
Deploy Machine Learning Models with Keras, FastAPI, Redis and Docker
Deploy Machine Learning Models with Keras, FastAPI, Redis and Docker
https://medium.com/analytics-vidhya/deploy-machine-learning-models-with-keras-fastapi-redis-and-docker-4940df614ece

This tutorial will show you how to rapidly deploy your machine learning models with FastAPI, Redis and Docker.
If you want to fast-forward, the accompanying code repository will get you serving a image classification model within minutes.
Overview
There are a number of great “wrap your machine learning model with Flask” tutorials out there. However, when I saw this awesome series of posts by Adrian Rosebrock, I thought that his approach was a little more production-ready and lent itself well to dockerization. Dockerizing this setup not only makes it a lot easier to get everything up and running with Docker Compose, it also becomes more readily scalable for production.
By the end of the tutorial, you will be able to:
1. Build a web server using FastAPI (with Uvicorn) to serve our machine learning endpoints.
2. Build a machine learning model server that serves a Keras image classification model (ResNet50 trained on ImageNet).
3. Use Redis as a message queue to pass queries and responses between the web server and model server.
4. Use Docker Compose to spin them all up!
Architecture
We will use the same architecture from the aforementioned posts by Adrian Rosebrock but substitute the web server frameworks (FastAPI + Uvicorn for Flask + Apache) and, more importantly, containerize the whole setup for ease of use. We will also be using most parts of Adrian’s code as he has done a splendid job with the processing, serialization, and wrangling with a few NumPy gotchas.
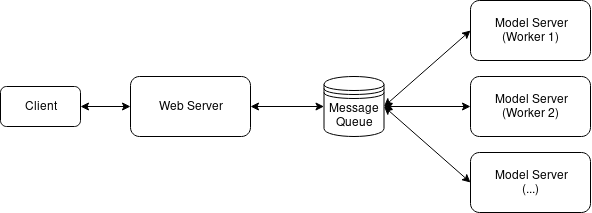
The main function of the web server is to serve a /predict endpoint through which other applications will call our machine learning model. When the endpoint is called, the web server routes the request to the Redis, which acts as an in-memory message queue for many concurrent requests. The model server simply polls the Redis message queue for a batch of images, classifies the batch of images, then returns the results to Redis. The web server picks up the results and returns that.
Code Repository
You can find all the code used in this tutorial here:
shanesoh/deploy-ml-fastapi-redis-docker
Serve a production-ready and scalable Keras-based deep learning model image classification using FastAPI, Redis and…
github.com
Building the web server
I chose to use the tiangolo/uvicorn-gunicorn-fastapi for the web server. This Docker image provides a neat ASGI stack (Uvicorn managed by Gunicorn with FastAPI framework) which promises significant performance improvements over the more common WSGI-based flask-uwsgi-nginx.
This decision was largely driven by wanting to try out an ASGI stack and high-quality docker images like tiangolo’s have made experimentation a lot easier. Also, as you’ll see in the code later, writing simple HTTP endpoints in FastAPI isn’t too different from how we’d do it in Flask.
The webserver/Dockerfile is quite simple. It takes the above-mentioned image and installs the necessary Python requirements and copies the code into the container:
FROM tiangolo/uvicorn-gunicorn-fastapi:python3.7
COPY requirements.txt /app/
RUN pip install -r /app/requirements.txt
COPY . /app
The webserver/main.py file runs the FastAPI server, exposing the/predict endpoint which takes the uploaded image, serializes it, pushes it to Redis and polls for the resulting predictions.
The code is mostly kept as-is with some housekeeping for a Dockerized environment, namely separating helper functions and parameters for the web and model server. Also, the parameters are passed into the Docker container via environment variables (more on that later).
Building the model server
The modelserver/Dockerfile is also quite simple:
FROM python:3.7-slim-buster
COPY requirements.txt /app/
RUN pip install -r /app/requirements.txt# Download ResNet50 model and cache in image RUN python -c "from keras.applications import ResNet50; ResNet50(weights='imagenet')"COPY . /app
CMD ["python", "/app/main.py"]
Here I used the python:3.7-slim-buster image. The slim variant reduces the overall image size by about 700mb. The alpine variant does not work with tensorflow so I’ve chosen not to use it.
I also chose to downloaded the machine learning model in the Dockerfile so it’ll be cached in the Docker image. Otherwise the model will be downloaded at the point of running the model server. This is not an issue aside from adding a few minutes delay to the replication process (as each worker that starts up needs to first download the model).
Once again, the Dockerfile installs the requirements and then runs the main.py file.
The model server polls Redis for a batch of images to predict on. Batch inference is particularly efficient for deep learning models, especially when running on GPU. The BATCH_SIZE parameter can be tuned to offer the lowest latency.
We also have to use redis-py’s pipeline (which is a misnomer as it is by default transactional in redis-py) to implement an atomic left-popping of multiple element (see lines 45–48). This becomes important in preventing race conditions when we replicate the model servers.
Putting it all together with Docker Compose
We create 3 services — Redis, model server and web server — that are all on the same Docker network.
The “global” parameters are in the app.env file while the service-specific parameters (such as SERVER_SLEEP and BATCH_SIZE) are passed in as environment variables to the containers.
The deploy parameters are used only for Docker Swarm (more on that in the following post) and will be safely ignored by Docker Compose.
We can spin everything up with docker-compose up which will build the images and start the various services. That’s it!
Testing the endpoints
Now test the service by curling the endpoints:
$ curl http://localhost
"Hello World!"$ curl -X POST -F img_file=@doge.jpg http://localhost/predict
{"success":true,"predictions":[{"label":"dingo","probability":0.6836559772491455},{"label":"Pembroke","probability":0.17909787595272064},{"label":"basenji","probability":0.07694739103317261},{"label":"Eskimo_dog","probability":0.01792934536933899},{"label":"Chihuahua","probability":0.005690475460141897}]}
Success! There’s probably no “shiba inu” class in ImageNet so “dingo” will have to do for now. Close enough.

Load testing with Locust
Locust is a load testing tool designed for load-testing websites. It is intended for load testing websites but also works great for simple HTTP endpoints like ours.
It’s easy to get it up and running. First install it with pip install locustio then start it up by running within the project directory:
locust --host=http://localhost
This uses the provided locustfile to test the /predict endpoint. Note that we’re pointing the host to localhost — we’re testing the response time of our machine learning service without any real network latency.
Now point your browser to http://localhost:8089 to access the locust web ui.
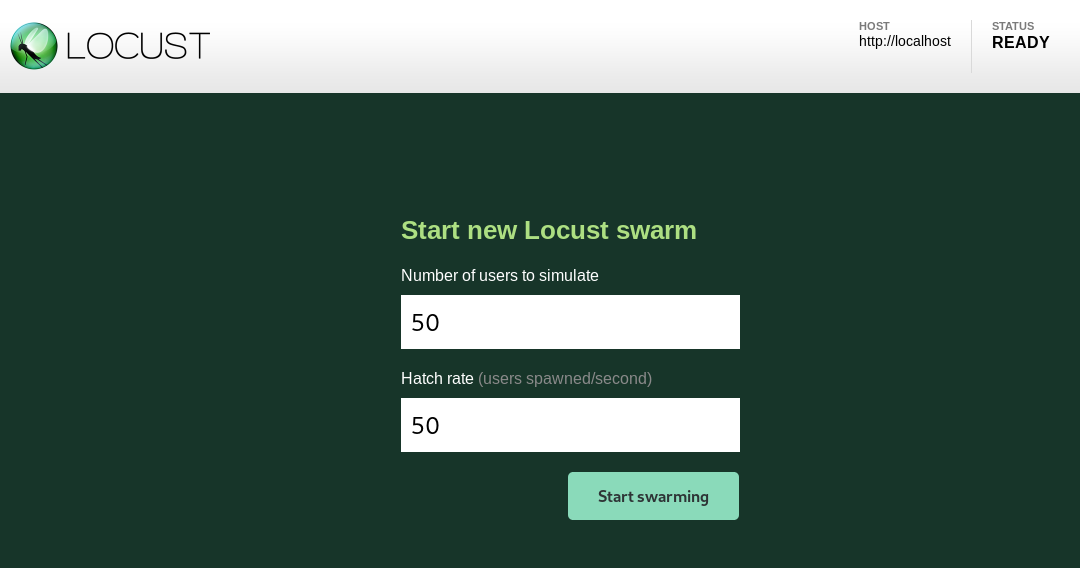
We’ll simulate 50 users (who are all hatched at the start).
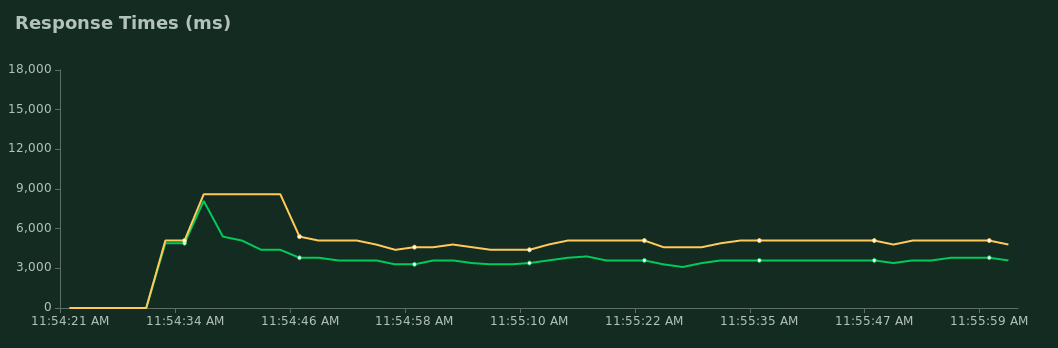
A p95 response time of around 5000ms means that 95% of requests should complete within 5 seconds. Depending on your use case and expected load, this could be far too slow.
Conclusion
We saw in this post how to build a Dockerized machine learning service using Keras, FastAPI and Redis. We also did a load test and saw how performance may be less than adequate.
In this following post, I will illustrate the use of Docker Swarm to easily scale our model server for better performance:
Scaling Machine Learning Models with Docker Swarm
This tutorial shows how we can easily scale a machine learning service on multiple hosts using Docker Swarm.
medium.com
https://github.com/shanesoh/deploy-ml-fastapi-redis-docker/tree/master
Make sure you have a modern version of
docker(>1.13.0)anddocker-composeinstalled.Simply run
docker-compose upto spin up all the services on your local machine.
- Test the
/predictendpoint by passing in the includeddoge.jpgas parameterimg_file:curl -X POST -F img_file=@doge.jpg http://localhost/predictYou should see the predictions returned as a JSON response.
Deploying this on Docker Swarm allows us to scale the model server to multiple hosts.
This assumes that you have a Swarm instance set up (e.g. on the cloud). Otherwise, to test this in a local environment, put your Docker engine in swarm mode with
docker swarm init.
- Deploy the stack on the swarm:
docker stack deploy -c docker-compose.yml mldeploy
- Check that it's running with
docker stack services mldeploy. Note that the model server is unreplicated at this time. You may scale up the model worker by:docker service scale mldeploy_modelserver=XWhere
Xis the number of workers you want.



【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek “源神”启动!「GitHub 热点速览」
· 我与微信审核的“相爱相杀”看个人小程序副业
· 微软正式发布.NET 10 Preview 1:开启下一代开发框架新篇章
· 如何使用 Uni-app 实现视频聊天(源码,支持安卓、iOS)
· C# 集成 DeepSeek 模型实现 AI 私有化(本地部署与 API 调用教程)
2019-02-22 利用目录服务器实现单点登录