Agentic RAG
Agentic RAG
https://langchain-ai.github.io/langgraph/tutorials/rag/langgraph_agentic_rag/
Retrieval Agents are useful when we want to make decisions about whether to retrieve from an index.
To implement a retrieval agent, we simply need to give an LLM access to a retriever tool.
We can incorporate this into LangGraph.
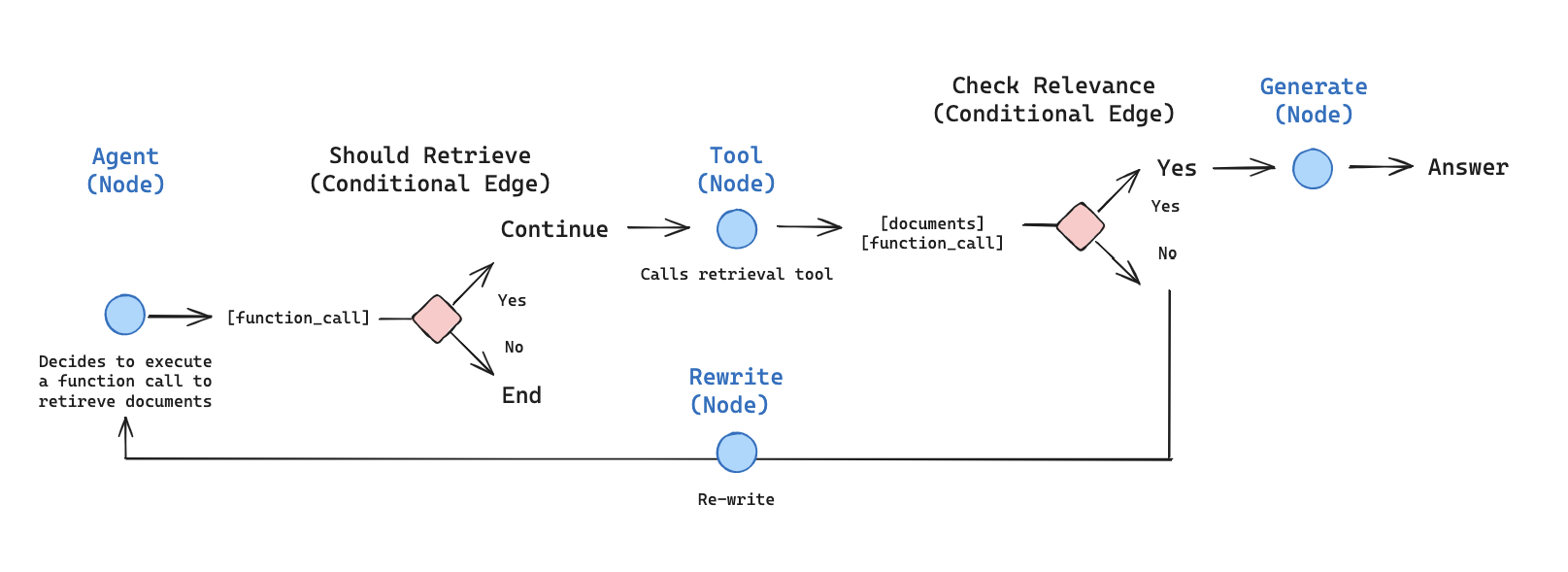
Nodes and Edges¶
We can lay out an agentic RAG graph like this:
- The state is a set of messages
- Each node will update (append to) state
- Conditional edges decide which node to visit next
import getpass import os import json from langgraph.graph import END, StateGraph, START from langgraph.prebuilt import ToolNode from langchain_community.document_loaders import WebBaseLoader # from langchain_community.vectorstores import Chroma from langchain_chroma import Chroma from langchain_openai import OpenAIEmbeddings from langchain_text_splitters import RecursiveCharacterTextSplitter from typing import Annotated, Sequence from typing_extensions import TypedDict from langchain_core.messages import BaseMessage from langgraph.graph.message import add_messages from langchain.tools.retriever import create_retriever_tool from typing import Annotated, Literal, Sequence from typing_extensions import TypedDict from langchain import hub from langchain_core.messages import BaseMessage, HumanMessage from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import PromptTemplate from langchain_openai import ChatOpenAI from pydantic import BaseModel, Field from langgraph.prebuilt import tools_condition from dotenv import load_dotenv load_dotenv('.env') # def _set_env(key: str): # if key not in os.environ: # os.environ[key] = getpass.getpass(f"{key}:") # # # _set_env("OPENAI_API_KEY") # 模型配置字典 MODEL_CONFIGS = { "openai": { "base_url": "https://nangeai.top/v1", "api_key": "sk-0OWbyfzUSwajhvqGoNbjIEEWchM15CchgJ5hIaN6qh9I3XRl", "chat_model": "gpt-4o-mini", "embedding_model": "text-embedding-3-small" }, "oneapi": { "base_url": "http://139.224.72.218:3000/v1", "api_key": "sk-EDjbeeCYkD1OnI9E48018a018d2d4f44958798A261137591", "chat_model": "qwen-max", "embedding_model": "text-embedding-v1" }, "qwen": { "base_url": "https://dashscope.aliyuncs.com/compatible-mode/v1", "api_key": "sk-80a72f794bc4488d85798d590e96db43", "chat_model": "qwen-max", "embedding_model": "text-embedding-v1" }, "ollama": { "base_url": "http://localhost:11434/v1", "api_key": "ollama", "chat_model": "deepseek-r1:14b", "embedding_model": "nomic-embed-text:latest" }, "siliconflow": { "base_url": os.getenv("SILICONFLOW_API_URL", "https://api.siliconflow.cn/v1"), "api_key": os.getenv("SILICONFLOW_API_KEY", ""), "chat_model": os.getenv("SILICONFLOW_API_MODEL", 'Qwen/Qwen2.5-7B-Instruct'), "embedding_model": os.getenv("SILICONFLOW_API_EMBEDDING_MODEL"), }, "zhipu": { "base_url": os.getenv("ZHIPU_API_URL", "https://api.siliconflow.cn/v1"), "api_key": os.getenv("ZHIPU_API_KEY", ""), "chat_model": os.getenv("ZHIPU_API_MODEL", 'Qwen/Qwen2.5-7B-Instruct'), "embedding_model": os.getenv("ZHIPU_API_EMBEDDING_MODEL"), } } DEFAULT_LLM_TYPE = "siliconflow" DEFAULT_TEMPERATURE = 0 config = MODEL_CONFIGS[DEFAULT_LLM_TYPE] urls = [ "https://www.cnblogs.com/lightsong/p/18815700", # "https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/", # "https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/", ] docs = [WebBaseLoader(url).load() for url in urls] docs_list = [item for sublist in docs for item in sublist] text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder( chunk_size=100, chunk_overlap=50 ) doc_splits = text_splitter.split_documents(docs_list) # # vectorstore = Chroma.from_documents( # documents=doc_splits, # collection_name="rag-chroma", # embedding_function=OpenAIEmbeddings(model=config["embedding_model"], base_url=config["base_url"], api_key=config["api_key"]), # ) # retriever = vectorstore.as_retriever() # Split doc_splits into smaller batches batch_size = 64 batches = [doc_splits[i:i + batch_size] for i in range(0, len(doc_splits), batch_size)] # Initialize an empty vectorstore embeddings = OpenAIEmbeddings(model=config["embedding_model"], base_url=config["base_url"], api_key=config["api_key"]) vectorstore = Chroma( collection_name="rag-chroma", embedding_function=embeddings ) # Add each batch to the vectorstore for batch in batches: vectorstore.add_documents(batch) retriever = vectorstore.as_retriever() retriever_tool = create_retriever_tool( retriever, "retrieve_blog_posts", "Search and return information about Lilian Weng blog posts on LLM agents, prompt engineering, and adversarial attacks on LLMs.", ) tools = [retriever_tool] class AgentState(TypedDict): # The add_messages function defines how an update should be processed # Default is to replace. add_messages says "append" messages: Annotated[Sequence[BaseMessage], add_messages] ### Edges def grade_documents(state) -> Literal["generate", "rewrite"]: """ Determines whether the retrieved documents are relevant to the question. Args: state (messages): The current state Returns: str: A decision for whether the documents are relevant or not """ print("---CHECK RELEVANCE---") # Data model class grade(BaseModel): """Binary score for relevance check.""" binary_score: str = Field(description="Relevance score 'yes' or 'no'") # llm = ChatOpenAI(model="gpt-3.5-turbo") model = ChatOpenAI( base_url=config["base_url"], api_key=config["api_key"], model=config["chat_model"], temperature=DEFAULT_TEMPERATURE, timeout=30, # 添加超时配置(秒) max_retries=2 # 添加重试次数 ) # LLM # model = ChatOpenAI(temperature=0, model="gpt-4o", streaming=True) # LLM with tool and validation llm_with_tool = model.with_structured_output(grade) # Prompt prompt = PromptTemplate( template="""You are a grader assessing relevance of a retrieved document to a user question. \n Here is the retrieved document: \n\n {context} \n\n Here is the user question: {question} \n If the document contains keyword(s) or semantic meaning related to the user question, grade it as relevant. \n Give a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question.""", input_variables=["context", "question"], ) # Chain chain = prompt | llm_with_tool messages = state["messages"] last_message = messages[-1] question = messages[0].content docs = last_message.content scored_result = chain.invoke({"question": question, "context": docs}) score = scored_result.binary_score if score == "yes": print("---DECISION: DOCS RELEVANT---") return "generate" else: print("---DECISION: DOCS NOT RELEVANT---") print(score) return "rewrite" def grade_documents(state) -> Literal["generate", "rewrite"]: """ Determines whether the retrieved documents are relevant to the question. Args: state (messages): The current state Returns: str: A decision for whether the documents are relevant or not """ print("---CHECK RELEVANCE---") # Data model class grade(BaseModel): """Binary score for relevance check.""" binary_score: str = Field(description="Relevance score 'yes' or 'no'") # llm = ChatOpenAI(model="gpt-3.5-turbo") model = ChatOpenAI( base_url=config["base_url"], api_key=config["api_key"], model=config["chat_model"], temperature=DEFAULT_TEMPERATURE, timeout=30, # 添加超时配置(秒) max_retries=2 # 添加重试次数 ) # LLM with tool and validation llm_with_tool = model.with_structured_output(grade) # Prompt prompt = PromptTemplate( template="""You are a grader assessing relevance of a retrieved document to a user question. \n Here is the retrieved document: \n\n {context} \n\n Here is the user question: {question} \n If the document contains keyword(s) or semantic meaning related to the user question, grade it as relevant. \n Give a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question. Return the answer in JSON format, e.g. {{ "binary_score": "yes" }}.""", input_variables=["context", "question"], ) # Chain chain = prompt | llm_with_tool messages = state["messages"] last_message = messages[-1] question = messages[0].content docs = last_message.content try: scored_result = chain.invoke({"question": question, "context": docs}) score = scored_result.binary_score except pydantic_core._pydantic_core.ValidationError as e: print(f"Validation error: {e}. Assuming 'no' relevance.") score = "no" if score == "yes": print("---DECISION: DOCS RELEVANT---") return "generate" else: print("---DECISION: DOCS NOT RELEVANT---") print(score) return "rewrite" ### Nodes def agent(state): """ Invokes the agent model to generate a response based on the current state. Given the question, it will decide to retrieve using the retriever tool, or simply end. Args: state (messages): The current state Returns: dict: The updated state with the agent response appended to messages """ print("---CALL AGENT---") messages = state["messages"] # model = ChatOpenAI(temperature=0, streaming=True, model="gpt-4-turbo") model = ChatOpenAI( base_url=config["base_url"], api_key=config["api_key"], model=config["chat_model"], temperature=DEFAULT_TEMPERATURE, timeout=30, # 添加超时配置(秒) max_retries=2 # 添加重试次数 ) model = model.bind_tools(tools) response = model.invoke(messages) # We return a list, because this will get added to the existing list return {"messages": [response]} # # def agent(state): # """ # Invokes the agent model to generate a response based on the current state. Given # the question, it will decide to retrieve using the retriever tool, or simply end. # # Args: # state (messages): The current state # # Returns: # dict: The updated state with the agent response appended to messages # """ # print("---CALL AGENT---") # messages = state["messages"] # model = ChatOpenAI( # base_url=config["base_url"], # api_key=config["api_key"], # model=config["chat_model"], # temperature=DEFAULT_TEMPERATURE, # timeout=30, # 添加超时配置(秒) # max_retries=2 # 添加重试次数 # ) # # model = model.bind_tools(tools) # response = model.invoke(messages) # # # Check and convert tool_calls args if necessary # if hasattr(response, 'tool_calls'): # for tool_call in response.tool_calls: # if isinstance(tool_call.args, str): # try: # tool_call.args = json.loads(tool_call.args) # except json.JSONDecodeError: # print(f"Error decoding JSON for tool call args: {tool_call.args}") # # # We return a list, because this will get added to the existing list # return {"messages": [response]} def rewrite(state): """ Transform the query to produce a better question. Args: state (messages): The current state Returns: dict: The updated state with re-phrased question """ print("---TRANSFORM QUERY---") messages = state["messages"] question = messages[0].content msg = [ HumanMessage( content=f""" \n Look at the input and try to reason about the underlying semantic intent / meaning. \n Here is the initial question: \n ------- \n {question} \n ------- \n Formulate an improved question: """, ) ] # Grader # model = ChatOpenAI(temperature=0, model="gpt-4-0125-preview", streaming=True) model = ChatOpenAI( base_url=config["base_url"], api_key=config["api_key"], model=config["chat_model"], temperature=DEFAULT_TEMPERATURE, timeout=30, # 添加超时配置(秒) max_retries=2 # 添加重试次数 ) response = model.invoke(msg) return {"messages": [response]} def generate(state): """ Generate answer Args: state (messages): The current state Returns: dict: The updated state with re-phrased question """ print("---GENERATE---") messages = state["messages"] question = messages[0].content last_message = messages[-1] docs = last_message.content # Prompt prompt = hub.pull("rlm/rag-prompt") # LLM # llm = ChatOpenAI(model_name="gpt-4o-mini", temperature=0, streaming=True) llm = ChatOpenAI( base_url=config["base_url"], api_key=config["api_key"], model=config["chat_model"], temperature=DEFAULT_TEMPERATURE, timeout=30, # 添加超时配置(秒) max_retries=2 # 添加重试次数 ) # Post-processing def format_docs(docs): return "\n\n".join(doc.page_content for doc in docs) # Chain rag_chain = prompt | llm | StrOutputParser() # Run response = rag_chain.invoke({"context": docs, "question": question}) return {"messages": [response]} print("*" * 20 + "Prompt[rlm/rag-prompt]" + "*" * 20) prompt = hub.pull("rlm/rag-prompt").pretty_print() # Show what the prompt looks like # Define a new graph workflow = StateGraph(AgentState) # Define the nodes we will cycle between workflow.add_node("agent", agent) # agent retrieve = ToolNode([retriever_tool]) workflow.add_node("retrieve", retrieve) # retrieval workflow.add_node("rewrite", rewrite) # Re-writing the question workflow.add_node( "generate", generate ) # Generating a response after we know the documents are relevant # Call agent node to decide to retrieve or not workflow.add_edge(START, "agent") # Decide whether to retrieve workflow.add_conditional_edges( "agent", # Assess agent decision tools_condition, { # Translate the condition outputs to nodes in our graph "tools": "retrieve", END: END, }, ) # Edges taken after the `action` node is called. workflow.add_conditional_edges( "retrieve", # Assess agent decision grade_documents, ) workflow.add_edge("generate", END) workflow.add_edge("rewrite", "agent") # Compile graph = workflow.compile() import pprint inputs = { "messages": [ ("user", "How to implement Generative User Interfaces?"), ] } for output in graph.stream(inputs): for key, value in output.items(): pprint.pprint(f"Output from node '{key}':") pprint.pprint("---") pprint.pprint(value, indent=2, width=80, depth=None) pprint.pprint("\n---\n")
出处:http://www.cnblogs.com/lightsong/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号