.", enable_inserts=True, )
from langchain.chat_models import init_chat_model from langgraph.func import entrypoint from langgraph.store.memory import InMemoryStore from langmem import create_memory_store_manager # Set up vector store for similarity search store = InMemoryStore( index={ "dims": 1536, "embed": "openai:text-embedding-3-small", } ) # Configure memory manager with storage manager = create_memory_store_manager( "anthropic:claude-3-5-sonnet-latest", namespace=("memories", "episodes"), schemas=[Episode], instructions="Extract exceptional examples of noteworthy problem-solving scenarios, including what made them effective.", enable_inserts=True, ) llm = init_chat_model("anthropic:claude-3-5-sonnet-latest") @entrypoint(store=store) def app(messages: list): # Step 1: Find similar past episodes similar = store.search( ("memories", "episodes"), query=messages[-1]["content"], limit=1, ) # Step 2: Build system message with relevant experience system_message = "You are a helpful assistant." if similar: system_message += "\n\n### EPISODIC MEMORY:" for i, item in enumerate(similar, start=1): episode = item.value["content"] system_message += f""" Episode {i}: When: {episode['observation']} Thought: {episode['thoughts']} Did: {episode['action']} Result: {episode['result']} """ # Step 3: Generate response using past experience response = llm.invoke([{"role": "system", "content": system_message}, *messages]) # Step 4: Store this interaction if successful manager.invoke({"messages": messages}) return response app.invoke( [ { "role": "user", "content": "What's a binary tree? I work with family trees if that helps", }, ], ) print(store.search(("memories", "episodes"), query="Trees")) # [ # Item( # namespace=["memories", "episodes"], # key="57f6005b-00f3-4f81-b384-961cb6e6bf97", # value={ # "kind": "Episode", # "content": { # "observation": "User asked about binary trees and mentioned familiarity with family trees. This presented an opportunity to explain a technical concept using a relatable analogy.", # "thoughts": "I recognized this as an excellent opportunity to bridge understanding by connecting a computer science concept (binary trees) to something the user already knows (family trees). The key was to use their existing mental model of hierarchical relationships in families to explain binary tree structures.", # "action": "Used family tree analogy to explain binary trees: Each person (node) in a binary tree can have at most two children (left and right), unlike family trees where people can have multiple children. Drew parallel between parent-child relationships in both structures while highlighting the key difference of the two-child limitation in binary trees.", # "result": "Successfully translated a technical computer science concept into familiar terms. This approach demonstrated effective teaching through analogical reasoning - taking advantage of existing knowledge structures to build new understanding. For future similar scenarios, this reinforces the value of finding relatable real-world analogies when explaining technical concepts. The family tree comparison was particularly effective because it maintained the core concept of hierarchical relationships while clearly highlighting the key distinguishing feature (binary limitation).", # }, # }, # created_at="2025-02-09T03:40:11.832614+00:00", # updated_at="2025-02-09T03:40:11.832624+00:00", # score=0.30178054939692683, # ) # ]
Delayed Background Memory Processing
https://langchain-ai.github.io/langmem/guides/delayed_processing/#problem
from langchain.chat_models import init_chat_model from langgraph.func import entrypoint from langgraph.store.memory import InMemoryStore from langmem import ReflectionExecutor, create_memory_store_manager # Create memory manager to extract memories from conversations memory_manager = create_memory_store_manager( "anthropic:claude-3-5-sonnet-latest", namespace=("memories",), ) # Wrap memory_manager to handle deferred background processing executor = ReflectionExecutor(memory_manager) store = InMemoryStore( index={ "dims": 1536, "embed": "openai:text-embedding-3-small", } ) @entrypoint(store=store) def chat(message: str): response = llm.invoke(message) # Format conversation for memory processing # Must follow OpenAI's message format to_process = {"messages": [{"role": "user", "content": message}] + [response]} # Wait 30 minutes before processing # If new messages arrive before then: # 1. Cancel pending processing task # 2. Reschedule with new messages included delay = 0.5 # In practice would choose longer (30-60 min) # depending on app context. executor.submit(to_process, after_seconds=delay) return response.content

 浙公网安备 33010602011771号
浙公网安备 33010602011771号