Welcome to the second post in the “Mastering RAG Chatbots” series, where we delve into the powerful concept of semantic router for building advanced Retrieval-Augmented Generation (RAG) applications tailored for production.
In this post, we will explore the concept of semantic router — intelligent gateway that leverage semantic similarity to streamline query management and enhance the capabilities of advanced RAG models for production environments. As these natural language processing systems grow increasingly sophisticated, handling diverse topics and use cases becomes a challenge. Semantic router emerge as a powerful solution, acting as intelligent gateway that direct incoming queries to the appropriate response or action pipeline based on their semantic content, thereby enabling the building of modular, scalable RAG applications suited for production.
By using a semantic router in your RAG application, you gain better control over handling queries. This smart component uses semantic similarity to route incoming requests to the right response pipeline, action, or tool. With a semantic router, you can avoid answering questions outside your RAG’s intended scope. It also allows you to seamlessly integrate actions like triggering specific functions, using external tools, or implementing FAQ’s caching routes for reducing costs and efficiency. Overall, the semantic router helps build modular RAG solutions suited for production. The semantic router is the first step to adding guardrails to our application, ensuring it operates within defined boundaries.
The Concept of Semantic Router in RAG applications
Let’s dive into the practical implementation of a semantic router for a Vacation Recommendations RAG model. By leveraging the power of semantic similarity, we will explore how a semantic router can intelligently manage the flow of incoming queries, routing them to the appropriate response pipeline or action executor. One of the main advantages of using a semantic router is that it significantly reduces the need for prompt engineering work. When trying to restrict a language model using prompt engineering, we risk altering or breaking well-crafted prompts, which can change the behavior and flavor of good responses. Each modification to the prompt affects the probabilities of the next words, potentially leading to partial or poor answers. By controlling unwanted topics outside the prompt, we can avoid these permanent costs (as system prompts are attached to each prompt sent to the LLM), allowing our RAG application to focus solely on providing accurate answers within its domain.
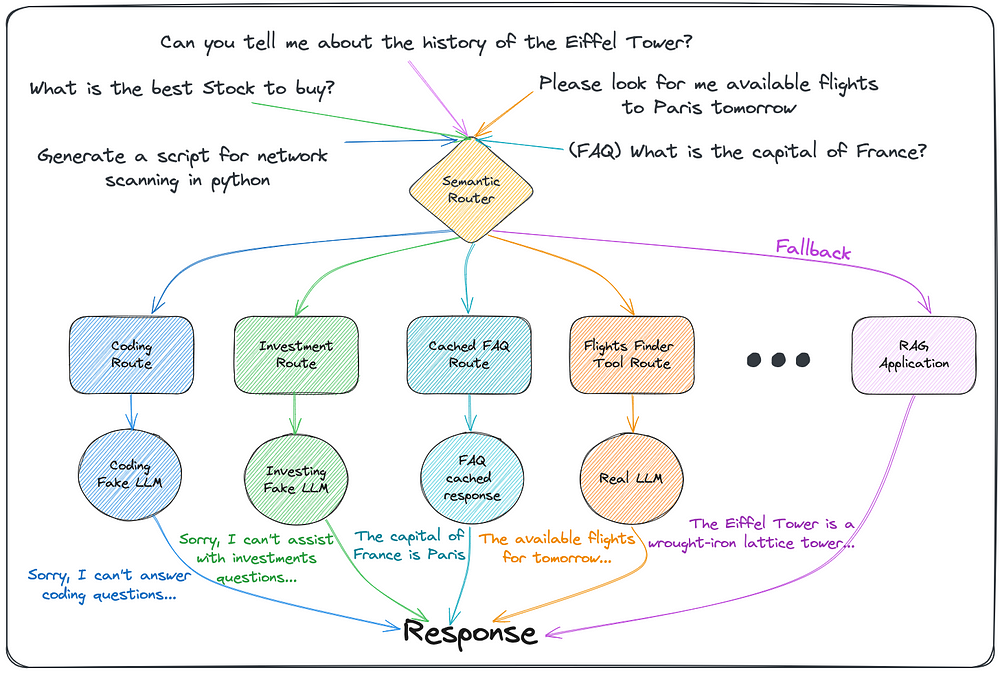
We will begin by illustrating a typical message flow, showcasing how queries are processed and how we can tailor our responses or actions based on the identified route. Our goal is to ensure that our Vacation Recommendations RAG remains focused on its intended domain, avoiding unrelated topics such as coding or investments.
Furthermore, we will show how a semantic router can serve as an alternative to traditional language model agents, enabling seamless integration of external tools and functionalities. This includes the creation of dynamic routes for frequently asked questions (FAQs), facilitating cost savings and efficient query handling.
Semantic Router Gateway — Queries Flow
The routes are:
Coding and Investments routes: Unwanted topics that our RAG should avoid responding to.
Cached FAQ route: A dynamic route for frequently asked questions, leveraging caching mechanisms for cost efficiency.
Specific action route: A route dedicated to performing actions using external tools or integrations. In this specific example we want to use a flights finder tool.
Fallback route: The default route for querying the Vacation Recommendations RAG when no specific action or tool is required.
By adopting a “negative perspective” approach, we will focus on creating routes for unwanted topics at first, rather than attempting to overly restrict the domain of questions our RAG can answer. Our preference is to initially allow answering a wider scope of queries, even if some are unwanted, and then gradually block off specific topics as necessary. This proactive approach ensures that we avoid inadvertently filtering out valid queries that users rightfully expect our system to handle. We want to prevent users from feeling that our RAG’s scope is too narrow or that the quality is compromised by an overly restrictive domain boundary. The goal is to provide a comprehensive and high-quality experience, while retaining the ability to dynamically manage and refine the system’s scope as needed.
Aurelio.AI Sematic Router python Library
We will utilize the Aurelio.AI Python library and extend its capabilities for implementing our semantic router. Additionally, we will work with Langchain.
Install the semantic-router library with this command:
running this example we will also use pytorch, transformers, langchain libraries.
Unrealted Topics Implementation
To handle topics we want to avoid answering and save costs, we’ll create a dummy LLM with predefined responses. We’ll extend the route class in the semantic-router library to support our dummy LLM. Additionally, we’ll implement a semantic router chain using Langchain to catch unrelated topics and return a predefined answer to the user. This approach allows us to generate hardcoded responses for unwanted topics, preventing our RAG model from attempting to answer them and potentially providing inaccurate or irrelevant information. By offloading these topics to a separate component with predefined responses, we can ensure our RAG model stays focused on its core domain while still providing a graceful response to the user.
Mastering RAG Chatbots: Semantic Router — User Intents
In my third post in the “Mastering RAG Chatbots” series, we will explore the use of semantic routers for intent classification in Retrieval-Augmented Generation (RAG) chatbot applications.
Building conversational AI applications requires understanding the user’s intent behind their query. A semantic router helps disambiguate intent and route queries appropriately. User intent represents the goal or task the user wants to accomplish — are they looking for instructions, recommendations, or specific product details? Understanding intent is key to providing relevant responses in a RAG application.
Controlling User Intents Flow
A semantic router analyzes queries semantically to classify intent. Based on this, it controls which knowledge resources to retrieve from, which prompts, tools or functions to use for generating a tailored response. Properly routing by intent ensures coherent answers mapped to what the user is truly asking.
While powerful, semantic routing for intent control faces key challenges like determining optimal similarity thresholds, handling no-match cases gracefully, properly accounting for sub-intents and variants, resolving ambiguous utterances across multiple intents, and ongoing maintenance of intent taxonomies and training data as the application evolves. When implemented effectively though, it elevates the user experience by precisely understanding needs.
This post dives into the key advantages that semantic routing provides, tackling key challenges using semantic router for intent classification.
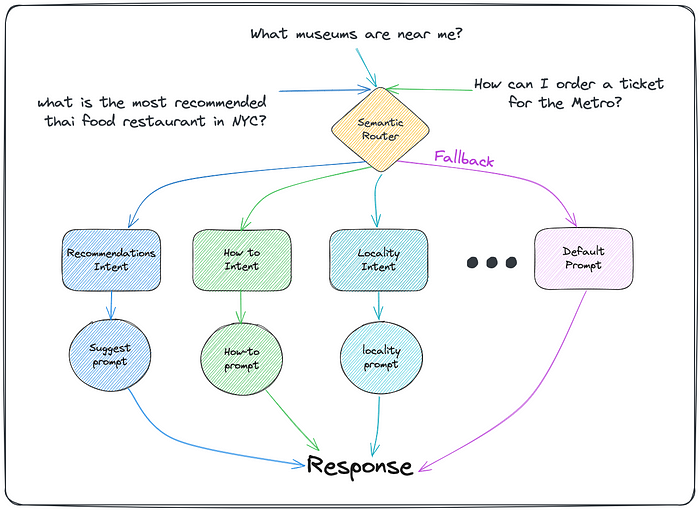
Mapping User Intents to Routes
Building on the “RAG gateway” example from the previous post, we want to define routable intents for our Vacation Recommendations RAG application. The “recommendations” intent indicates the user is looking for vacation suggestions, so we’ll route these queries to retrieve and generate relevant recommendation ideas from our data. For the “how-to” intent, the user is asking for instructions, so we’ll route to access guides and FAQs to provide helpful guidance. The “locality” intent captures when users reference a specific location or ask about nearby options, directing these to geo-based data sources. Finally, a “default” route will handle general queries with no clearly defined intent, attempting to provide a useful response. Defining these intents and their corresponding routing policies allows us to appropriately steer queries to the right knowledge sources and response generation flows within the RAG application.
Queries Flow Diagram of User Intents
For the recommendations intent route, we want to ensure any suggestions provided to the user are backed by our own data sources, not just the LLM’s general knowledge. Our goal is to give users the best recommendation responses tailored to our domain. If we don’t have a reliable data source to draw recommendations from, we’ll avoid making generic suggestions and simply state that we don’t have any recommendations available. To achieve this, we’ll define a set of recommendation utterances in a JSON file to accurately identify when a user is seeking a recommendation versus other types of queries. This allows us to precisely route recommendation requests to our curated data pipeline.
{ "name": "recommendations", "score_threshold": 0.7, "utterances": [ "Can you recommend a good beach destination for a family vacation?", "I'm looking for suggestions on romantic getaways for couples.", "What are some popular outdoor adventure vacation ideas?", "Do you have any recommendations for budget-friendly vacations?", "I'd like to plan a trip for my upcoming anniversary. Can you suggest some options?", "Can you recommend a family-friendly resort with activities for kids?", "I'm interested in a cultural vacation. What cities would you recommend visiting?", "Do you have any suggestions for a relaxing spa vacation?", "I'm looking for vacation ideas that combine hiking and sightseeing.", "Can you recommend an all-inclusive resort with good reviews?" ] }
Leveraging a semantic router for intent classification offers several key advantages over traditional monolithic prompt approaches. By breaking down long, complex prompts into focused sub-prompts mapped to specific intents, we can improve accuracy and reduce ambiguity. The “divide and conquer” approach allows us to precisely target the language model’s capabilities for each intent type.
Additionally, a router architecture provides flexibility to add, edit or remove intents on-the-fly without disrupting the entire system. We can continuously refine and enhance prompts for different areas as needed. This modularity also enables targeted evaluation and improvement processes — pinpointing strengths and weaknesses across various intents. Over time, this focused iteration promotes consistent progress toward an increasingly robust and capable conversational AI system.
Intent Routing Challenges
Implementing effective intent routing with a semantic router faces several challenges:
Determining the optimal similarity threshold for each route
Handling no-match cases
Sub-intents and Variants
Ambiguous cross-intent utterances
Let’s explore some strategies to overcome this key intent routing challenges.
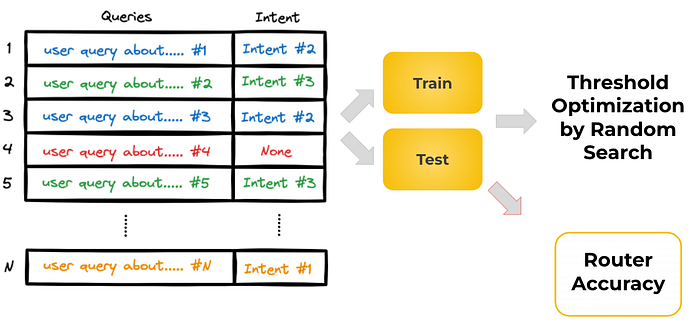
To find the optimal similarity thresholds for our intent routes, we build a training set containing relevant user queries labeled with their corresponding intents. Importantly, we also include queries without a matching intent to account for no-match scenarios. The data is split into train and validation sets, ensuring a balanced distribution of intents. We then perform a random search optimization using the training set to identify thresholds that route the validation queries to the correct intent labels with the highest accuracy. This process can be executed whenever adding or editing intents.
Intents Threshold Optimization Process
Including no-intent queries helps prevent overfitting to only existing intents. It allows the router to appropriately route unmatched cases to a fallback flow. Maintaining a balanced validation set ensures the thresholds are robust across all intent types. This data-driven approach to threshold tuning, combined with graceful no-match handling, enhances the router’s reliability in production settings.
Sub-Intent Variations & Ambiguous Cross Intent
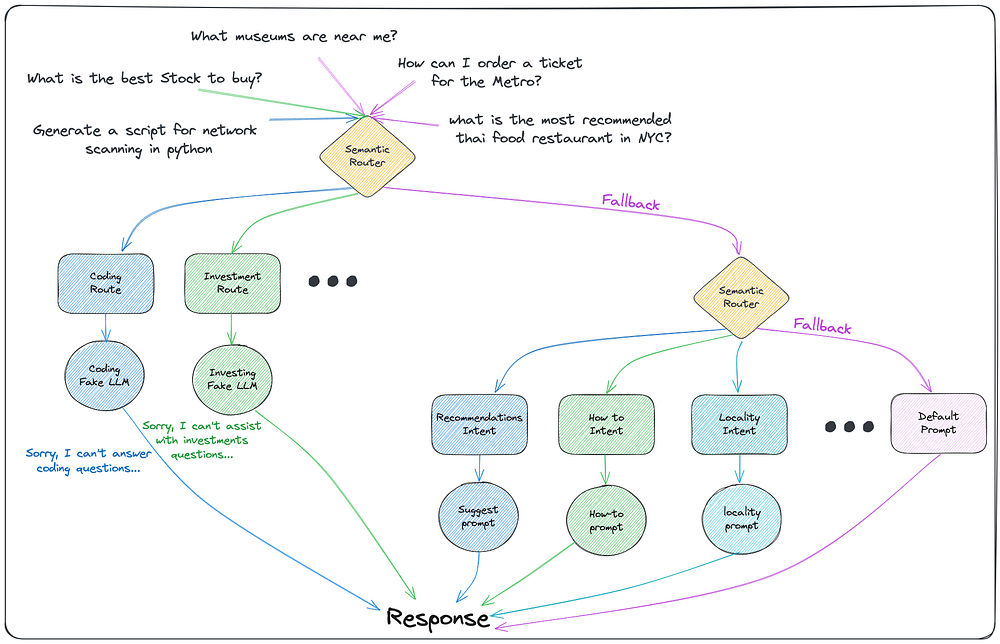
For certain major intents, further granularity may be required through sub-intent classification. In such cases, we can employ an inner router architecture. For example, building on the guardrails router concept from the previous post, we could use it as an inner router for intent classification after the initial gateway routing we used for guardrails. This nested approach allows us to first identify a broad intent category, then dive deeper to disambiguate specific sub-intents within that category using the inner router’s semantic understanding capabilities. The diagram below illustrates this concept of using the guardrails router for an additional sub-intent resolution stage.
This post explored using a semantic router for intent classification in conversational AI apps like chatbots — a cool concept with great advantages. The router analyzes queries to figure out the user’s intent, then routes it to the proper response pipeline. This allows breaking down complex queries into focused prompts per intent for better accuracy, plus flexibility to easily tweak intents without overhauling everything. The modular setup aids continuous improvement too. But nailing the implementation has challenges, like determining optimal similarity thresholds, gracefully handling no-matches, accounting for sub-intent nuances with nested routers, resolving ambiguities, and enabling ongoing refinement. The post covered strategies for tackling these hurdles to build robust intent routing capabilities that elevate the conversational experience.
Mastering RAG Chabots: The Road from a POC to Production
In my “Mastering RAG Chatbots” series, we’ve been exploring the details of building advanced Retrieval-Augmented Generation (RAG) models for production environments, addressing critical challenges along the way. Throughout our journey so far, we’ve covered specific topics that help facilitate the way to production, such as conventional RAG architectures, intent classification, guardrails, and prompt routing strategies. However, in this post, we’ll shift our focus to a higher-level perspective, concentrating more on product design aspects rather than solely research and development considerations.
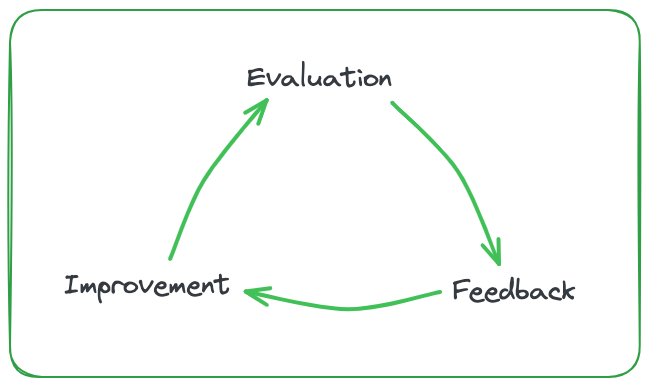
The RAG Application Production Triangle
Transforming a promising prototype into a reliable, scalable solution requires careful planning and execution. At the heart of this journey lies the “triangle of evaluation, feedback, and improvement” — a continuous cycle that ensures your RAG application remains robust, relevant, and responsive to user needs. In this post, we’ll dive deep into each stage of this triangle, emphasizing the importance of proactive planning before embarking on the development process. By establishing a well-defined evaluation framework, gathering insightful feedback, and implementing targeted improvements, you can navigate the road to production with confidence, delivering a chatbot that exceeds expectations and provides a a high quality user experience.
Transitioning a RAG chatbot from proof-of-concept to production requires careful planning of the evaluation, feedback, and improvement cycle. We need to define clear metrics to measure the chatbot’s accuracy and performance, and implement ways to collect valuable user feedback. This feedback, combined with metric evaluations, will guide the necessary steps to improve the chatbot. Some improvements can be automated, while others may need manual input.
The goal is to create an ongoing cycle of evaluation, feedback, and improvement. As this cycle continues, the chatbot becomes increasingly robust, accurate, and aligned with user needs, making it truly production-ready. Consistent iteration based on real-world performance is key to delivering an exceptional user experience.
Evaluation Stage
For effective evaluation, we’ll define KPIs to measure the chatbot’s accuracy across different answer types — informative responses, conversational exchanges, and guardrail outputs. Beyond individual answers, we’ll also assess entire conversations. Key quality characteristics include:
Accuracy: Is the information correct ?
Completeness: Does the answer cover all relevant points ?
Conciseness: Is it free from irrelevant details ?
Fluency: Is the phrasing clear and understandable ?
Structure: Is the information properly formatted ?
To determine conversation quality, we’ll seek user feedback at the end (e.g. thumbs up/down on helpfulness). These metrics will guide our feedback collection process, allowing us to focus areas for improvement iteratively.
We can also add more quality characteristics, as it really depends on the use case. For example, click-through rates for links attached to RAG answers, or counter metrics like the percentage of queries the bot doesn’t answer — both those filtered before reaching the engine and in-scope queries the engine couldn’t provide an answer for.
We can also collect additional health measurements from the application to determine its performance and identify potential issues. Some key metrics include:
Application Responses Data:
Average number of words per answer
Average number of queries per user per day/week/month
Time to first word of the answer supplied to customer
Time to completed answer supplied to customer
Service availability (target: 0.99 uptime)
Users Impact:
Bi-weekly/monthly satisfaction feedback from customers
Monitoring these measurements alongside the quality characteristics provides a comprehensive view into the chatbot’s operations. This data-driven approach enables us to proactively address bottlenecks, optimize response times, and ensure a high-quality user experience.
Feedback Stage
In the feedback stage, we’ll leverage the KPIs defined during the evaluation step to collect targeted feedback from users. For each answer received, users will be prompted to provide a yes/no rating on various quality aspects:
Is the answer accurate? (Target: 90% of answers)
Is the answer complete? (Target: 80% of answers)
Is the answer concise? (Target: 80% of answers)
Is the answer fluent? (Target: 90% of answers)
Is the answer well-structured? (Target: 80% of answers)
By setting clear success criteria for each quality metric, we can quantify user satisfaction and pinpoint areas that require improvement. This granular feedback, combined with broader metrics like overall conversation helpfulness, provides a comprehensive view of the chatbot’s performance. Systematically collecting and analyzing this user input is crucial for driving the next stage: implementing targeted enhancements to improve the chatbot’s capabilities.
We decided to make the feedback binary (yes/no) to avoid creating overly complex data that could be difficult to analyze and take actionable improvements from. Asking users to rate answers on a scale from 1 to 5, for example, presents a couple of challenges. First, some users may try to avoid this more complicated rating task. Additionally, most users are not experienced enough to provide nuanced ratings consistently. However, determining whether an answer is accurate or not (yes/no) is a much more straightforward task for users. By keeping the feedback simple and binary, we ensure higher participation rates and more reliable data to work with. This focused approach allows us to quickly identify areas that objectively require improvement without getting slowed down by subjective interpretations of multi-point rating scales.
I also encourage adding an optional free text comment field to the feedback form. While the binary yes/no answers help simplify the complexity of the feedback data for analysis, they may not capture all the nuances users want to express. A free text field gives users the ability to provide more informative responses and convey their true feelings or observations. This additional qualitative feedback offers another valuable dimension that can be analyzed to expose potential blind spots and drive further improvements. Of course, the free text comment would be optional and not required from users providing feedback.
The Feedback Form Example
Improvement Stage
The improvement stage utilizes the feedback collected according to the evaluation KPIs to drive enhancements in the system’s performance. Improvements can be implemented through various techniques like model fine-tuning, prompt engineering, and optimizing information retrieval methods. The approach depends on factors such as the volume of training data collected, and the specific areas requiring improvement, such as increasing answer accuracy, mitigating unwanted topic responses (guardrails), reducing hallucinations, or addressing incomplete answers.
In the initial production stages when training data was limited, we focused on improving model answers by defining user intents and enhancing information retrieval. User intents were mapped using a semantic routing approach, like discussed in my previous post, with dedicated prompts for each intent. This prompt hierarchy allowed for agile improvements by refining existing prompts, adding new intents, or splitting intents through prompt engineering. Concurrently, we employed hybrid search techniques combining semantic and keyword similarity to prioritize the most relevant information sources, thereby improving the model’s access to accurate and complete information.
These techniques facilitated a gradual rollout process, starting small to refine the application before scaling up. We began with an internal release to a dedicated, trained user base, guiding them on application usage and collecting quality feedback. After iterative improvements, we expanded to a larger internal audience. Once the internal release achieved a satisfactory performance level, we replicated this phased rollout with production customers, onboarding them gradually while continuously enhancing the application until full-scale deployment.
Summary
In this post we discussed on the critical cycle of evaluation, feedback, and improvement for transitioning a RAG chatbot from proof-of-concept to production-ready. We covered defining clear KPIs in the evaluation stage to measure answer and conversation quality. The feedback stage emphasized simple binary user inputs supplemented by optional comments to collect reliable data.
In the improvement stage, techniques like prompt engineering, model fine-tuning, and hybrid information retrieval were highlighted to address specific areas of improvement identified through feedback. A gradual rollout strategy was recommended, starting with a small internal release before incrementally expanding the user base.
Patience is required! this iterative approach ensures a positive user experience from launch. Carefully executing this cycle transforms a promising RAG model into a robust, user-centric chatbot. I hope you enjoyed reading this post, stay tuned :)



 浙公网安备 33010602011771号
浙公网安备 33010602011771号