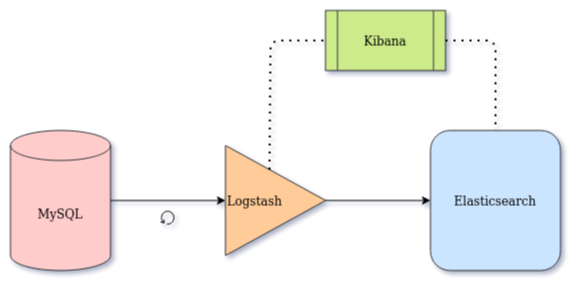
Using Logstash to create a data pipe linking Elasticsearch to MySQL in order to build an index from scratch and to replicate any changes occurring on the database records into Elasticsearch
Elasticsearch as a text search engine (version 7.9.3)
Logstash as a connector or data pipe from MySQL to Elasticsearch (version 7.9.3)
Kibana for monitoring and data visualization (version 7.9.3)
JDBC Connector/J (version 8.0.22)
Content
Problem Statement
Solution - Benefits from using Logstash - Use Cases
Implementing a proof of concept - Creating a host directory for the project - Setup a MySQL database - Setup Elasticsearch and Kibana - Setup Logstash to pipe data from MySQL to Elasticsearch: * First Scenario — Creating an Elasticsearch index from scratch * Second Scenario — Replicating changes on the database records to Elasticsearch
A
common scenario for tech companies is to start building their core
business functionalities around one or more databases, and then start
connecting services to those databases to perform searches on text data,
such as searching for a street name in the user addresses column of a
users table, or searching for book titles and author names in the
catalog of a library.
So
far everything is fine. The company keeps growing and acquires more and
more customers. But then searches start to become slower and slower,
which tends to irritate their customers and makes it hard to convince
new prospects to buy in.
Looking under the hood, the engineers realize that MySQL’s FULLTEXT indexes
are not ideal for text look-ups on large datasets, and in order to
scale up their operations, the engineers decide to move on to a more
dedicated and battle-tested text search engine.
A new challenge then comes in: How
to get the data that is in a MySQL database into an Elasticsearch
index, and how to keep the latter synchronized with the former?
Solution
The
modern data plumber’s toolkit contains a plethora of software for any
data manipulation task. In this article, we’ll focus on Logstash from
the ELK stack
in order to periodically fetch data from MySQL, and mirror it on
Elasticsearch. This will take into consideration any changes on the
MySQL data records, such as create , update , and delete , and have the same replicated on Elasticsearch documents.
Benefits from using Logstash
The
problem we are trying to solve here — sending data periodically from
MySQL to Elasticsearch for syncing the two — can be solved with a Shell
or Python script ran by a cron job or any job scheduler, BUT this would
deprive us from the benefits otherwise acquired by configuring Logstash
and its plugin-based setup:
As
part of the ELK Stack, everything will come together nice and smoothly
later with Elasticsearch and Kibana for metrics and visualization.
Use Cases
We will cover two scenarios in the following steps:
Creating an Elasticsearch index and indexing database records from scratch.
Incrementalupdate of the Elasticsearch index based on changes occurring on the database records (creation, update, deletion).
Implementing a proof of concept
Imagine
you are opening an online library where avid readers can search your
catalog of books to find their next reading. Your catalog contains
millions of titles, ranging from scientific literature volumes to
pamphlets about exotic adventures.
We will create an initial database table books with a few thousands of records with book titles, authors, ISBN and publication date. We’ll use the Goodreads book catalog that can be found on Kaggle. This initial table will serve prototyping the use case (1) Building an index from scratch.
We will create triggers on the table books that will populate a journal table books_journal with all changes on the books table (e.g. create , update , delete ). This means that whenever a record on the books table is created, updated, or deleted, this action will be recorded on the books_journal
table, and the same action will be done on the corresponding
Elasticsearch document. This will serve prototyping the use case (2)
Incremental update of the Elasticsearch index.
We’ll prototype and test the above concepts by defining a micro-services architecture using docker-compose.
Start by creating a directory to host this project (named e.g. sync-elasticsearch-mysql) and create a docker-compose.yaml file inside that directory with the following initial setup:
version: "3" services: ... # Here will come the services definition ...
2. Setup a MySQL database: Create a directory data/ where we’ll store MySQL dump files with the pre-cleaned books data for the books table, as well as the triggers for the books table (on create, update, and delete), and a new_arrivals table with books we will add to our catalog to simulate new records, and the table books_journal .
You can find these dump files in the project repository. Please copy them to the data/ directory so that the MySQL container will add them to the books database during the startup process.
Note that storing usernames and passwords in plain text in your source code is not advised. The above is done for the sake of prototyping this project only and is not in any case a recommended practice.
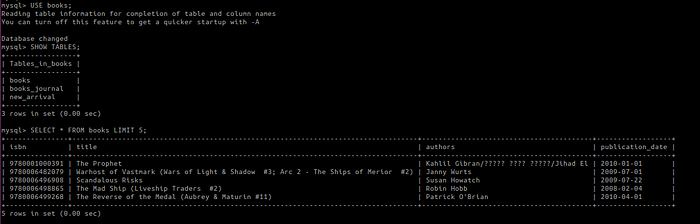
To start MySQL and check that data has been added successfully, from you project’s directory run on a terminal:
docker-compose up -d mysql # -d is for detached mode# Once container started, log into the MySQL container docker exec -it sem_mysql bash# Start a MySQL prompt mysql -uavid_reader -pi_love_books# Check that tables have been loaded from dump files use books; show tables;
Listing of the available tables and a sample of the data — Image by Author
To show the triggers with a JSON-like formatting, use command:
SHOW TRIGGERS \G;# To exit the MySQL prompt press CTRL+D # To logout from the MySQL container, press CTRL+D
Now that we have our database properly set up, we can move on to the meat and potatoes of this project.
3. Setup Elasticsearch and Kibana: To setup Elasticsearch (without indexing any document yet), add this to your docker-compose.yaml file:
Note that the volumes definition is recommended in order to mount the Elasticsearch index data from the docker volume to your directory file system.
To get Elasticsearch and Kibana started, run the following from your project directory:
docker-compose up -d elasticsearch kibana # -d is for detached mode# To check if everything so far is running as it should, run: docker-compose ps
After executing the above commands, 3 containers should be up and running — Image by Author
Let’s check if there is any index in our Elasticsearch node so far:
# On your terminal, log into the Elasticsearch container docker exec -it sem_elasticsearch bash# Once logged in, use curl to request a listing of the indexes curl localhost:9200/_cat/indices
If Kibana is up and running, you’ll see a list of indices used for metrics and visualization, but nothing related to our books yet — and if Kibana hasn’t been started, the list of indices will be empty.
List of indexes created by Kibana — Image by Author
4. Setup Logstash to pipe data from MySQL to Elasticsearch:
To connect Logstash to MySQL, we will use the official JDBC driver available at this address.
Let’s create a Dockerfile (named Dockerfile-logstash in the same directory) to pull a Logstash image, download the JDBC connector, and start a Logstash container. Add these lines to your Dockerfile:
FROM docker.elastic.co/logstash/logstash:7.9.3# Download JDBC connector for Logstash RUN curl -L --output "mysql-connector-java-8.0.22.tar.gz" "https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-8.0.22.tar.gz" \ && tar -xf "mysql-connector-java-8.0.22.tar.gz" "mysql-connector-java-8.0.22/mysql-connector-java-8.0.22.jar" \ && mv "mysql-connector-java-8.0.22/mysql-connector-java-8.0.22.jar" "mysql-connector-java-8.0.22.jar" \ && rm -r "mysql-connector-java-8.0.22" "mysql-connector-java-8.0.22.tar.gz"ENTRYPOINT ["/usr/local/bin/docker-entrypoint"]
Then add the following snippet to your docker-compose.yaml file:
version: "3" services: ... logstash: build: context: . dockerfile: Dockerfile-logstash container_name: sem_logstash depends_on: - mysql - elasticsearch volumes: # We will explain why and how to add volumes below
Logstash uses defined pipelines to know where to get data from, how to filter it, and where should it go. We will define two pipelines: one for creating an Elasticsearch index from scratch (first scenario), and one for incremental updates on changes to the database records (second scenario).
Please check documentation for an explanation of each of the fields used in the pipeline definition:
We define where to find the JDBC connector in jdbc_driver_library , setup where to find MySQL in jdbc_connection_string , instruct the plugin to run from scratch in clean_run , and we define where to find the SQL statement to fetch and format the data records in statement_filepath .
The filter basically removes extra fields added by the plugin.
In the output, we define where to find the Elasticsearch host, set the name of the index to books (can be a new or an existing index), define which action to perform (can be index , create , update , delete — see docs), and setup which field will serve as a unique ID in the books index — ISBN is an internationally unique ID for books.
To add the SQL query referenced by statement_filepath , let’s create a folder queries :
mkdir volumes/logstash/config/queries/
Then add file from-scratch.sql with as little as:
SELECT * FROM books.books
to get our index built with all the records available so far in our books table. Note that the query should NOT end with a semi-colon (;).
Now to mount the configuration files and definitions created above, add the following to your docker-compose.yaml file:
Note that volumes directives are a way to tell Docker to mount a directory or file inside the container (right hand side of the :) onto a directory or file on your machine or server (left hand side of the :). Checkout the official Docker Compose documentation on volumes.
Testing
In order to test the implementation for this first scenario, run on your terminal:
docker-compose up logstash
If the run is successful, you will see a message similar to Logstash shut down and the container will exit with error code 0.
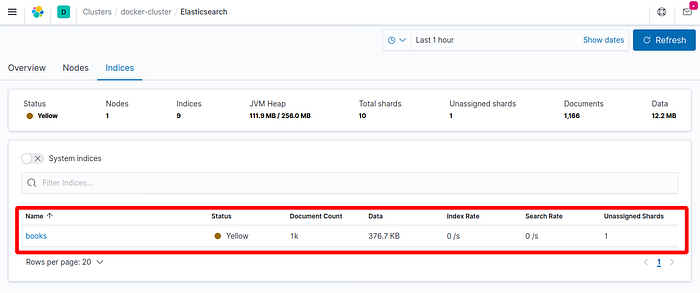
Now head to Kibana on you browser (to this link for example) and let’s start playing around to see if we have a books index and how we can search for books.
The books index has been successfully created and contains 1k documents — Image by Author
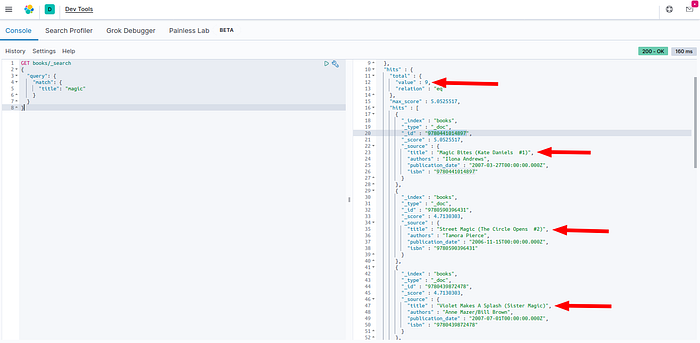
In the Dev Tools panel, you can run custom queries to fetch documents by field value. For example, let’s search for books with the word “magic” in their title. Paste this query on the Dev Tools console:
4.b. Second Scenario — Replicating changes on the database records to Elasticsearch:
Most of the configuring and tweaking has been done in the previous part. We will simply add another pipeline that will take charge of the incremental update (replication).
In the file volumes/logstash/config/pipelines.yml, add these two line:
In the same file, you may want to comment out the two previous lines related to the “from-scratch” part (first scenario) in order to instruct Logstash to run this incremental pipeline only.
Let’s create a file incremental.conf in the directory volumes/logstash/pipeline/ with the following content:
We see a few extra parameters compared to the previous pipeline definition.
The schedule parameter has a cron-like syntax (with a resolution down to the second when adding one more value the left), and uses the Rufus Scheduler behind the scene. Here we instruct Logstash to run this pipeline every 5 seconds with */5 * * * * * .
The website crontab.guru can help you read crontab expressions.
During each periodic run, the parameter tracking_column instructs Logstash to store the journal_id value of the last record fetched and store it somewhere on the filesystem (See documentation here for last_run_metadata_path ). In the following run, Logstash will fetch records starting from journal_id + 1 , where journal_id is the value stored in the current run.
In the filter section, when the database action type is “create” or “update”, we set the Elasticsearch action to “index” so that new documents get indexed, and existing documents get re-indexed to update their value. Another approach to avoid re-indexing existing documents is to write a custom “update” script and to use the “upsert” action. For “delete” actions, the document on Elasticsearch gets deleted.
Let’s create and populate the file incremental.sql in directory volumes/logstash/config/queries/ with this query:
SELECT j.journal_id, j.action_type, j.isbn, b.title, b.authors, b.publication_date FROM books.books_journal j LEFT JOIN books.books b ON b.isbn = j.isbn WHERE j.journal_id > :sql_last_value AND j.action_time < NOW() ORDER BY j.journal_id
Testing
Let’s have a look at the table books.new_arrival . It contains books that just got delivered to us and we didn’t have time to add them to our main books.books table.
Result of “SELECT * FROM books.new_arrival;” — Image by Author
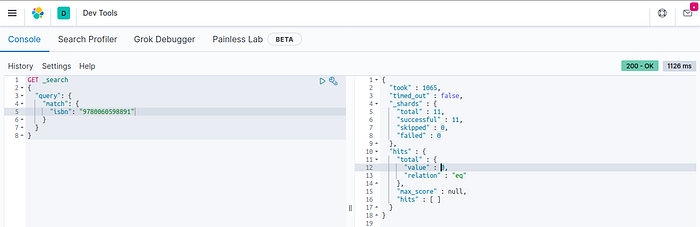
As we can see, none of the books in that table are in our Elasticsearch index. Let’s try with the 3 book in the table above “The Rocky Road to Romance (Elsie Hawkins #4)”, ISBN 9780060598891:
Search for ISBN 9780060598891 returns empty result — Image by Author
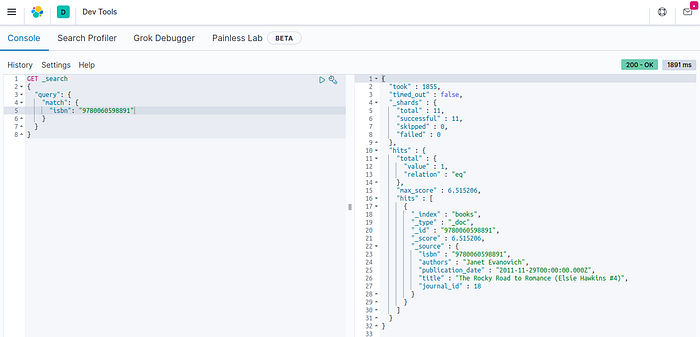
Now let’s transfer that book from the new arrivals table to our main books table:
INSERT INTO books SELECT * FROM new_arrival WHERE isbn = 9780060598891;
Running the same search on Elasticsearch, we are happy to see that the document is now available:
Now ISBN 9780060598891 is available on the Elasticsearch index — Image by Author
The sync is working!
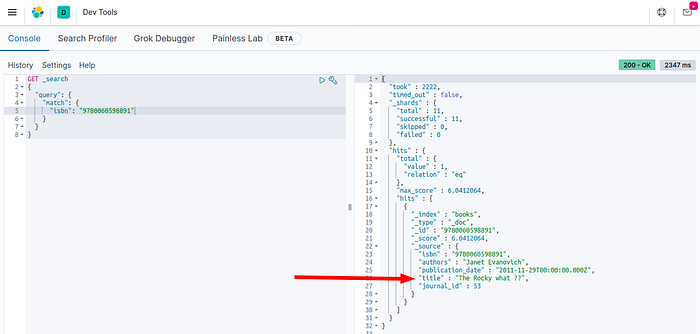
Let’s test with an update of the same ISBN:
UPDATE books SET title = "The Rocky what ??" WHERE isbn = 9780060598891;
Updates on the database records are successfully replicated to Elasticsearch documents — Image by Author
…and a delete of the same ISBN:
DELETE from books WHERE isbn = 9780060598891;
A record deleted from the database will also be removed from the Elasticsearch index — Image by Author
We managed to get a proof of concept up and running in a short amount of time of how to index data into Elasticsearch from a MySQL database, and how to keep Elasticsearch in sync with the database.
The technologies we used are a gold standard in the industry and many businesses rely on them daily to serve their customer, and it’s very likely that many have encountered or will encounter the same problem we solved in this project.
Get in touch
Shoot me a message! I am on these social platforms:





 浙公网安备 33010602011771号
浙公网安备 33010602011771号