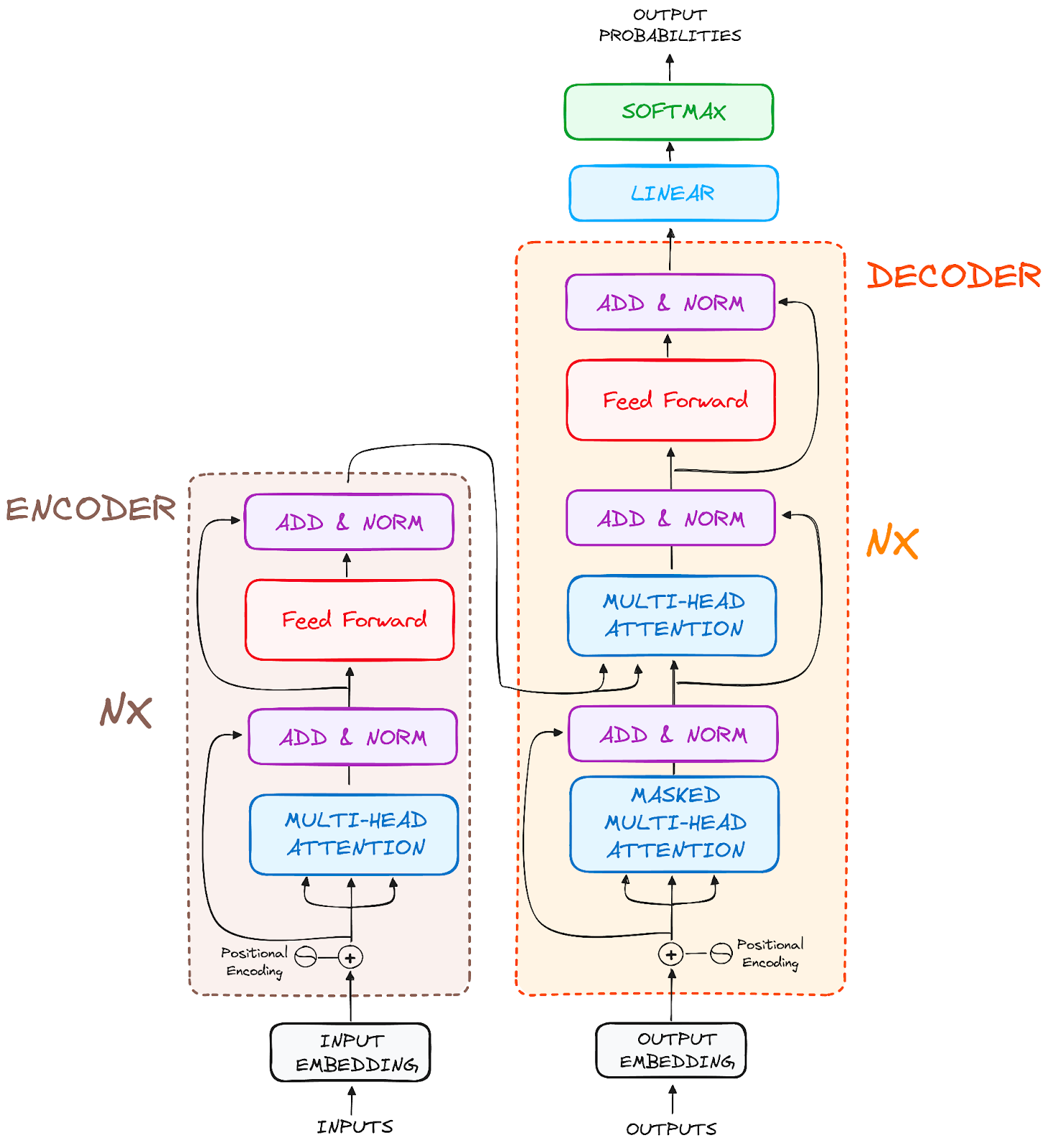
transformer model architecture
transformer model architecture
https://www.datacamp.com/tutorial/how-transformers-work
动手写
https://www.datacamp.com/tutorial/building-a-transformer-with-py-torch
Attention
https://www.cnblogs.com/jins-note/p/13056604.html
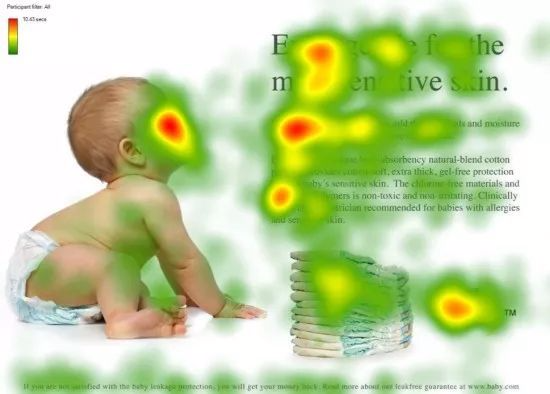
人类的视觉注意力
从注意力模型的命名方式看,很明显其借鉴了人类的注意力机制,因此,我们首先简单介绍人类视觉的选择性注意力机制。
图1 人类的视觉注意力
视觉注意力机制是人类视觉所特有的大脑信号处理机制。人类视觉通过快速扫描全局图像,获得需要重点关注的目标区域,也就是一般所说的注意力焦点,而后对这一区域投入更多注意力资源,以获取更多所需要关注目标的细节信息,而抑制其他无用信息。
这是人类利用有限的注意力资源从大量信息中快速筛选出高价值信息的手段,是人类在长期进化中形成的一种生存机制,人类视觉注意力机制极大地提高了视觉信息处理的效率与准确性。
图1形象化展示了人类在看到一副图像时是如何高效分配有限的注意力资源的,其中红色区域表明视觉系统更关注的目标,很明显对于图1所示的场景,人们会把注意力更多投入到人的脸部,文本的标题以及文章首句等位置。
深度学习中的注意力机制从本质上讲和人类的选择性视觉注意力机制类似,核心目标也是从众多信息中选择出对当前任务目标更关键的信息。
https://blog.csdn.net/weixin_42392454/article/details/122478544
1、什么是attention?
在人类的理解中,对待问题是有明显的侧重。具体举个例子来说:“我喜欢踢足球,更喜欢打篮球。”,对于人类来说,显然知道这个人更喜欢打篮球。但对于深度学习来说,在不知道”更“这个字的含义前,是没办法知道这个结果的。所以在训练模型的时候,我们会加大“更”字的权重,让它在句子中的重要性获得更大的占比。比如:
C ( s e q ) = F ( 0.1 ∗ d ( 我 ) , 0.1 ∗ d ( 喜 ) , . . . , 0.8 ∗ d ( 更 ) , 0.2 ∗ d ( 喜 ) , . . . ) C(seq) = F(0.1*d(我),0.1*d(喜),...,0.8*d(更),0.2*d(喜),...) C(seq)=F(0.1∗d(我),0.1∗d(喜),...,0.8∗d(更),0.2∗d(喜),...)
2、什么是self-attention?
在知道了attention在机器学习中的含义之后(下文都称之为注意力机制)。人为设计的注意力机制,是非常主观的,而且没有一个准则来评定,这个权重设置为多少才好。所以,如何让模型自己对变量的权重进行自赋值成了一个问题,这个权重自赋值的过程也就是self-attention。
https://zhuanlan.zhihu.com/p/619154409
一、Self-Attention是什么?
在理解Self-Attention之前,我们先通俗的解释一下什么是Attention。我们首先看一张图:
我们大部分人第一眼注意到的一定是东方明珠,但是这图其实还有旁边的楼,下面的汽车等等。这其实就是一种Attention,我们关注的是最主要的东西,而刻意“忽视”那些次要的东西。
我们再来讲解一个重要的概念,即query、key和value。这三个词翻译成中文就是查询、键、值,看到这中文的意思,还是迷迷糊糊的。我们来举个例子:小明想在b站搜索深度学习,他把深度学习四个字输入到搜索栏,按下搜索键。搜索引擎就会将他的查询query映射到数据库中相关的标签key,如吴恩达、神经网络等等,然后向小明展示最匹配的结果value。
最后我们来说说Self-Attention。和Attention类似,他们都是一种注意力机制。不同的是Attention是source对target,输入的source和输出的target内容不同。例如英译中,输入英文,输出中文。而Self-Attention是source对source,是source内部元素之间或者target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的注意力机制。

训练和推理 对应的 输入 和 输出?
在Transformer模型架构中,训练阶段和预测阶段(也称为推理阶段)对应的输入和输出是有所不同的。以下是对这两个阶段输入和输出的详细解释:
训练阶段
输入
- 源序列(Source Sequence):
- 这是模型的主要输入,包含源语言的句子或文本序列。在机器翻译任务中,源序列即为需要被翻译的原文。
- 源序列首先会经过词嵌入层(Embedding Layer)和位置编码层(Positional Encoding Layer),将文本转换为模型可以处理的数值形式。
- 目标序列前缀(Target Sequence Prefix):
- 在训练过程中,目标序列(即源序列的翻译结果或任务目标输出)会被分成两部分:前缀部分和剩余部分。前缀部分作为解码器(Decoder)的输入,而剩余部分则用于与解码器的输出进行比较,以计算损失并更新模型参数。
- 例如,在机器翻译任务中,如果目标序列是“I am a student”,则前缀部分可能是“<start> I am a”,剩余部分是“student”。
输出
- 预测的目标序列:
- 解码器基于源序列和目标序列前缀生成预测的目标序列。在训练阶段,这个预测的目标序列会与真实的目标序列剩余部分进行比较,以计算损失。
- 损失通常通过某种形式的损失函数(如交叉熵损失)来计算,用于评估模型预测的准确性。
预测阶段(推理阶段)
输入
- 源序列(Source Sequence):
- 与训练阶段相同,预测阶段的输入也包含源序列。
- 源序列同样会经过词嵌入层和位置编码层,以转换为模型可以处理的数值形式。
- 解码器初始输入:
- 在预测阶段,由于没有真实的目标序列前缀作为输入,解码器通常以一个特殊的起始标记(如“<start>”)作为初始输入。
输出
- 生成的目标序列:
- 解码器基于源序列和自身的初始输入(起始标记),逐步生成目标序列的单词。
- 在每个时间步,解码器都会基于当前的输入(包括已生成的目标序列前缀和源序列的编码表示)来预测下一个单词。
- 这个过程会一直持续到生成结束标记(如“<end>”)或达到预设的最大序列长度。
总结
训练阶段 预测阶段(推理阶段) 输入 1. 源序列 <br> 2. 目标序列前缀 1. 源序列 <br> 2. 解码器初始输入(起始标记) 输出 预测的目标序列(与真实目标序列剩余部分比较以计算损失) 生成的目标序列(无真实目标序列进行比较)
需要注意的是,在训练阶段,模型通过比较预测的目标序列和真实目标序列剩余部分来更新模型参数,以提高预测的准确性。而在预测阶段,模型则基于已学习的参数和源序列来生成目标序列,无需真实目标序列的参与。
https://www.zhihu.com/question/337886108/answer/2865094314
2. Transformer 整体结构
- transformer是由谷歌在同样大名鼎鼎的论文《Attention Is All You Need》提出的,最基础的结构就是先Enoder编码再Decoder解码
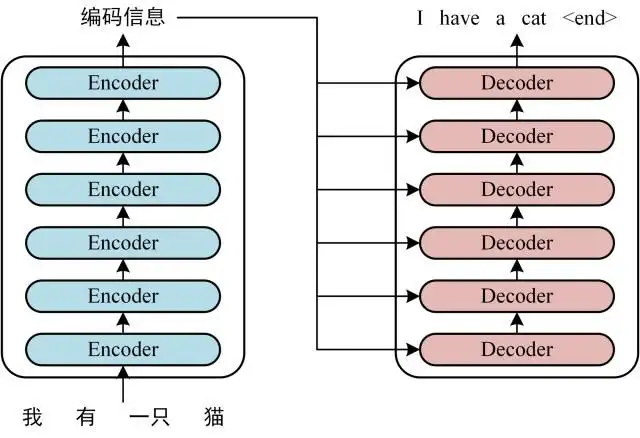
- 首先介绍 Transformer 的整体结构,下图是 Transformer 用于中英文翻译的整体结构:
- 可以看到 Transformer 由 Encoder 和 Decoder 两个部分组成,Encoder 和 Decoder 都包含 6 个 block。Transformer 的工作流程大体如下:
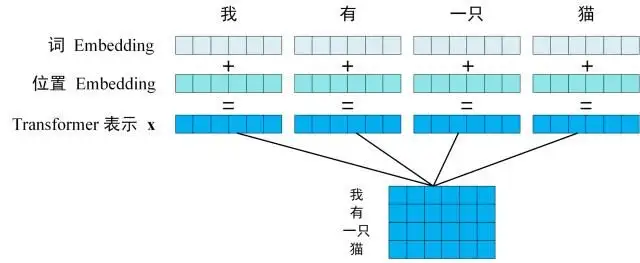
- 第一步:获取输入句子的每一个单词的表示向量 X
- X由单词的 Embedding(Embedding就是从原始数据提取出来的Feature) 和单词位置的 Embedding 相加得到。
- 从上图可以看到,这个句子中是由单词组成的,每一个字都可以映射为一个内容Embedding以及一个位置Embedding,然后将这个内容Embedding和位置Embedding加起来,就可以得到这个词的综合Embedding了。
- 如上图所示,每一行是一个单词的表示 x
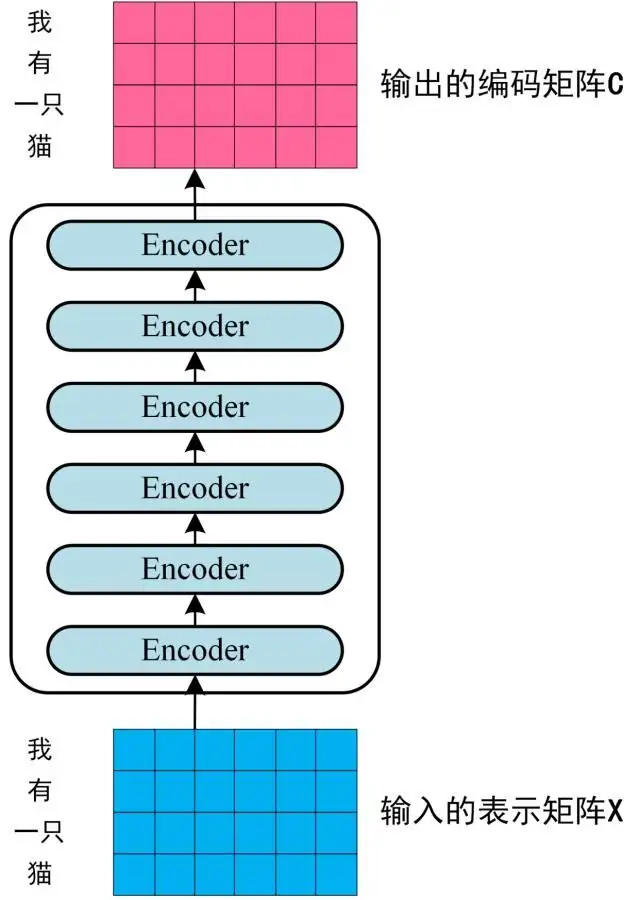
- 第二步:将得到的单词表示向量矩阵 传入 Encoder
- 每一行是一个单词的表示 x,经过 6 个 Encoder block 后可以得到句子所有单词的编码信息矩阵 C,如下图。单词向量矩阵用X_nxd表示,n 是句子中单词个数,d 是表示向量的维度 (论文中 d=512)。每一个 Encoder block 输出的矩阵维度与输入 完全一致。
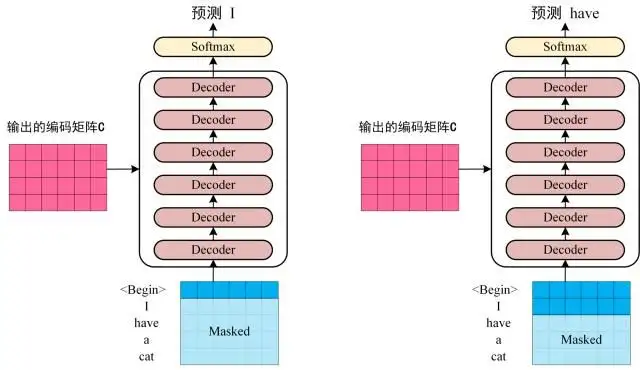
- 第三步:将 Encoder 输出的编码信息矩阵 C传递到 Decoder 中
- Decoder 依次会根据当前已经翻译过的单词 i(I) 翻译下一个单词 i+1(have),如下图所示。在使用的过程中,翻译到单词 i+1 的时候需要通过 Mask (掩盖) 操作遮盖住 i+1 之后的单词。
- 上图 Decoder 接收了 Encoder 的编码矩阵 C,然后首先输入一个翻译开始符 "",预测第一个单词 "I";然后输入翻译开始符 "" 和单词 "I",预测单词 "have",下一次预测的时候,用之前预测的结果作为输入,再得到对应的输出,以此类推。这是 Transformer 使用时候的大致流程,无论再复杂的网络都是这个流程。
- 简单来理解的话,就是通过前I-1个词来预测第i个词,之后一直循环反复这个过程,直到预测出来了 结束符 截止。
3. 名词解释
3.1. token
- 在计算机科学中,token(符号)通常指代文本中的一组字符,它们被视为一个独立的单元,在进行文本分析
- 在自然语言处理中,token 通常指代单词、词组或其他文本中独立的语言单元。将文本分解为 token 的过程称为 tokenization
张量, 它的最后一维将称作词向量等.
- (分词),是自然语言处理中的一个重要预处理步骤,为后续的文本分析和处理提供了基础。
- 一般情况下,对于英文来说,有几个单词就可以认为是有几个token
- 例如,对于英文句子 "I love natural language processing",分词后得到的 token 序列为 ["I", "love", "natural", "language", "processing"]。
- 中文没有像英文那样明确的单词边界,因此需要对中文文本进行分词才能进行后续的文本分析和处理。
- 例如,对于中文句子 "我喜欢自然语言处理",分词后得到的 token 序列为 ["我", "喜欢", "自然语言", "处理"]。其中,“自然语言”是一个词组,在分词时被视为一个整体的 token。
- 在接下来的架构分析中, 我们将假设使用Transformer模型架构处理从一种语言文本到另一种语言文本的翻译工作, 因此很多命名方式遵循NLP中的规则. 比如: Embeddding层将称作文本嵌入层, Embedding层产生的张量称为词嵌入
https://blog.csdn.net/weixin_47129891/article/details/139878475
Transformer模型的输入可以分为训练阶段和推理阶段,在不同阶段输入的内容是不同的。
一、训练阶段的输入
在训练阶段,Transformer模型的输入通常包括以下几部分:
1. 源序列(Source Sequence, X
)
这是模型的主要输入,包括源语言的句子或文本序列。例如,在机器翻译任务中,源序列是要翻译的原文。
2. 目标序列(Target Sequence, Y
)
这是模型在训练时使用的真实目标序列,包括目标语言的句子或文本序列。在机器翻译任务中,目标序列是源序列的翻译结果。
3. 目标序列的前缀(Target Sequence Prefix, Y
)
在训练过程中,目标序列会被分成两个部分:目标序列的前缀部分(即真实目标序列的前一部分)和目标序列的下一部分。目标序列的前缀部分用于解码器的输入。例如,对于目标序列 "I am a student" ,其前缀部分可能是 "\<start> I am a" ,下一部分是 "I am a student"。
二、训练过程的输入细节
在训练过程中,输入的目标序列会被偏移一位,用于教学信号。具体步骤如下:
1.编码器输入
源序列 X
经过词嵌入层和位置编码,输入到编码器。
2. 解码器输入
目标序列的前缀 Y
经过词嵌入层和位置编码,输入到解码器。
三、推理阶段的输入
在推理阶段,模型的输入有所不同,因为目标序列的真实值不可用,模型需要一步一步地生成目标序列:
1. 源序列(Source Sequence, X
)
与训练阶段相同,推理阶段的源序列是模型的输入。
2.解码器输入
解码器的输入在每一步是已生成的目标序列前缀(初始化时是特殊的起始标记 \<start> )。随着生成过程的进行,生成的单词会逐步被添加到解码器输入中。
四、推理过程的输入细节
在推理过程中,生成过程是逐步进行的:
1. 编码器输入
源序列 X
经过词嵌入层和位置编码,输入到编码器,并生成编码器输出。
2.解码器输入
解码器在每个时间步接收已生成的序列,并基于编码器输出和自身状态生成下一个单词。这个过程一直持续到生成结束标记(\<end>)或达到最大长度。
五、输入处理的总结
1. 训练阶段
源序列 X
目标序列前缀 Y
2.推理阶段
源序列 X
动态生成的目标序列前缀(初始为 \<start>,然后逐步扩展)六、示例
假设源序列 X
为 "How are you?",目标序列 Y
为 "Comment ça va?"。
1.训练阶段
源序列: "How are you?"
目标序列前缀: "\<start> Comment ça"
目标序列: "Comment ça va?"2.推理阶段
源序列: "How are you?"
初始解码器输入: "\<start>"
生成过程: "\<start> Comment", "\<start> Comment ça", "\<start> Comment ça va", "Comment ça va \<end>"这种设计使得Transformer模型能够在训练时学习如何将源序列翻译成目标序列,并在推理时逐步生成目标序列。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号