pyttsx3 and its alternatives
pyttsx3
https://github.com/nateshmbhat/pyttsx3
效果太差。
pyttsx3is a text-to-speech conversion library in Python. Unlike alternative libraries, it works offline.
- ✨Fully OFFLINE text to speech conversion
- 🎈 Choose among different voices installed in your system
- 🎛 Control speed/rate of speech
- 🎚 Tweak Volume
- 📀 Save the speech audio as a file
- ❤️ Simple, powerful, & intuitive API
If you are on a linux system and if the voice output is not working , then :
Install espeak , ffmpeg and libespeak1 as shown below:
sudo apt update && sudo apt install espeak ffmpeg libespeak1
- sapi5
- nsss
- espeak
推荐其他的引擎
当然可以推荐其他的语音引擎。如果对pyttsx3的语音引擎不满意,以下是一些替代方案,它们提供了更高质量的语音合成服务:
Google Text-to-Speech (gTTS)
- 简介:Google提供了一个强大的文本到语音转换服务,可以通过gTTS库在Python中使用。
- 特点:支持多种语言和声音效果,具有良好的语音质量。
- 使用场景:适用于需要高质量语音合成的应用场景,如语音助手、语音导航等。
Microsoft Azure Cognitive Services
- 简介:Azure提供了一系列的认知服务,其中包括语音服务。可以使用Azure的语音服务API来实现文本到语音的转换。
- 特点:支持多种语言和声音效果,具有高质量的语音合成能力。
- 使用场景:适用于企业级应用,特别是需要与Azure其他服务集成的场景。
Baidu Text-to-Speech (Baidu TTS)
- 简介:百度提供了一个文本到语音的转换服务,可以通过Baidu TTS库在Python中使用。
- 特点:支持多种语言和声音效果,具有良好的语音质量和自然度。
- 使用场景:适用于需要中文语音合成的应用场景,如中文语音助手、中文语音导航等。
EmotiVoice
- 简介:EmotiVoice是一款来自GitHub的强大开源TTS引擎,完全免费,支持中英文双语。
- 特点:包含2000多种不同的音色,以及特色的情感合成功能,支持合成包含快乐、兴奋、悲伤、愤怒等广泛情感的语音。
- 使用场景:适用于需要多角色、多语言和多种情绪语音合成的应用场景,如角色扮演游戏、情感化语音助手等。
ekho
- 简介:ekho是一个免费、开源的中文语音合成软件,支持Linux、Windows和Android平台。
- 特点:支持粤语、普通话(国语)、诏安客语、藏语、雅言(中国古代通用语)和韩语(试验中),英文则通过eSpeak或者Festival间接实现。
- 使用场景:适用于需要在多个平台上进行中文语音合成的应用场景。
在选择替代方案时,建议根据具体需求和场景进行评估和决策。同时,也需要注意不同语音引擎的兼容性、性能以及成本等因素。
当然,除了之前提到的语音引擎外,还有以下一些选项可供选择:
- Amazon Polly
- 简介:Amazon Polly是亚马逊云提供的一项服务,可将文本转换为逼真的语音。
- 特点:支持多种语言和声音(包括男声和女声),具有高质量的语音合成效果。
- 使用场景:适用于需要高质量语音合成的企业级应用,特别是与亚马逊云其他服务集成的场景。
- IBM Watson Text to Speech
- 简介:IBM Watson Text to Speech是IBM Watson平台提供的一项服务,可将文本转换为自然流畅的语音。
- 特点:支持多种语言和声音,具有高度的自然度和可定制性。
- 使用场景:适用于需要高质量、高度定制化的语音合成的企业级应用。
- 百度语音合成技术(Baidu Speech Synthesis)
- 简介:百度语音合成技术是百度AI开放平台提供的一项服务,可将文本实时转换为流畅的语音。
- 特点:支持多种语言和声音效果,具有高质量的语音合成能力和良好的自然度。
- 使用场景:适用于需要中文语音合成的各种应用场景,如语音助手、语音导航、有声阅读等。
- 阿里云语音合成(Alibaba Cloud Text to Speech)
- 简介:阿里云语音合成是阿里云提供的一项服务,可将文本转换为语音,支持多种语言。
- 特点:具有高质量的语音合成效果,支持多种声音和语速调节。
- 使用场景:适用于需要高质量语音合成的企业级应用,特别是与阿里云其他服务集成的场景。
- 科大讯飞语音合成(iFLYTEK Text to Speech)
- 简介:科大讯飞是中国领先的智能语音技术提供商,其语音合成技术具有高度的自然度和准确性。
- 特点:支持多种语言和声音效果,具有高质量的语音合成能力和丰富的定制选项。
- 使用场景:适用于需要高质量中文语音合成的各种应用场景,如语音助手、语音导航、有声阅读等。
在选择语音引擎时,建议根据具体需求、应用场景、预算以及兼容性等因素进行综合考虑。同时,也需要注意不同语音引擎的性能、自然度、声音种类以及可定制性等方面的差异。
EmotiVoice 一分钟完美克隆你的声音!完全开源、多音色、多情感、可提示、可控制的文本生成语音工具
https://github.com/netease-youdao/EmotiVoice/tree/main
EmotiVoice is a powerful and modern open-source text-to-speech engine that is available to you at no cost. EmotiVoice speaks both English and Chinese, and with over 2000 different voices (refer to the List of Voices for details). The most prominent feature is emotional synthesis, allowing you to create speech with a wide range of emotions, including happy, excited, sad, angry and others.
An easy-to-use web interface is provided. There is also a scripting interface for batch generation of results.
https://zhuanlan.zhihu.com/p/678600601
https://zhuanlan.zhihu.com/p/669118264
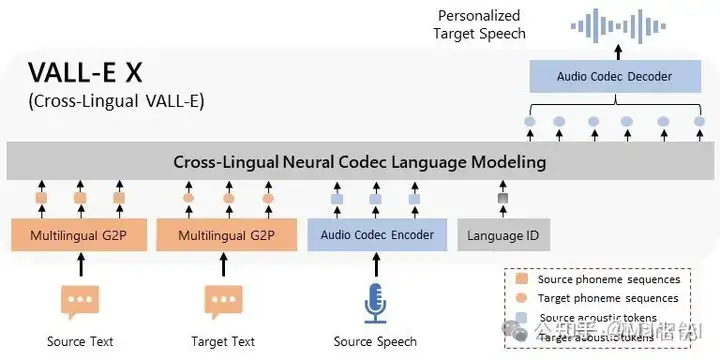
VALL-E X: 多语言文本到语音合成与语音克隆
VALL-E X 是一个强大而创新的多语言文本转语音(TTS)模型,最初由微软发布。虽然微软最初在他们的研究论文中提出了该概念,但并未发布任何代码或预训练模型。我们认识到了这项技术的潜力和价值,复现并训练了一个开源可用的VALL-E X模型。
预训练模型现已向公众开放,供研究或应用使用
,让每个人都能体验到
TTS的威力。
VALL-E X 配备有一系列尖端功能
- 多语言 TTS: 可使用三种语言 - 英语、中文和日语 - 进行自然、富有表现力的语音合成。
- 零样本语音克隆: 仅需录制任意说话人的短短的 3~10 秒录音,VALL-E X 就能生成个性化、高质量的语音,完美还原他们的声音
- 。
- 语音情感控制: VALL-E X 可以合成与给定说话人录音相同情感的语音,为音频增添更多表现力。
- 零样本跨语言语音合成: VALL-E X 可以合成与给定说话人母语不同的另一种语言,在不影响口音和流利度的同时,保留该说话人的音色与情感。
- 口音控制: VALL-E X 允许您控制所合成音频的口音,比如说中文带英语口音或反之。
- 声学环境保留: 当给定说话人的录音在不同的声学环境下录制时,VALL-E X 可以保留该声学环境,使合成语音听起来更加自然。
GPT-SoVITS只需1分钟语音即可训练一个自己的TTS模型
https://github.com/RVC-Boss/GPT-SoVITS
GPT-SoVITS是一个声音克隆和文本到语音转换的开源 Python RAG框架。 5秒数据就能模仿你,1分钟的声音数据就能训练出一个高质量的TTS模型
,完美克隆你的声音! 根据演示来看完美适配中文,应该是目前中文支持比较好的模型。
界面也易用。主要特点:
1、零样本 TTS: 输入5 秒的声音样本即可体验即时的文本到语音转换。
2、少量样本训练: 只需 1 分钟的训练数据即可微调模型,提高声音相似度和真实感。模仿出来的声音会更加接近原声,听起来更自然。 跨语言支持: 支持与训练数据集不同语言的推理,目前支持英语、日语和中文。
3、易于使用的界面:集成了声音伴奏分离、自动训练集分割、中文语音识别和文本标签等工具,帮助初学者更容易地创建训练数据集和 GPT/SoVITS 模型。
4、适用于不同操作系统: 项目可以在不同的操作系统上安装和运行,包括 Windows。
5、预训练模型: 项目提供了一些已经训练好的模型,你可以直接下载使用。

coqui-ai/TTS
https://github.com/coqui-ai/TTS
- High-performance Deep Learning models for Text2Speech tasks.
- Text2Spec models (Tacotron, Tacotron2, Glow-TTS, SpeedySpeech).
- Speaker Encoder to compute speaker embeddings efficiently.
- Vocoder models (MelGAN, Multiband-MelGAN, GAN-TTS, ParallelWaveGAN, WaveGrad, WaveRNN)
- Fast and efficient model training.
- Detailed training logs on the terminal and Tensorboard.
- Support for Multi-speaker TTS.
- Efficient, flexible, lightweight but feature complete
Trainer API.- Released and ready-to-use models.
- Tools to curate Text2Speech datasets under
dataset_analysis.- Utilities to use and test your models.
- Modular (but not too much) code base enabling easy implementation of new ideas.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号