
LLM Evaluation: Metrics, Methodologies, Best Practices
LLM Evaluation: Metrics, Methodologies, Best Practices
https://www.datacamp.com/blog/llm-evaluation
Key Metrics for LLM Evaluation
Evaluating LLMs requires a comprehensive approach, employing a range of measures to assess various aspects of their performance. In this discussion, we explore key evaluation criteria for LLMs, including accuracy and performance, bias and fairness, as well as other important metrics.
Accuracy and performance metrics
Accurately measuring performance is an important step toward understanding an LLM’s capabilities. This section dives into the primary metrics utilized for evaluating accuracy and performance.
Perplexity
Perplexity is a fundamental metric for evaluating and measuring an LLM's ability to predict the next word in a sequence. This is how we can calculate it:
- Probability: First, the model calculates the probability of each word that could come next in a sentence.
- Inverse probability: We take the opposite of this probability. For example, if a word has a high probability (meaning the model thinks it’s likely), its inverse probability will be lower.
- Normalization: We then average this inverse probability over all the words in the test set (the text we are testing the model on).
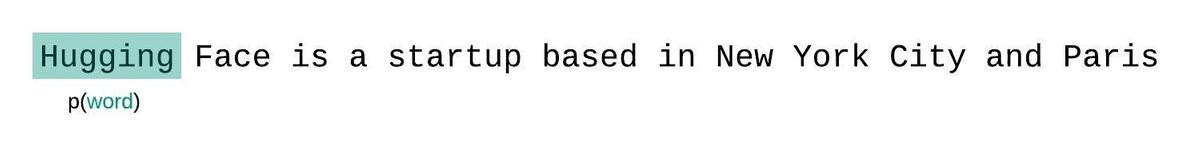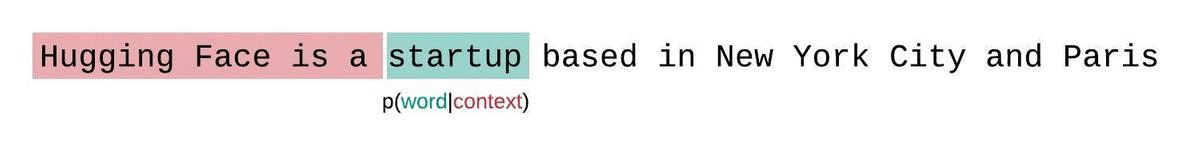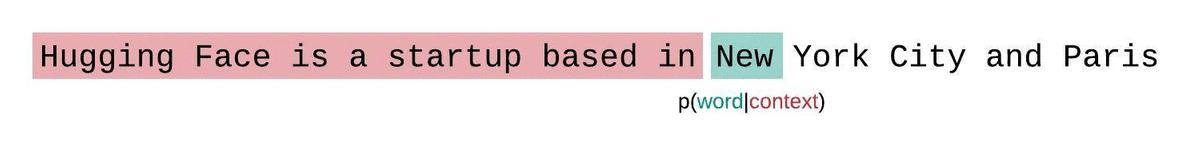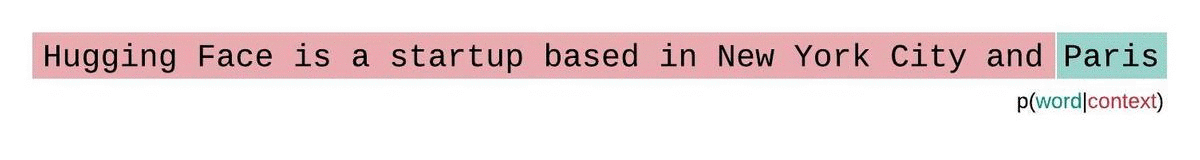
Illustration of an LLM predicting the probability of the next word given the context. Source
Lower perplexity scores indicate that the model predicts the next word more accurately, reflecting better performance. Essentially, it quantifies how well a probability distribution or predictive model predicts a sample.
For LLMs, a lower perplexity means the model is more confident in its word predictions, leading to more coherent and contextually appropriate text generation.
Accuracy
Accuracy is a widely used metric for classification tasks, representing the proportion of correct predictions made by the model. While this is a typically intuitive metric, in the context of open-ended generation tasks, it can often be misleading.
For instance, when generating creative or contextually nuanced text, the "correctness" of the output is not as straightforward to define as it is for tasks like sentiment analysis or topic classification. Therefore, while accuracy is useful for specific tasks, it should be complemented with other metrics when evaluating LLMs.
BLEU/ROUGE scores
BLEU (Bilingual Evaluation Understudy) and ROUGE (Recall-Oriented Understudy for Gisting Evaluation) scores are used to evaluate the quality of generated text by comparing it to reference texts.
BLEU is all about precision: if a machine translation uses the exact same words as a human translation, it gets a high BLEU score. For example, if the human reference is "The cat is on the mat," and the machine output is "The cat sits on the mat," the BLEU score would be high because many words overlap.
ROUGE focuses on recall: it checks if the machine-generated text captures all the important ideas from the human reference. Let's say a human-written summary is "The study found that people who exercise regularly tend to have lower blood pressure." If the AI-generated summary is "Exercise linked to lower blood pressure," ROUGE would give it a high score because it captures the main point even though the wording is different.
These metrics are beneficial for tasks like machine translation, summarization, and text generation, providing a quantitative assessment of how closely the model's output aligns with human-generated reference texts.
Bias and fairness metrics
Ensuring fairness and reducing bias in LLMs is essential for equitable applications. Here, we cover key metrics for evaluating bias and fairness in LLMs.
Demographic parity
Demographic parity indicates whether a model's performance is consistent across different demographic groups. It evaluates the proportion of positive outcomes across groups defined by attributes such as race, gender, or age.
Achieving demographic parity means that the model's predictions are not biased toward any particular group, ensuring fairness and equity in its applications.
Equal opportunity
Equal opportunity focuses on whether the model's errors are evenly distributed across different demographic groups. It assesses the false negative rates for each group, validating that the model does not disproportionately fail for certain demographics.
This metric is crucial for applications where fairness and equal access are essential, such as hiring algorithms or loan approval processes.
Counterfactual fairness
Counterfactual fairness evaluates whether a model's predictions would change if certain sensitive attributes were different. This involves generating counterfactual examples where the sensitive attribute (e.g., gender or race) is altered while keeping other features constant.
If the model's prediction changes based on this alteration, it indicates a bias related to the sensitive attribute. Counterfactual fairness is vital for identifying and mitigating biases that may not be apparent through other metrics.
Other metrics
Beyond performance and fairness, additional criteria are useful for a comprehensive evaluation of LLMs. This section highlights these aspects.
Fluency
Fluency assesses the naturalness and grammatical correctness of the generated text. A fluent LLM produces outputs that are easy to read and understand, mimicking the flow of human language.
This can be evaluated through automated tools or human judgment, focusing on aspects such as grammar, syntax, and overall readability.
Coherence
Coherence helps analyze the logical flow and consistency of the generated text. A coherent text maintains a clear structure and logical progression of ideas, making it straightforward for readers to follow. Coherence is particularly important for longer texts, such as essays or articles, where maintaining a consistent narrative is key.
Factuality
Factuality evaluates the accuracy of the information provided by the LLM, especially in information-seeking tasks. This metric confirms that the model generates text that is not only plausible but also factually correct.
Factuality is indispensable for applications like news generation, educational content, and customer support, where providing accurate information is the main goal.

Evaluation Methodologies
A robust evaluation of LLMs involves integrating both quantitative and qualitative approaches. This section details a range of methodologies, such as benchmark datasets, human evaluation techniques, and automated evaluation methods, to thoroughly assess LLM performance.
Benchmark datasets
Benchmark datasets are valuable tools for evaluating LLMs, providing standardized tasks that enable comparative analysis across different models. These datasets help establish a baseline for model performance and facilitate benchmarking.
Existing benchmarks
Benchmark datasets are important tools for evaluating LLMs, providing standardized tasks that enable comparative analysis across different models. Some of the most popular benchmark datasets for various natural language processing (NLP) tasks include:
- GLUE (General Language Understanding Evaluation): A collection of diverse tasks designed to evaluate the general linguistic capabilities of LLMs, including sentiment analysis, textual entailment, and question answering.
- SuperGLUE: An advanced version of GLUE, comprising more challenging tasks to test the robustness and nuanced understanding of LLMs.
- SQuAD (Stanford Question Answering Dataset): A dataset focused on reading comprehension, where models are scored based on their ability to answer questions derived from Wikipedia articles.
Custom datasets
While existing benchmarks are invaluable, creating custom datasets is vital for domain-specific evaluation. Custom datasets allow us to tailor the evaluation process to the unique requirements and challenges of the specific application or industry.
For example, a healthcare organization could create a dataset of medical records and clinical notes to evaluate an LLM's ability to handle medical terminology and context. Custom datasets ensure that the model's performance is aligned with real-world use cases, providing more relevant and actionable insights.
Human evaluation
Human evaluation methods are indispensable for assessing the nuanced aspects of LLM outputs that automated metrics might miss. These techniques involve direct feedback from human judges, offering qualitative insights into model performance.
Direct assessment
Human evaluation remains a gold standard for assessing the quality of LLM outputs. Direct assessment methods involve collecting feedback from human judges using surveys and rating scales.
These methods can capture nuanced aspects of text quality, such as fluency, coherence, and relevance, which automated metrics might overlook. Human judges can provide qualitative feedback on specific strengths and weaknesses, helping to identify specific areas for improvement.
Comparative judgment
Comparative judgment involves techniques like pairwise comparison, where human evaluators compare the outputs of different models directly. This method can be more reliable than absolute rating scales, as it reduces the subjectivity associated with individual ratings.
Evaluators are asked to choose the better output from pairs of generated texts, providing a relative ranking of model performance. Comparative judgment is particularly useful for fine-tuning models and selecting the best-performing variants.
Automated evaluation
Automated evaluation methods provide a quick and objective way to assess LLM performance. These methods employ various metrics to quantify different aspects of model outputs, ensuring a comprehensive evaluation.
Metric-Based
Automated metrics provide a quick and objective way to evaluate LLM performance. Metrics like perplexity and BLEU are widely used to assess various aspects of text generation.
As discussed earlier, perplexity measures the model's predictive capability, with lower scores indicating better performance. BLEU, on the other hand, evaluates the quality of generated text by comparing it to reference texts, focusing on the precision of n-grams.
Adversarial evaluation
Adversarial evaluation involves subjecting LLMs to adversarial attacks to test their robustness. These attacks are designed to exploit weaknesses and biases in the model, revealing vulnerabilities that might not be apparent through standard evaluation methods.
An adversarial attack might involve inputting slightly altered or misleading data to analyze how the model responds. This approach is useful for applications where reliability and security are held in high regard, as it helps to identify and mitigate potential risks.

Best Practices for LLM Evaluation
To effectively assess the capabilities of LLMs, a strategic approach should be followed. Adopting best practices ensures that your evaluation process is thorough, transparent, and tailored to your unique requirements. Here, we cover best practices to follow.
|
Best Practice |
Description |
Example Case |
Relevant Metric(s) |
|
Define Clear Objectives |
Identify the tasks and goals the LLM should achieve before starting the evaluation process. |
Improve machine translation performance of an LLM |
BLEU/ROUGE scores |
|
Consider Your Audience |
Tailor the evaluation to the intended users of the LLM, considering their expectations and needs. |
LLM for generating text |
Perplexity, Fluency, Coherence |
|
Transparency and Reproducibility |
Ensure the evaluation process is well-documented and can be replicated by others for verification and improvement. |
Publicly releasing the evaluation dataset and code used to assess the LLM's capabilities |
Any relevant metric, depending on the specific task and goals of the evaluation |
Conclusion
This guide has provided a comprehensive overview of the essential metrics and methodologies for assessing LLMs, from perplexity and accuracy to bias and fairness measures.
By employing both quantitative and qualitative evaluation techniques and adhering to best practices, we can ensure a thorough and reliable assessment of these models.
With this knowledge, we are better equipped to select and implement LLMs that best meet our needs, ensuring their optimal performance and reliability within our chosen applications.



【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek “源神”启动!「GitHub 热点速览」
· 我与微信审核的“相爱相杀”看个人小程序副业
· 微软正式发布.NET 10 Preview 1:开启下一代开发框架新篇章
· 如何使用 Uni-app 实现视频聊天(源码,支持安卓、iOS)
· C# 集成 DeepSeek 模型实现 AI 私有化(本地部署与 API 调用教程)
2021-02-23 Ensemble methods of sklearn
2020-02-23 Vue2最低支持Node版本调查