Data Warehouse
Data Warehouse
https://www.coursera.org/in/articles/data-warehouse
What is a data warehouse?
A data warehouse, or enterprise data warehouse (EDW), is a central repository system where businesses store valuable information, such as customer and sales data, for analytics and reporting purposes.
Used to develop insights and guide decision-making via business intelligence (BI), data warehouses often contain current and historical data that has been extracted, transformed, and loaded (ETL) from several sources, including internal and external databases. Typically, a data warehouse acts as a business’s single source of truth (SSOT) by centralising data within a non-volatile, standardised system accessible to relevant employees. Designed to facilitate online analytical processing (OLAP) and used for quick and efficient multidimensional data analysis, data warehouses contain large stores of summarised data that can sometimes be many petabytes.
Data warehouse benefits
Data warehouses provide many benefits to businesses. Some of the most common uses include:
Provide a stable, centralised repository for large amounts of historical data
Improve business processes and decision-making with actionable insights
Increase a business’s overall return on investment (ROI)
Improve data quality
Enhance BI performance and capabilities by drawing on multiple sources
Provide access to historical data business-wide
Use AI and machine learning to improve business analytics
https://www.geeksforgeeks.org/types-of-data-warehouses/#frequently-asked-questions-on-types-of-data-warehouses
What are Data Warehouses?
A data warehouse is a centralized repository designed to store large volumes of structured and unstructured data from multiple sources. It supports data analysis, business intelligence, and reporting by consolidating data into a single, comprehensive system. The process typically involves extracting, transforming, and loading (ETL) data into the warehouse, where it can be organized and queried efficiently.
Top 15 Popular Data Warehouse Tools
https://www.geeksforgeeks.org/top-15-popular-data-warehouse-tools/
The Top 10 Data Warehouse Solutions
https://expertinsights.com/insights/the-top-data-warehouse-solutions/
- 1. Amazon Redshift
- 2. Apache Hive
- 3. Cloudera Data Warehouse
- 4. Google BigQuery
- 5. IBM Db2 Warehouse
- 6. OpenText Vertica
- 7. Oracle Autonomous Data Warehouse
- 8. SAP BW/4HANA
- 9. Snowflake
- 10. Teradata VantageCloud
Data Warehouse Architecture
https://www.geeksforgeeks.org/data-warehouse-architecture/
A Data Warehouse therefore can be described as a system that consolidates and manages data from different sources to assist an organization in making proper decisions. This makes the work of handling data to report easier. Two main construction approaches are used: Two of the most common models that have been developed are the Top-Down approach and the Bottom-Up approach and each of them possesses its strengths and weaknesses.
A Data-Warehouse is a heterogeneous collection of data sources organized under a unified schema. There are 2 approaches for constructing a data warehouse: The top-down approach and the Bottom-up approach are explained below.
What is Top-Down Approach?
The initial approach developed by Bill Inmon known as the top-down approach starts with building a single source data warehouse for the whole company. Merges and processes external data through the ETL (Extract, Transform, Load) process and subsequently stores them in the data warehouse. Specialized data marts for different organizations departments, for instance, the finance department are then formed from there. The strength of this method is that it offers a clear structure for managing data, however, this method can be expensive as well as time-consuming and for that reason, it is ideal for large organizations only.
The essential components are discussed below:
- External Sources: External source is a source from where data is collected irrespective of the type of data. Data can be structured, semi structured and unstructured as well.
- Stage Area: Since the data, extracted from the external sources does not follow a particular format, so there is a need to validate this data to load into datawarehouse. For this purpose, it is recommended to use ETL tool.
- E(Extracted): Data is extracted from External data source.
- T(Transform): Data is transformed into the standard format.
- L(Load): Data is loaded into datawarehouse after transforming it into the standard format.
- Data-warehouse: After cleansing of data, it is stored in the data warehouse as central repository. It actually stores the meta data and the actual data gets stored in the data marts. Note that data warehouse stores the data in its purest form in this top-down approach.
- Data Marts: Data mart is also a part of storage component. It stores the information of a particular function of an organisation which is handled by single authority. There can be as many number of data marts in an organisation depending upon the functions. We can also say that data mart contains subset of the data stored in data warehouse.
- Data Mining: The practice of analysing the big data present in data warehouse is data mining. It is used to find the hidden patterns that are present in the database or in data warehouse with the help of algorithm of data mining.
This approach is defined by Inmon as – data warehouse as a central repository for the complete organisation and data marts are created from it after the complete data warehouse has been created.
Extract, transform, and load (ETL)
https://learn.microsoft.com/en-us/azure/architecture/data-guide/relational-data/etl
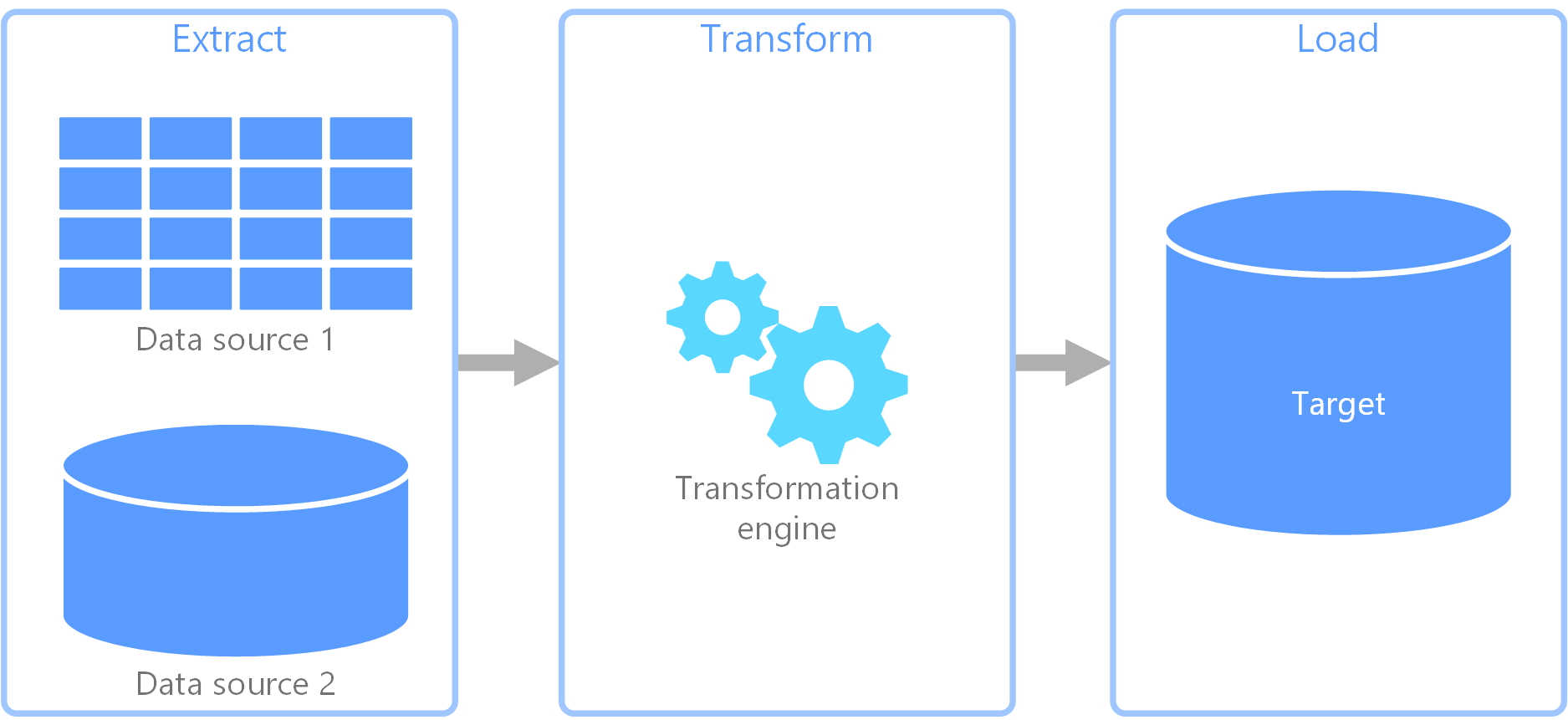
Extract, transform, load (ETL) process
extract, transform, load (ETL) is a data pipeline used to collect data from various sources. It then transforms the data according to business rules, and it loads the data into a destination data store. The transformation work in ETL takes place in a specialized engine, and it often involves using staging tables to temporarily hold data as it is being transformed and ultimately loaded to its destination.
The data transformation that takes place usually involves various operations, such as filtering, sorting, aggregating, joining data, cleaning data, deduplicating, and validating data.
Often, the three ETL phases are run in parallel to save time. For example, while data is being extracted, a transformation process could be working on data already received and prepare it for loading, and a loading process can begin working on the prepared data, rather than waiting for the entire extraction process to complete.
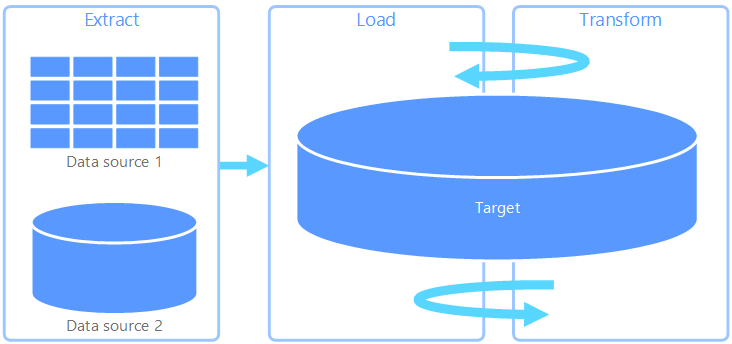
Extract, load, transform (ELT)
Extract, load, transform (ELT) differs from ETL solely in where the transformation takes place. In the ELT pipeline, the transformation occurs in the target data store. Instead of using a separate transformation engine, the processing capabilities of the target data store are used to transform data. This simplifies the architecture by removing the transformation engine from the pipeline. Another benefit to this approach is that scaling the target data store also scales the ELT pipeline performance. However, ELT only works well when the target system is powerful enough to transform the data efficiently.
Typical use cases for ELT fall within the big data realm. For example, you might start by extracting all of the source data to flat files in scalable storage, such as a Hadoop Distributed File System, an Azure blob store, or Azure Data Lake gen 2 (or a combination). Technologies, such as Spark, Hive, or PolyBase, can then be used to query the source data. The key point with ELT is that the data store used to perform the transformation is the same data store where the data is ultimately consumed. This data store reads directly from the scalable storage, instead of loading the data into its own proprietary storage. This approach skips the data copy step present in ETL, which often can be a time consuming operation for large data sets.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号