Prompt Generation from User Requirements
Prompt Generation from User Requirements
In this example we will create a chat bot that helps a user generate a prompt. It will first collect requirements from the user, and then will generate the prompt (and refine it based on user input). These are split into two separate states, and the LLM decides when to transition between them.
A graphical representation of the system can be found below.
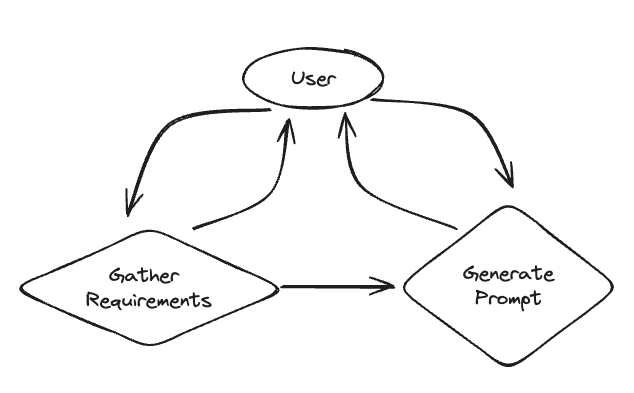
https://zhuanlan.zhihu.com/p/14550952200
1 案例解释
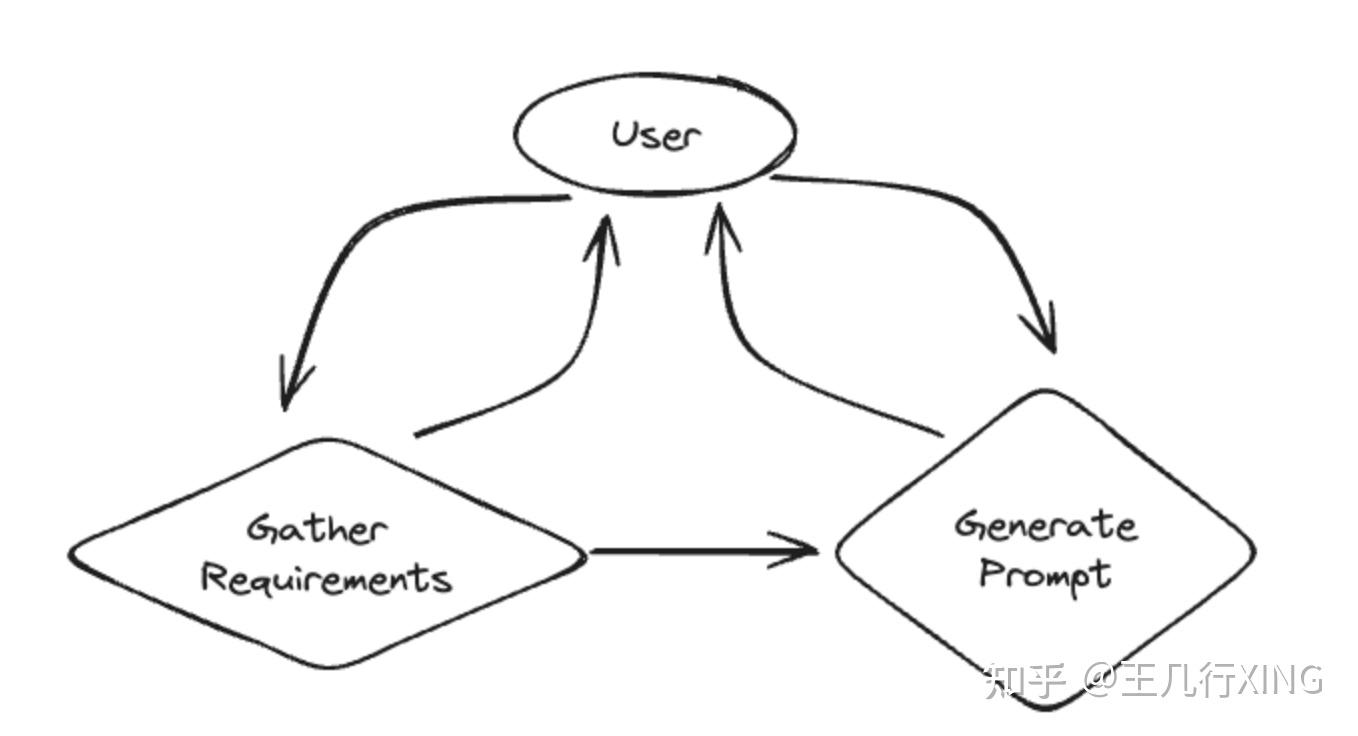
案例的核心目标是从用户的模糊需求中生成一个高质量的 Prompt,并通过分阶段的交互,确保 Prompt 符合用户期望。这种系统可以显著提高用户与语言模型互动的效率,尤其是在生成内容的场景中。
1.1. 核心任务
帮助用户生成一个高质量的 Prompt(提示),这是给语言模型提供指令的核心文本。Prompt 的设计非常重要,因为它直接影响到模型的输出质量。
1.2. 工作流程
这个聊天机器人分为两个主要阶段(states):
阶段 1:收集用户需求
- 机器人通过一系列问题引导用户输入信息,比如:
- 你希望模型完成什么任务?
- 需要生成什么类型的内容?
- 具体要求和限制是什么?
目标: 确保机器人充分了解用户需求,为生成 Prompt 做准备。
阶段 2:生成和优化 Prompt
- 根据用户提供的信息,机器人生成初始版本的 Prompt。
- 用户可以对这个 Prompt 提出修改意见,机器人会根据反馈进行优化,直到用户满意为止。
目标: 创建一个满足用户需求的精准 Prompt,并在必要时反复迭代。
1.3. 关键机制
- (State Transition):
- 机器人需要决定何时从“收集需求”阶段切换到“生成 Prompt”阶段。
- 这个决定由 LLM(大语言模型)根据用户输入的完整性和清晰度做出。
例子:
- 如果用户已经回答了所有关键问题,系统会自动进入 Prompt 生成阶段。
- 如果用户的输入不完整,系统会继续在需求收集阶段追问。
1.4. 图形化表示
案例提供了一个图表来展示这个系统的逻辑:
- 节点:
- 一个节点代表一个对话阶段(如“收集需求”或“生成 Prompt”)。
- 边(Edges):
- 边表示两个阶段之间的转换条件,例如“需求已完成”。
1.5. 具体案例应用
这类聊天机器人可以用于:
- 生成代码:用户描述功能需求,机器人生成代码的 Prompt。
- 写作协助:帮助用户设计模型生成的文章标题、结构或风格。
- 任务指令:用于创建复杂任务的指令,比如回答多步骤问题。
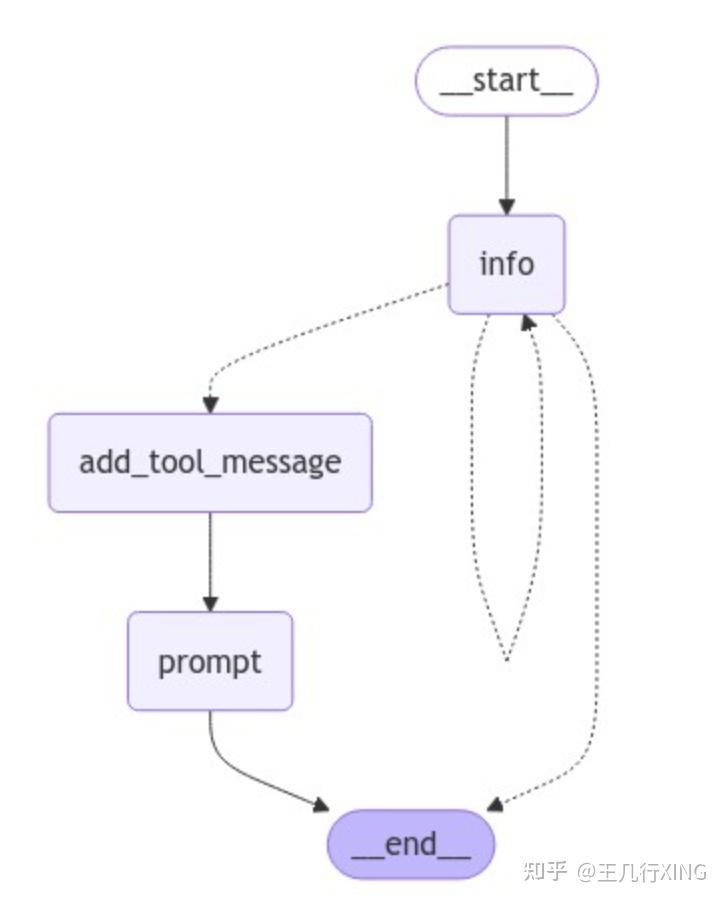
2 Graph 图的详细解读
__start__(开始节点)
- 作用:这是对话的起点,系统在这里启动并引导用户进入下一个节点。
- 功能:直接连接到
info节点。
2.info (信息收集节点)
- 作用:负责向用户收集需求,了解用户希望完成的任务以及对 Prompt 的具体要求。
- 功能:
- 提问用户问题,比如“你希望这个 Prompt 实现什么目标?”或者“你需要生成什么样的内容?”
- 状态:用户可能:
- 提供完整的需求,进入下一阶段(
add_tool_message)。 - 提供不完整的需求,系统会留在当前节点,继续追问,直到信息足够完整。
3.add_tool_message (工具信息添加节点)
- 作用:当收集到足够的信息后,系统在这里整合用户的需求,加入特定的工具提示或辅助信息。
- 功能:
- 根据用户提供的需求,添加更多的上下文信息以完善 Prompt。
- 比如:“根据你的描述,我会加入这个工具来帮助完成特定任务。”
4.prompt (Prompt 生成节点)
- 作用:根据之前收集的信息和上下文,生成初版 Prompt。
- 功能:
- 提供初版 Prompt 给用户进行确认。
- 用户可以对 Prompt 提出修改建议,系统会根据反馈进行优化,直到用户满意。
- 状态:
- 如果用户满意,系统会跳转到
__end__节点。 - 如果用户不满意,可能退回到
info节点进行更多信息收集。
__end__ (结束节点)
- 作用:这是对话的终点,代表用户已经确认了最终 Prompt。
- 功能:
- 提交生成的 Prompt。
- 结束整个流程。
complete code
https://github.com/fanqingsong/LangGraphChatBot/blob/main/05_ai_cs/main.py
import getpass import os # def _set_env(var: str): # if not os.environ.get(var): # os.environ[var] = getpass.getpass(f"{var}: ") # # # _set_env("OPENAI_API_KEY") from typing import List from langchain_core.messages import SystemMessage from langchain_openai import ChatOpenAI from pydantic import BaseModel from typing import Literal from langgraph.graph import END from IPython.display import Image, display import uuid from langgraph.checkpoint.memory import MemorySaver from langgraph.graph import StateGraph, START from langgraph.graph.message import add_messages from typing import Annotated from typing_extensions import TypedDict from dotenv import load_dotenv # Author:@南哥AGI研习社 (B站 or YouTube 搜索“南哥AGI研习社”) # 加载.env文件中的环境变量 # .env在上一级目录中,请修改路径 load_dotenv('.env') template = """Your job is to get information from a user about what type of prompt template they want to create. You should get the following information from them: - What the objective of the prompt is - What variables will be passed into the prompt template - Any constraints for what the output should NOT do - Any requirements that the output MUST adhere to If you are not able to discern this info, ask them to clarify! Do not attempt to wildly guess. After you are able to discern all the information, call the relevant tool.""" def get_messages_info(messages): return [SystemMessage(content=template)] + messages class PromptInstructions(BaseModel): """Instructions on how to prompt the LLM.""" objective: str variables: List[str] constraints: List[str] requirements: List[str] # 模型配置字典 MODEL_CONFIGS = { "openai": { "base_url": "https://nangeai.top/v1", "api_key": "sk-0OWbyfzUSwajhvqGoNbjIEEWchM15CchgJ5hIaN6qh9I3XRl", "chat_model": "gpt-4o-mini", "embedding_model": "text-embedding-3-small" }, "oneapi": { "base_url": "http://139.224.72.218:3000/v1", "api_key": "sk-EDjbeeCYkD1OnI9E48018a018d2d4f44958798A261137591", "chat_model": "qwen-max", "embedding_model": "text-embedding-v1" }, "qwen": { "base_url": "https://dashscope.aliyuncs.com/compatible-mode/v1", "api_key": "sk-80a72f794bc4488d85798d590e96db43", "chat_model": "qwen-max", "embedding_model": "text-embedding-v1" }, "ollama": { "base_url": "http://localhost:11434/v1", "api_key": "ollama", "chat_model": "deepseek-r1:14b", "embedding_model": "nomic-embed-text:latest" }, "siliconflow": { "base_url": os.getenv("SILICONFLOW_API_URL", "https://api.siliconflow.cn/v1"), "api_key": os.getenv("SILICONFLOW_API_KEY", ""), "chat_model": os.getenv("SILICONFLOW_API_MODEL", 'Qwen/Qwen2.5-7B-Instruct'), "embedding_model": os.getenv("SILICONFLOW_API_EMBEDDING_MODEL"), } } DEFAULT_LLM_TYPE = "siliconflow" DEFAULT_TEMPERATURE = 0 config = MODEL_CONFIGS[DEFAULT_LLM_TYPE] # llm = ChatOpenAI(model="gpt-3.5-turbo") llm = ChatOpenAI( base_url=config["base_url"], api_key=config["api_key"], model=config["chat_model"], temperature=DEFAULT_TEMPERATURE, timeout=30, # 添加超时配置(秒) max_retries=2 # 添加重试次数 ) # llm = ChatOpenAI(temperature=0) llm_with_tool = llm.bind_tools([PromptInstructions]) def info_chain(state): messages = get_messages_info(state["messages"]) response = llm_with_tool.invoke(messages) return {"messages": [response]} from langchain_core.messages import AIMessage, HumanMessage, ToolMessage # New system prompt prompt_system = """Based on the following requirements, write a good prompt template: {reqs}""" # Function to get the messages for the prompt # Will only get messages AFTER the tool call def get_prompt_messages(messages: list): tool_call = None other_msgs = [] for m in messages: if isinstance(m, AIMessage) and m.tool_calls: tool_call = m.tool_calls[0]["args"] elif isinstance(m, ToolMessage): continue elif tool_call is not None: other_msgs.append(m) return [SystemMessage(content=prompt_system.format(reqs=tool_call))] + other_msgs def prompt_gen_chain(state): messages = get_prompt_messages(state["messages"]) response = llm.invoke(messages) return {"messages": [response]} def get_state(state): messages = state["messages"] if isinstance(messages[-1], AIMessage) and messages[-1].tool_calls: return "add_tool_message" elif not isinstance(messages[-1], HumanMessage): return END return "info" class State(TypedDict): messages: Annotated[list, add_messages] memory = MemorySaver() workflow = StateGraph(State) workflow.add_node("info", info_chain) workflow.add_node("prompt", prompt_gen_chain) @workflow.add_node def add_tool_message(state: State): return { "messages": [ ToolMessage( content="Prompt generated!", tool_call_id=state["messages"][-1].tool_calls[0]["id"], ) ] } workflow.add_conditional_edges("info", get_state, ["add_tool_message", "info", END]) workflow.add_edge("add_tool_message", "prompt") workflow.add_edge("prompt", END) workflow.add_edge(START, "info") graph = workflow.compile(checkpointer=memory) # # try: # display(Image(graph.get_graph().draw_mermaid_png())) # except requests.exceptions.ConnectionError as e: # print(f"Failed to connect to mermaid.ink: {e}") # print("Please check your network connection or try again later.") # display(Image(graph.get_graph().draw_mermaid_png())) cached_human_responses = ["hi!", "rag prompt", "1 rag, 2 none, 3 no, 4 no", "red", "q"] cached_response_index = 0 config = {"configurable": {"thread_id": str(uuid.uuid4())}} while True: try: user = input("User (q/Q to quit): ") except: user = cached_human_responses[cached_response_index] cached_response_index += 1 print(f"User (q/Q to quit): {user}") if user in {"q", "Q"}: print("AI: Byebye") break output = None for output in graph.stream( {"messages": [HumanMessage(content=user)]}, config=config, stream_mode="updates" ): last_message = next(iter(output.values()))["messages"][-1] last_message.pretty_print() if output and "prompt" in output: print("Done!")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号