Deploying LLM Applications with LangServe
Deploying LLM Applications with LangServe
https://www.datacamp.com/tutorial/deploying-llm-applications-with-langserve
Deploying a large language model (LLM) into production can transform your application, offering advanced features in natural language understanding and generation. However, this process is fraught with challenges that can hinder even the most experienced developers.
In this guide, we'll explore how to deploy LLM applications using LangServe, a tool designed to simplify and streamline this complex process. From installation to integration, you'll learn the essential steps to successfully implement an LLM and unlock its full potential.
The Challenges in Building LLM-Based Applications
Building an LLM-based application is more complex than simply calling an API. While integrating an LLM into your project can significantly enhance its capabilities, it comes with a unique set of challenges that require careful consideration. Below, we'll break down the primary obstacles you might encounter and highlight the aspects of deployment that need attention.
Model selection and customization
Selecting the right model for your application is the first hurdle. The choice depends on various factors, such as the specific task, required accuracy, and available computational resources. Additionally, customizing a pre-trained model to suit your application's needs can be complex, involving fine-tuning with domain-specific data.
Resource management
LLMs are computationally intensive and demand substantial resources. Ensuring your infrastructure can handle the high memory and processing power requirements is crucial. This includes planning for scalability to accommodate future growth and potential increases in usage.
Latency and performance
Achieving low latency is vital for a seamless user experience. LLMs can be slow to process requests, especially under heavy loads. Optimizing performance involves strategies such as model compression, efficient serving frameworks, and possibly offloading some processing tasks to edge devices.
Monitoring and maintenance
Once deployed, continuous monitoring of the LLM application is necessary. This includes tracking performance metrics, detecting anomalies, and managing model drift. Regular maintenance ensures that the model remains accurate and efficient over time, requiring periodic updates and retraining with new data.
Integration and compatibility
Integrating LLMs with existing systems and workflows can be challenging. Ensuring compatibility with various software environments, APIs, and data formats requires meticulous planning and execution. Seamless integration is key to leveraging the full potential of LLMs in your application.
Cost management
The high computational demands of LLMs can lead to significant operational costs. Balancing performance with cost efficiency is a vital consideration. Strategies to manage costs include optimizing resource allocation, using cost-effective cloud services, and regularly reviewing usage patterns to identify areas for savings.
What You Need to Know About Deploying LLMs into Production
Deploying an LLM into production is a complex process that involves orchestrating multiple systems and components. It goes beyond simply integrating a powerful language model into your application; it requires a cohesive infrastructure where each part plays a critical role.
The anatomy of an LLM application
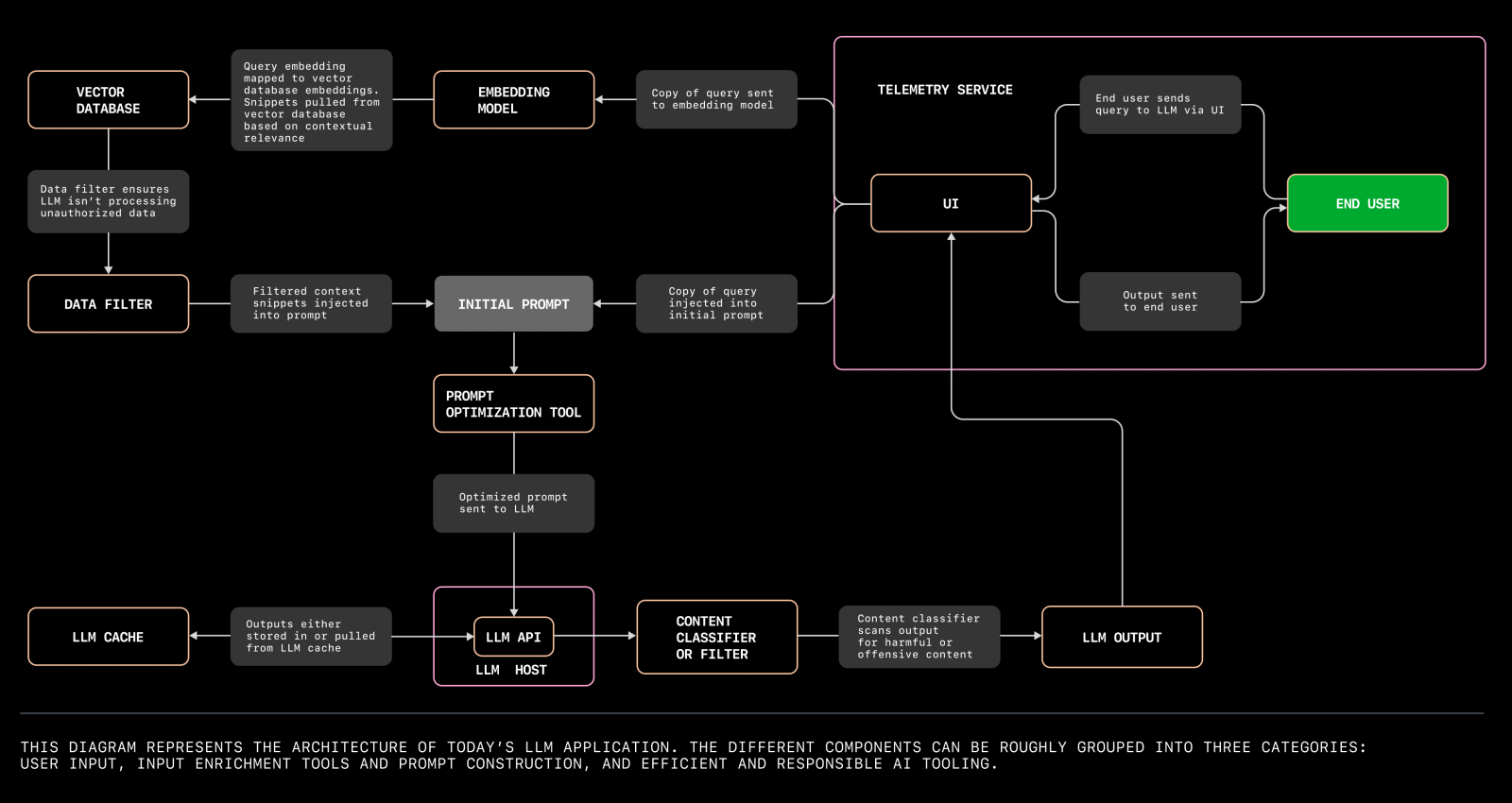
To understand the intricacies of deploying LLM applications, exploring the various components involved and their interactions is imperative. The following diagram illustrates the architecture of a modern LLM application, highlighting the key elements and their relationships within the system.
A diagram illustrating the architecture of a modern LLM application. Source
The architecture of an LLM application can be broken down into several core aspects:
Vector databases
Vector databases are fundamental for managing the high-dimensional data generated by LLMs. These databases store and retrieve vectors efficiently, enabling fast and accurate similarity searches. They are indispensable for applications like semantic search, recommendation systems, and personalized user experiences.
When deploying LLMs, selecting a robust vector database that can scale with your application is key to maintaining performance and responsiveness.
Prompt templates
Prompt templates are pre-defined structures that help standardize interactions with the LLM. They ensure consistency and reliability in the responses generated by the model.
Designing effective prompt templates involves understanding the model's nuances and your application's specific requirements. Well-crafted templates can significantly enhance the quality and relevance of the outputs, leading to better user satisfaction.
Orchestration and workflow management
Deploying an LLM application involves coordinating various tasks such as data preprocessing, model inference, and post-processing. Workflow management tools and orchestration frameworks like Apache Airflow or Kubernetes help automate and streamline these processes. They ensure that each component operates smoothly and efficiently, reducing the risk of errors and downtime.
Infrastructure and scalability
The infrastructure supporting your LLM application must be robust and scalable. This includes cloud services, hardware accelerators (like GPUs or TPUs), and networking capabilities. Scalability ensures that your application can handle increasing loads and user demands without compromising performance.
Utilizing auto-scaling policies and load-balancing strategies can help manage resources effectively and maintain service quality.
Monitoring and logging
Continuous monitoring and logging are critical for maintaining the health and performance of your LLM application. Monitoring tools provide real-time insights into system performance, usage patterns, and potential issues.
Logging mechanisms capture detailed information about the application's operations, which is invaluable for debugging and optimization. Together, they help ensure that your application runs smoothly and can quickly adapt to any changes or anomalies.
Security and compliance
Deploying LLMs also involves addressing security and compliance requirements. This includes safeguarding sensitive data, implementing access controls, and ensuring compliance with relevant regulations such as GDPR or HIPAA. Security measures must be integrated into every layer of the deployment process to protect against data breaches and unauthorized access.
Integration with existing systems
Your LLM application must seamlessly integrate with existing systems and workflows. This involves ensuring compatibility with other software tools, APIs, and data formats used in your organization.
Effective integration enhances the overall functionality and efficiency of your application, enabling it to leverage existing resources and infrastructure.
Different approaches for deploying LLMs into production
There are several approaches to deploying LLMs into production, each with its advantages and challenges.
On-premises deployment involves hosting the LLM on local servers or data centers, offering greater control over data and infrastructure but requiring significant investment in hardware and maintenance.
Cloud-based deployment leverages cloud services to host the LLM, providing scalability, flexibility, and reduced upfront costs, although it can introduce concerns about data privacy and ongoing operational costs.
Hybrid deployment combines on-premises and cloud resources, offering a balance between control and scalability, allowing organizations to optimize performance and cost based on their specific needs.
Understanding the pros and cons of each approach is essential for making an informed decision that aligns with your organization's goals and resources.
Top tools for productionizing LLMs
Deploying large language models (LLMs) into production requires a suite of tools that can handle various aspects of the deployment process, from infrastructure management to monitoring and optimization. In this section, we discuss five top tools that are widely used for deploying LLMs into production.
Each tool is evaluated based on scalability, ease of use, integration capabilities, and cost-effectiveness.
LangServe
LangServe is specifically designed for deploying LLM applications. It simplifies the deployment process by providing robust tools for installation, integration, and optimization. LangServe supports various LLMs and offers seamless integration with existing systems.
- Scalability: High
- Ease of Use: High
- Integration Capabilities: Excellent
- Cost-Effectiveness: Moderate
Kubernetes
Kubernetes is an open-source container orchestration platform that automates the deployment, scaling, and management of containerized applications. It's highly flexible and can be used to manage the infrastructure needed for LLM deployments.
- Scalability: High
- Ease of Use: Moderate
- Integration Capabilities: Excellent
- Cost-Effectiveness: High (Open Source)
TensorFlow Serving
TensorFlow Serving is a flexible, high-performance serving system for machine learning models, designed for production environments. It makes it easy to deploy new algorithms and experiments while keeping the same server architecture and APIs.
- Scalability: High
- Ease of Use: Moderate
- Integration Capabilities: Excellent
- Cost-Effectiveness: High (Open Source)
Amazon SageMaker
Amazon SageMaker is a fully managed service that provides every developer and data scientist with the ability to build, train, and deploy machine learning models quickly. It integrates with other AWS services, making it a comprehensive tool for LLM deployment.
- Scalability: High
- Ease of Use: High
- Integration Capabilities: Excellent (with AWS ecosystem)
- Cost-Effectiveness: Moderate to High (depending on usage)
MLflow
MLflow is an open-source platform to manage the ML lifecycle, including experimentation, reproducibility, and deployment. It provides a central repository for models and can be integrated with many machine-learning libraries.
- Scalability: Moderate to High
- Ease of Use: Moderate
- Integration Capabilities: Excellent
- Cost-Effectiveness: High (Open Source)
Summary
Tool
Scalability
Ease of Use
Integration Capabilities
Cost Effectiveness
LangServe
High
High
Excellent
Moderate
Kubernetes
High
Moderate
Excellent
High (Open Source)
TensorFlow Serving
High
Moderate
Excellent
High (Open Source)
Amazon SageMaker
High
High
Excellent (with AWS)
Moderate to High
MLflow
Moderate to High
Moderate
Excellent
High (Open Source)
Deploying an LLM Application Using LangServe
LangServe is a specialized tool designed to simplify the process of deploying LLM applications. In this section, we'll provide a technical walkthrough of using LangServe to deploy a chatGPT application to summarize text.
1. Installation
To begin, we need to install LangServe. You can install both client and server components or just one of them, depending on your needs.
pip install "langserve[all]"Powered ByAlternatively, you can install the components individually:
install "langserve[client]"Powered Byinstall "langserve[server]"Powered ByThe LangChain CLI is a useful tool to quickly bootstrap a LangServe project. Ensure you have a recent version installed:
install -U langchain-cliPowered By2. Setup
2.1 Create a new app
Use the LangChain CLI to create a new application, and change your current working directory to
my-app:app new my-appPowered ByThe text above is a code output or a data entry that complements the tutorial.
Was this helpful?my-appPowered ByThe text above is a code output or a data entry that complements the tutorial.
Was this helpful?2.2 Add third-party packages with Poetry
LangServe uses Poetry for dependency management. If you are not familiar with Poetry, refer to the Poetry documentation for more information.
To add the relevant packages, use:
add langchain-openai langchain langchain communityPowered ByThis command ensures all required dependencies are available for our project.
2.3 Set up environment variables
Ensure you set up the necessary environment variables for our application. In this case, we need to set our OpenAI API key to make valid requests:
OPENAI_API_KEY="sk-..."Powered ByMake sure to replace “sk-...” with your actual API key. You can create an API key via the OpenAI platform.
3. Server
Navigate to the ```server.py``` file. This will contain the main logic for our LangServe application. Here is an example of a simple LangServe application that includes a route to summarize text using OpenAI's language model:
fastapi import FastAPI from langchain.prompts import ChatPromptTemplate from langchain.chat_models import ChatOpenAI from langserve import add_routes app = FastAPI( title="LangChain Server", version="1.0", description="A simple API server using Langchain's Runnable interfaces", ) # Define a route for the OpenAI chat model add_routes( app, ChatOpenAI(), path="/openai", ) # Define a route with a custom prompt summarize_prompt = ChatPromptTemplate.from_template("Summarize the following text: {text}") add_routes( app, summarize_prompt | ChatOpenAI(), path="/summarize", ) if __name__ == "__main__": import uvicorn uvicorn.run(app, host="localhost", port=8000)Powered ByLet’s take a closer look at the key components of our basic LangServe application:
3.1 Import necessary modules
FastAPIis used to create the web server.ChatPromptTemplateandChatOpenAIare used from LangChain to define prompts and models.add_routesfrom LangServe is used to add routes to the FastAPI app.3.2 Initialize FastAPI app
- The
FastAPIapp is initialized with metadata such as title, version, and description.3.3 Add Routes
- The first
add_routesfunction call adds a route/openaithat directly interfaces with OpenAI’s chat model.- The second
add_routesfunction call defines a custom prompt route/summarize. This route takes input text and uses a prompt to generate a summarized version of the text using OpenAI’s model.4. Run the Server
The u
vicorn.runfunction is used to the start the FastAPI server onlocalhostat port 8000.In this example, we added a route
/summarizethat uses a prompt to summarize text. You can also extend the functionality of your LangServe application by defining additional routes and prompts. For instance:joke_prompt = ChatPromptTemplate.from_template("Tell me a joke about {topic}") add_routes( app, joke_prompt | ChatOpenAI(), path="/joke", )Powered By5. Serve your application
Finally, use Poetry to serve your application on the desired port:
run langchain serve --port=8100Powered ByIf everything is set up correctly, you should see something similar to this in your terminal:
Terminal output showing successful startup of the LangServe application.
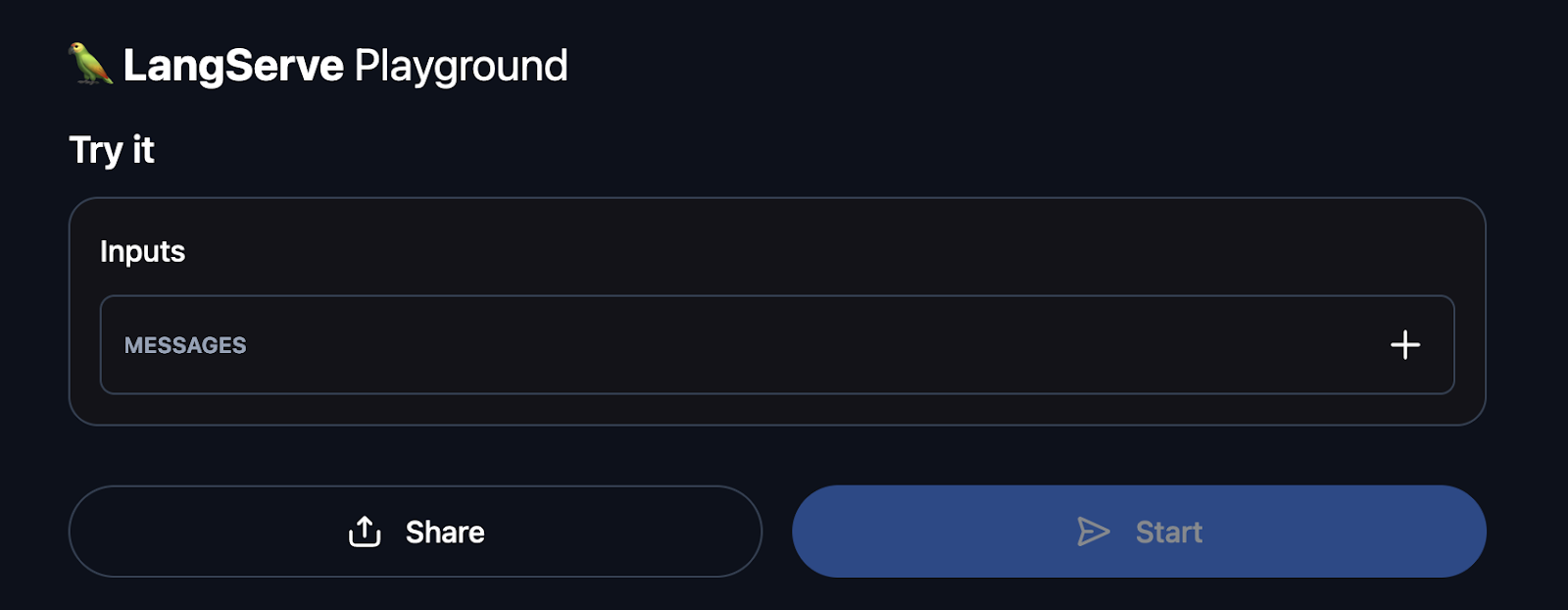
You can now navigate to http://127.0.0.1:8100/summarize/playground/ in your browser. This URL provides access to a user-friendly interface where you can test your application. T
he playground enables you to execute your runnable, view streaming output, and observe intermediate steps, facilitating easy interaction and debugging of your deployed LLM application.
Example of the LangServe playground UI
Additionally, you can visit http://127.0.0.1:8100/docs to access the automatically generated API documentation provided by FastAPI.
This interactive documentation allows you to explore and test all available endpoints of your LangServe application. You can see detailed information about each endpoint, including the required inputs and expected outputs, which helps understand how to interact with your API and for verifying that all routes are functioning correctly.
Monitoring an LLM Application Using LangServe
Ensuring the reliability, performance, and accuracy of a Large Language Model (LLM) application in production is crucial. Although LangServe lacks built-in monitoring features, it seamlessly integrates with widely used tools for tracking and analyzing application health.
This section offers a technical walkthrough of how to use LangServe in conjunction with these tools to maintain and oversee an LLM application.
1. Setting up logging
Logging is the first step in monitoring your LLM application. It helps in tracking the application's behavior and identifying any anomalies. Here’s how you can set up logging in your FastAPI application with LangServe:
import logging # Configure logging logging.basicConfig(level=logging.INFO) logger = logging.getLogger("langchain_server") app = FastAPI() # Example of logging within a route @app.get("/status") async def status(): logger.info("Status endpoint was called") return {"status": "Running"}Powered ByWith this setup, every call to the
/statusendpoint will log a message indicating the endpoint was accessed. This can be extended to log other significant events and errors.2. Integrating Prometheus for metrics
Prometheus is a popular tool for monitoring and alerting. It can be integrated with FastAPI to collect metrics and provide insights into the application's performance. Here’s how you can set up Prometheus with LangServe:
2.1 Install the Prometheus client
install prometheus_clientPowered By2.2 Update server.py to include Prometheus middleware
import time from prometheus_client import start_http_server, Summary from fastapi.middleware import Middleware # Start Prometheus server start_http_server(8001) # Define a Prometheus metric REQUEST_TIME = Summary('request_processing_seconds', 'Time spent processing request') app = FastAPI() # Middleware for tracking request processing time @app.middleware("http") async def add_prometheus_middleware(request: Request, call_next): start_time = time.time() response = await call_next(request) duration = time.time() - start_time REQUEST_TIME.observe(duration) return responsePowered ByThis setup will start a Prometheus server on port 8001 and track the time taken to process each request.
Setting up alerts with Prometheus and Grafana
Prometheus can be configured to trigger alerts based on certain conditions, and Grafana can be used to visualize these metrics. Here’s a brief outline for setting up alerts:
3.1 Configure Prometheus alert rules
Create a file called
alert.rules:groups: - name: example rules: - alert: HighRequestLatency expr: request_processing_seconds_bucket{le="0.5"} > 0.5 for: 5m labels: severity: page annotations: summary: High request latency description: "Request latency is above 0.5 seconds for more than 5 minutes."Powered By3.2 Configure Prometheus to use the alert rules
Update your Prometheus configuration (
prometheus.yml):rule_files: - "alert.rules"Powered By3.2 Setup Grafana for visualization
To install and configure Grafana refer to the installation and configuration documentation. Once set up, you can proceed to create dashboards and panels to visualize metrics like request latency, error rates, etc.
4. Implementing health checks
Health checks are essential for monitoring the application’s health and ensuring it is running as expected. Here’s how we can do a simple health check endpoint:
@app.get("/health") async def health(): return {"status": "Healthy"}Powered ByThis endpoint can be called periodically by monitoring tools to ensure the application is healthy.
5. Monitoring errors and exceptions
Capturing and monitoring errors and exceptions is crucial for identifying issues in the application. Here’s how you can extend logging to capture exceptions:
from fastapi import Request, HTTPException from fastapi.responses import JSONResponse @app.exception_handler(Exception) async def global_exception_handler(request: Request, exc: Exception): logger.error(f"An error occurred: {exc}") return JSONResponse(status_code=500, content={"message": "Internal Server Error"}) @app.exception_handler(HTTPException) async def http_exception_handler(request: Request, exc: HTTPException): logger.error(f"HTTP error occurred: {exc.detail}") return JSONResponse(status_code=exc.status_code, content={"message": exc.detail})Powered ByWith this setup, any unhandled exception will be logged, providing insights into potential issues.
Closing Thoughts
Deploying large language models (LLMs) into production can transform your applications, but the process involves navigating complexities like model selection, resource management, and integration. LangServe simplifies these challenges, enabling developers to deploy, monitor, and maintain LLM applications efficiently.
By using LangServe, you can streamline deployment, ensure robust performance, and achieve seamless integration with your systems.
For a deeper dive into building and deploying LLM applications, consider exploring the Developing LLM Applications with LangChain course on DataCamp. This resource covers essential topics including chatbot creation, integrating external data using the LangChain Expression Language (LCEL), and more.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号